 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Audiovisual Speech Activity Detection with Bimodal Recurrent Neural Models
Paper and Code
Sep 12, 2018
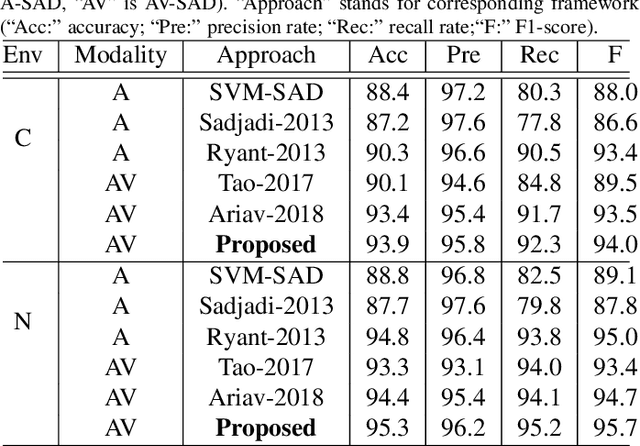
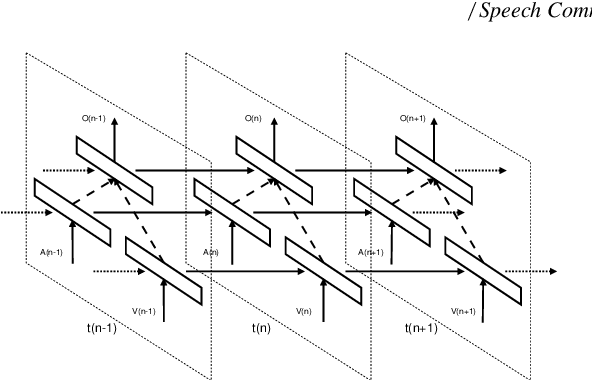
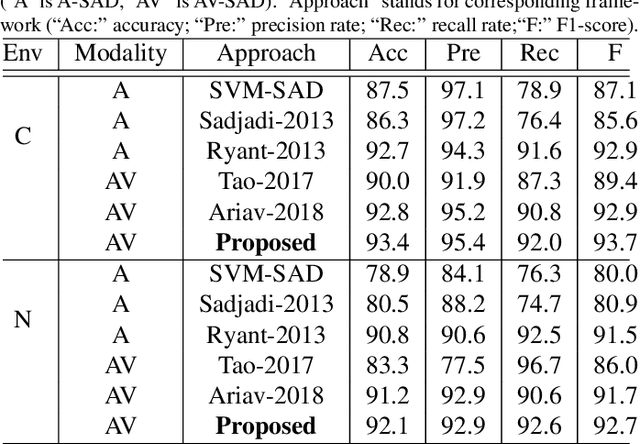
Speech activity detection (SAD) plays an important role in current speech processing systems, including automatic speech recognition (ASR). SAD is particularly difficult in environments with acoustic noise. A practical solution is to incorporate visual information, increasing the robustness of the SAD approach. An audiovisual system has the advantage of being robust to different speech modes (e.g., whisper speech) or background noise. Recent advances in audiovisual speech processing using deep learning have opened opportunities to capture in a principled way the temporal relationships between acoustic and visual features. This study explores this idea proposing a \emph{bimodal recurrent neural network} (BRNN) framework for SAD. The approach models the temporal dynamic of the sequential audiovisual data, improving the accuracy and robustness of the proposed SAD system. Instead of estimating hand-crafted features, the study investigates an end-to-end training approach, where acoustic and visual features are directly learned from the raw data during training. The experimental evaluation considers a large audiovisual corpus with over 60.8 hours of recordings, collected from 105 speakers. The results demonstrate that the proposed framework leads to absolute improvements up to 1.2% under practical scenarios over a VAD baseline using only audio implemented with deep neural network (DNN). The proposed approach achieves 92.7% F1-score when it is evaluated using the sensors from a portable tablet under noisy acoustic environment, which is only 1.0% lower than the performance obtained under ideal conditions (e.g., clean speech obtained with a high definition camera and a close-talking microphone).