 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASHEW: Stabilizing Multimodal Reasoning via Iterative Trajectory Aggregation
Jan 12, 2026Vision-language models achieve strong performance across a wide range of multimodal understanding and reasoning tasks, yet their multi-step reasoning remains unstable. Repeated sampling over the same input often produces divergent reasoning trajectories and inconsistent final predictions. To address this, we introduce two complementary approaches inspired by test-time scaling: (1) CASHEW, an inference-time framework that stabilizes reasoning by iteratively aggregating multiple candidate trajectories into higher-quality reasoning traces, with explicit visual verification filtering hallucinated steps and grounding reasoning in visual evidence, and (2) CASHEW-RL, a learned variant that internalizes this aggregation behavior within a single model. CASHEW-RL is trained using Group Sequence Policy Optimization (GSPO) with a composite reward that encourages correct answers grounded in minimal yet sufficient visual evidence, while adaptively allocating reasoning effort based on task difficulty. This training objective enables robust self-aggregation at inference. Extensive experiments on 13 image understanding, video understanding, and video reasoning benchmarks show significant performance improvements, including gains of up to +23.6 percentage points on ScienceQA and +8.1 percentage points on EgoSchema.
Redefinition of Digital Twin and its Situation Awareness Framework Designing Towards Fourth Paradigm for Energy Internet of Things
Jul 12, 2024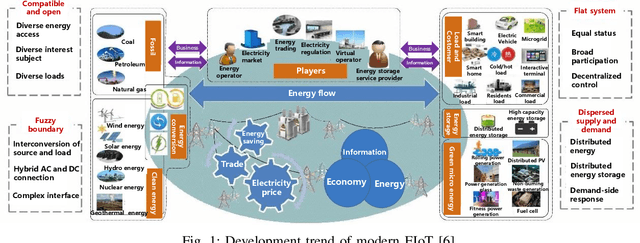


Traditional knowledge-based situation awareness (SA) modes struggle to adapt to the escalating complexity of today's Energy Internet of Things (EIoT), necessitating a pivotal paradigm shift. In response, this work introduces a pioneering data-driven SA framework, termed digital twin-based situation awareness (DT-SA), aiming to bridge existing gaps between data and demands, and further to enhance SA capabilities within the complex EIoT landscape. First, we redefine the concept of digital twin (DT) within the EIoT context, aligning it with data-intensive scientific discovery paradigm (the Fourth Paradigm) so as to waken EIoT's sleeping data; this contextual redefinition lays the cornerstone of our DT-SA framework for EIoT. Then, the framework is comprehensively explored through its four fundamental steps: digitalization, simulation, informatization, and intellectualization. These steps initiate a virtual ecosystem conducive to a continuously self-adaptive, self-learning, and self-evolving big model (BM), further contributing to the evolution and effectiveness of DT-SA in engineering. Our framework is characterized by the incorporation of system theory and Fourth Paradigm as guiding ideologies, DT as data engine, and BM as intelligence engine. This unique combination forms the backbone of our approach. This work extends beyond engineering, stepping into the domain of data science -- DT-SA not only enhances management practices for EIoT users/operators, but also propels advancements in pattern analysis and machine intelligence (PAMI) within the intricate fabric of a complex system. Numerous real-world cases validate our DT-SA framework.
Generative manufacturing systems using diffusion models and ChatGPT
May 02, 2024



In this study, we introduce Generative Manufacturing Systems (GMS) as a novel approach to effectively manage and coordinate autonomous manufacturing assets, thereby enhancing their responsiveness and flexibility to address a wide array of production objectives and human preferences. Deviating from traditional explicit modeling, GMS employs generative AI, including diffusion models and ChatGPT, for implicit learning from envisioned futures, marking a shift from a model-optimum to a training-sampling decision-making. Through the integration of generative AI, GMS enables complex decision-making through interactive dialogue with humans, allowing manufacturing assets to generate multiple high-quality global decisions that can be iteratively refined based on human feedback. Empirical findings showcase GMS's substantial improvement in system resilience and responsiveness to uncertainties, with decision times reduced from seconds to milliseconds. The study underscores the inherent creativity and diversity in the generated solutions, facilitating human-centric decision-making through seamless and continuous human-machine interactions.
