 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Embedding Extraction for Speaker Verification with Ladder Network
Paper and Code
Mar 20, 2020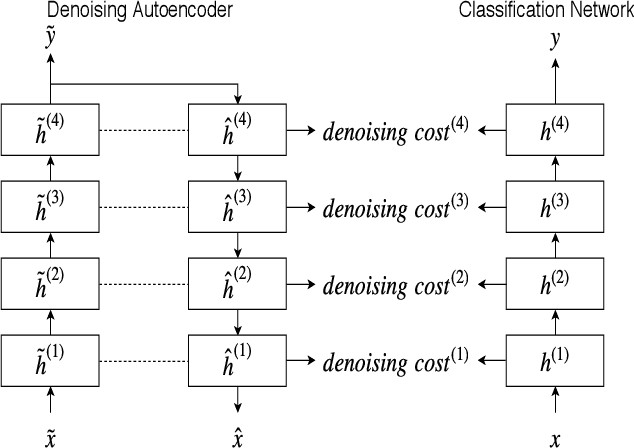
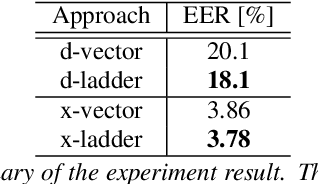
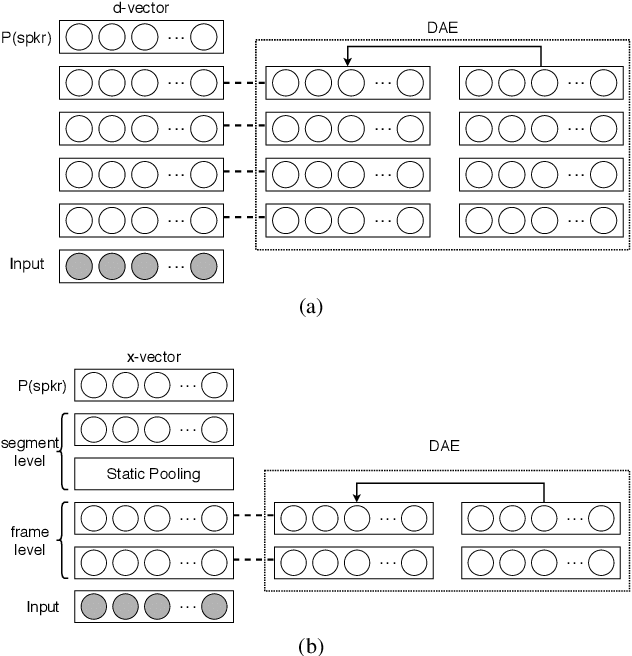
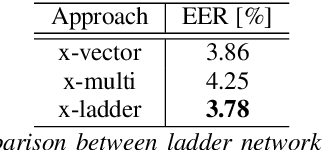
Speaker verification is an established yet challenging task in speech processing and a very vibrant research area. Recent speaker verification (SV) systems rely on deep neural networks to extract high-level embeddings which are able to characterize the users' voices. Most of the studies have investigated on improving the discriminability of the networks to extract better embeddings for performances improvement. However, only few research focus on improving the generalization. In this paper, we propose to apply the ladder network framework in the SV systems, which combines the supervised and unsupervised learning fashions. The ladder network can make the system to have better high-level embedding by balancing the trade-off to keep/discard as much useful/useless information as possible. We evaluated the framework on two state-of-the-art SV systems, d-vector and x-vector, which can be used for different use cases. The experiments showed that the proposed approach relatively improved the performance by 10% at most without adding parameters and augmented data.