Short Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020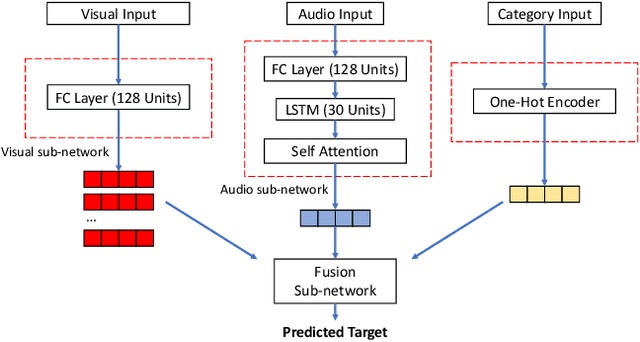
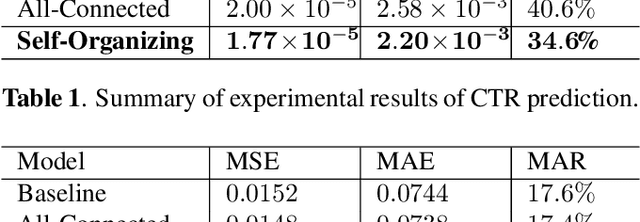
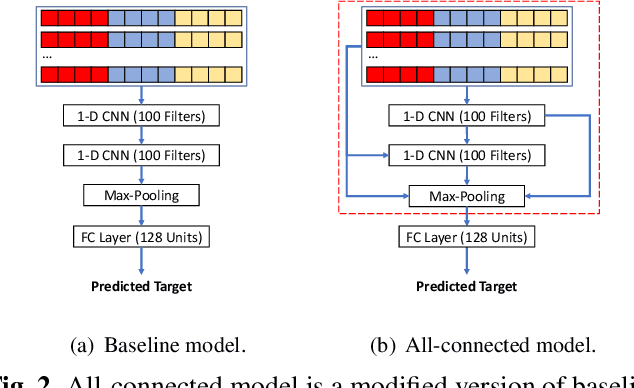
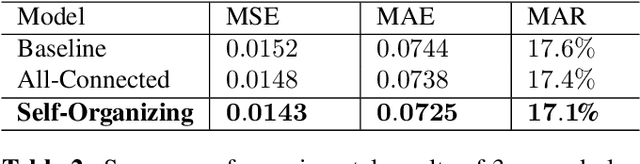
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.
Ensemble Chinese End-to-End Spoken Language Understanding for Abnormal Event Detection from audio stream
Oct 19, 2020
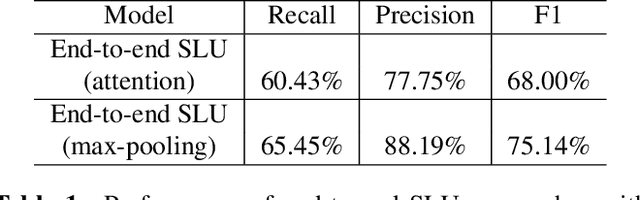

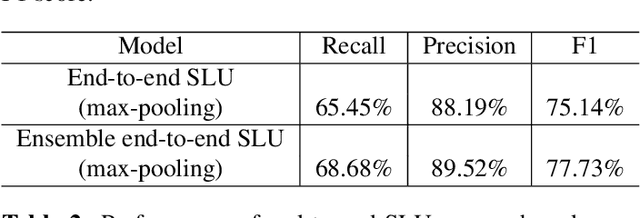
Conventional spoken language understanding (SLU) consist of two stages, the first stage maps speech to text by automatic speech recognition (ASR), and the second stage maps text to intent by natural language understanding (NLU). End-to-end SLU maps speech directly to intent through a single deep learning model. Previous end-to-end SLU models are primarily used for English environment due to lacking large scale SLU dataset in Chines, and use only one ASR model to extract features from speech. With the help of Kuaishou technology, a large scale SLU dataset in Chinese is collected to detect abnormal event in their live audio stream. Based on this dataset, this paper proposed a ensemble end-to-end SLU model used for Chinese environment. This ensemble SLU models extracted hierarchies features using multiple pre-trained ASR models, leading to better representation of phoneme level and word level information. This proposed approached achieve 9.7% increase of accuracy compared to previous end-to-end SLU model.
Themes Inferred Audio-visual Correspondence Learning
Sep 14, 2020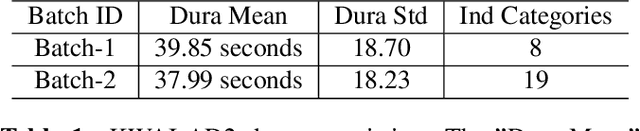
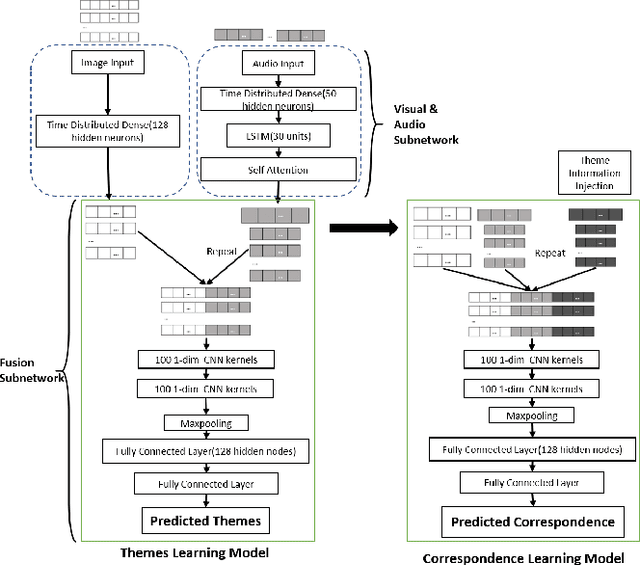
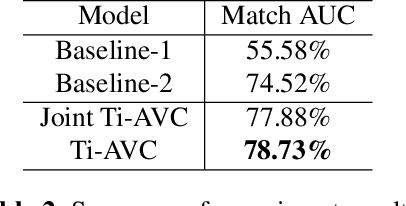
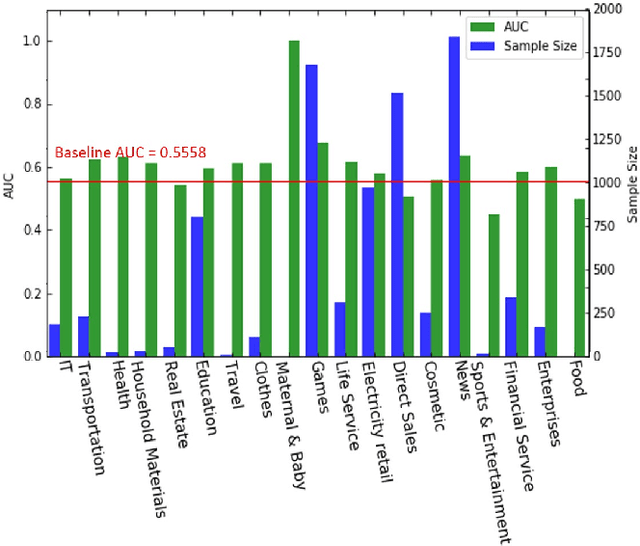
The applications of short-termuser generated video(UGV),such as snapchat, youtube short-term videos, booms recently,raising lots of multimodal machine learning tasks. Amongthem, learning the correspondence between audio and vi-sual information from videos is a challenging one. Mostprevious work of theaudio-visual correspondence(AVC)learning only investigated on constrained videos or simplesettings, which may not fit the application of UGV. In thispaper, we proposed new principles for AVC and introduced anew framework to set sight on the themes of videos to facili-tate AVC learning. We also released the KWAI-AD-AudViscorpus which contained 85432 short advertisement videos(around 913 hours) made by users. We evaluated our pro-posed approach on this corpus and it was able to outperformthe baseline by 23.15% absolute differenc
Improving Embedding Extraction for Speaker Verification with Ladder Network
Mar 20, 2020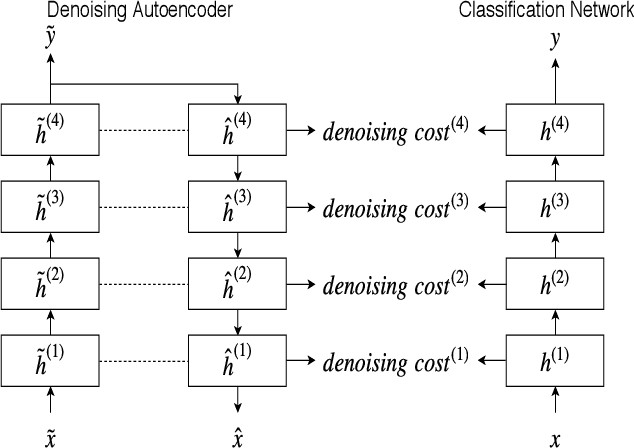
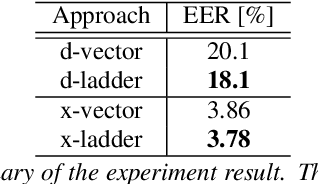
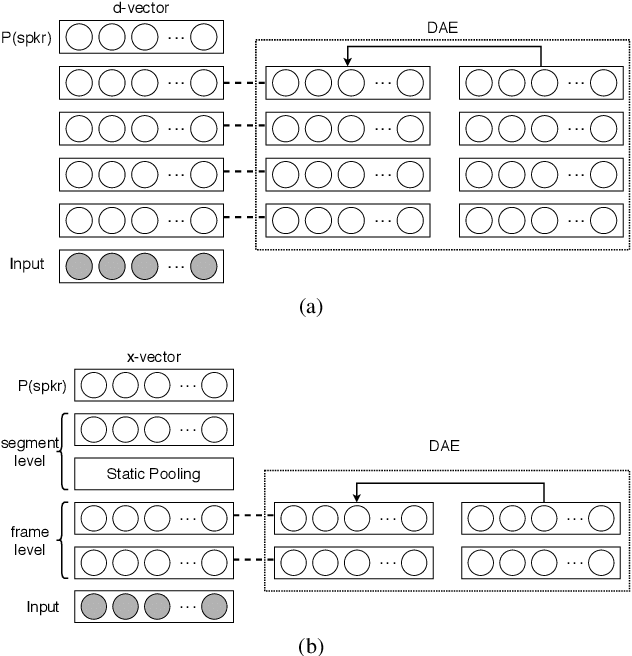
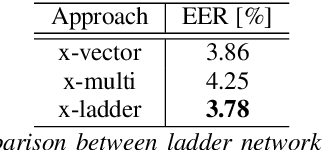
Speaker verification is an established yet challenging task in speech processing and a very vibrant research area. Recent speaker verification (SV) systems rely on deep neural networks to extract high-level embeddings which are able to characterize the users' voices. Most of the studies have investigated on improving the discriminability of the networks to extract better embeddings for performances improvement. However, only few research focus on improving the generalization. In this paper, we propose to apply the ladder network framework in the SV systems, which combines the supervised and unsupervised learning fashions. The ladder network can make the system to have better high-level embedding by balancing the trade-off to keep/discard as much useful/useless information as possible. We evaluated the framework on two state-of-the-art SV systems, d-vector and x-vector, which can be used for different use cases. The experiments showed that the proposed approach relatively improved the performance by 10% at most without adding parameters and augmented data.
Multi-Task Siamese Neural Network for Improving Replay Attack Detection
Feb 16, 2020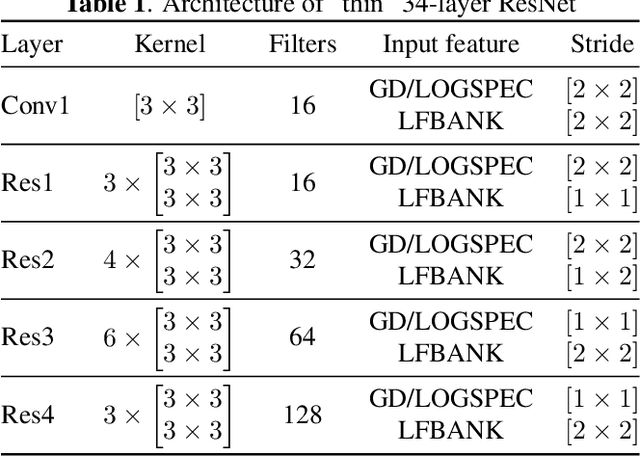
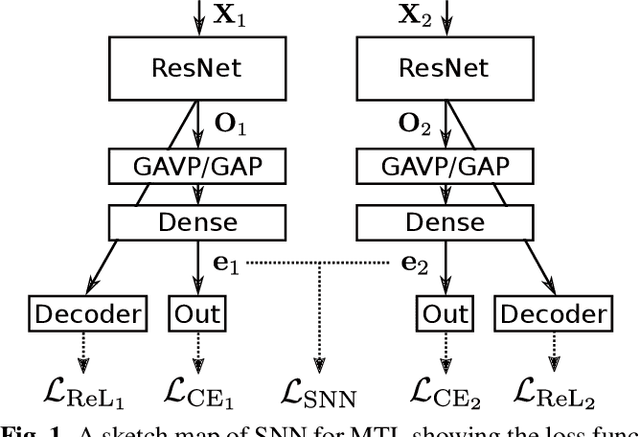
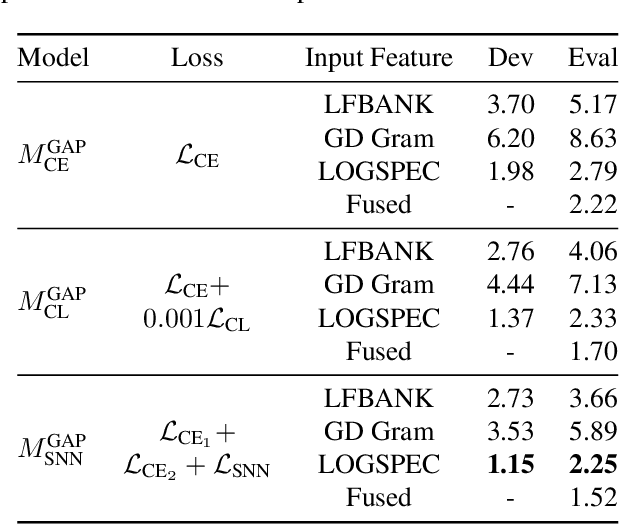
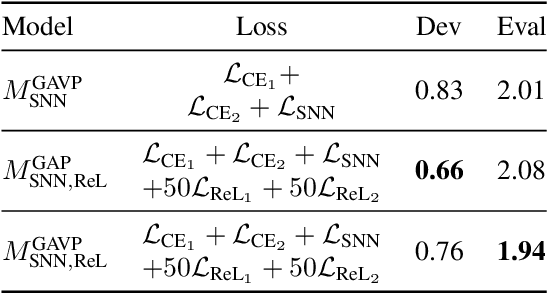
Automatic speaker verification systems are vulnerable to audio replay attacks which bypass security by replaying recordings of authorized speakers. Replay attack detection (RA) detection systems built upon Residual Neural Networks (ResNet)s have yielded astonishing results on the public benchmark ASVspoof 2019 Physical Access challenge. With most teams using fine-tuned feature extraction pipelines and model architectures, the generalizability of such systems remains questionable though. In this work, we analyse the effect of discriminative feature learning in a multi-task learning (MTL) setting can have on the generalizability and discriminability of RA detection systems. We use a popular ResNet architecture optimized by the cross-entropy criterion as our baseline and compare it to the same architecture optimized by MTL using Siamese Neural Networks (SNN). It can be shown that SNN outperform the baseline by relative 26.8 % Equal Error Rate (EER). We further enhance the model's architecture and demonstrate that SNN with additional reconstruction loss yield another significant improvement of relative 13.8 % EER.
End-to-end Audiovisual Speech Activity Detection with Bimodal Recurrent Neural Models
Sep 12, 2018
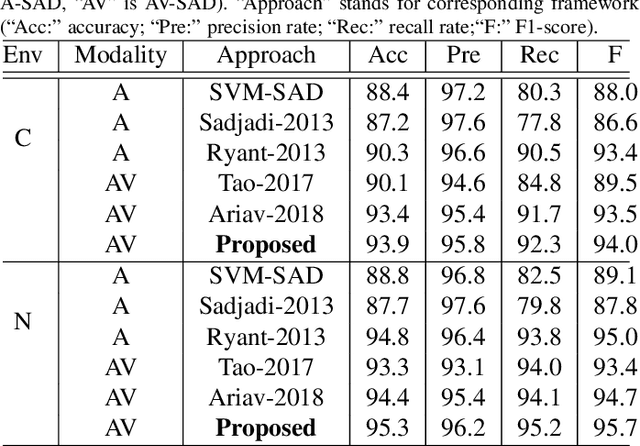
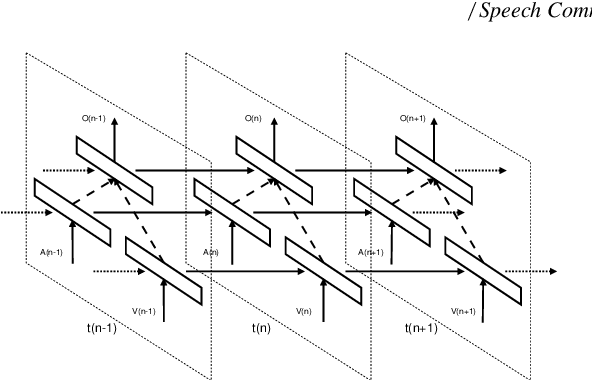
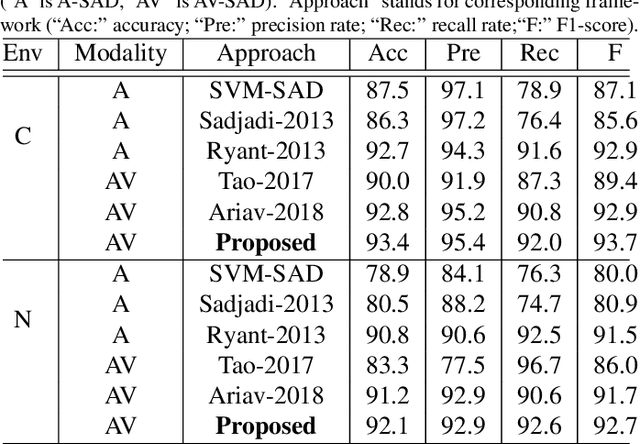
Speech activity detection (SAD) plays an important role in current speech processing systems, including automatic speech recognition (ASR). SAD is particularly difficult in environments with acoustic noise. A practical solution is to incorporate visual information, increasing the robustness of the SAD approach. An audiovisual system has the advantage of being robust to different speech modes (e.g., whisper speech) or background noise. Recent advances in audiovisual speech processing using deep learning have opened opportunities to capture in a principled way the temporal relationships between acoustic and visual features. This study explores this idea proposing a \emph{bimodal recurrent neural network} (BRNN) framework for SAD. The approach models the temporal dynamic of the sequential audiovisual data, improving the accuracy and robustness of the proposed SAD system. Instead of estimating hand-crafted features, the study investigates an end-to-end training approach, where acoustic and visual features are directly learned from the raw data during training. The experimental evaluation considers a large audiovisual corpus with over 60.8 hours of recordings, collected from 105 speakers. The results demonstrate that the proposed framework leads to absolute improvements up to 1.2% under practical scenarios over a VAD baseline using only audio implemented with deep neural network (DNN). The proposed approach achieves 92.7% F1-score when it is evaluated using the sensors from a portable tablet under noisy acoustic environment, which is only 1.0% lower than the performance obtained under ideal conditions (e.g., clean speech obtained with a high definition camera and a close-talking microphone).
Advanced LSTM: A Study about Better Time Dependency Modeling in Emotion Recognition
Oct 27, 2017
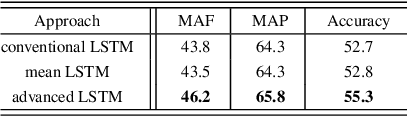
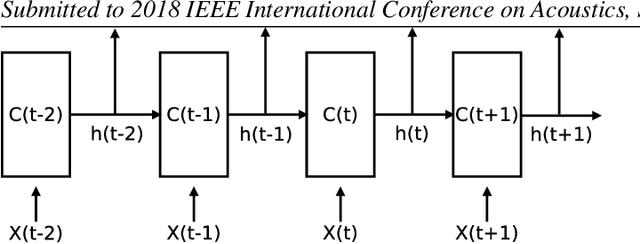

Long short-term memory (LSTM) is normally used in recurrent neural network (RNN) as basic recurrent unit. However,conventional LSTM assumes that the state at current time step depends on previous time step. This assumption constraints the time dependency modeling capability. In this study, we propose a new variation of LSTM, advanced LSTM (A-LSTM), for better temporal context modeling. We employ A-LSTM in weighted pooling RNN for emotion recognition. The A-LSTM outperforms the conventional LSTM by 5.5% relatively. The A-LSTM based weighted pooling RNN can also complement the state-of-the-art emotion classification framework. This shows the advantage of A-LSTM.