 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefinition of Digital Twin and its Situation Awareness Framework Designing Towards Fourth Paradigm for Energy Internet of Things
Jul 12, 2024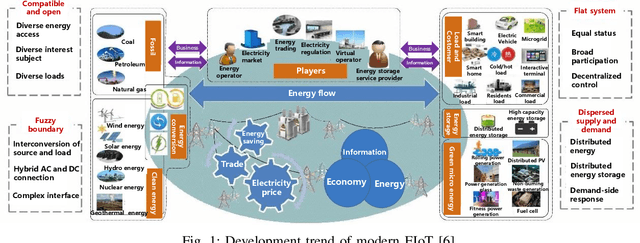


Traditional knowledge-based situation awareness (SA) modes struggle to adapt to the escalating complexity of today's Energy Internet of Things (EIoT), necessitating a pivotal paradigm shift. In response, this work introduces a pioneering data-driven SA framework, termed digital twin-based situation awareness (DT-SA), aiming to bridge existing gaps between data and demands, and further to enhance SA capabilities within the complex EIoT landscape. First, we redefine the concept of digital twin (DT) within the EIoT context, aligning it with data-intensive scientific discovery paradigm (the Fourth Paradigm) so as to waken EIoT's sleeping data; this contextual redefinition lays the cornerstone of our DT-SA framework for EIoT. Then, the framework is comprehensively explored through its four fundamental steps: digitalization, simulation, informatization, and intellectualization. These steps initiate a virtual ecosystem conducive to a continuously self-adaptive, self-learning, and self-evolving big model (BM), further contributing to the evolution and effectiveness of DT-SA in engineering. Our framework is characterized by the incorporation of system theory and Fourth Paradigm as guiding ideologies, DT as data engine, and BM as intelligence engine. This unique combination forms the backbone of our approach. This work extends beyond engineering, stepping into the domain of data science -- DT-SA not only enhances management practices for EIoT users/operators, but also propels advancements in pattern analysis and machine intelligence (PAMI) within the intricate fabric of a complex system. Numerous real-world cases validate our DT-SA framework.
Optimal Adaptive Prediction Intervals for Electricity Load Forecasting in Distribution Systems via Reinforcement Learning
May 18, 2022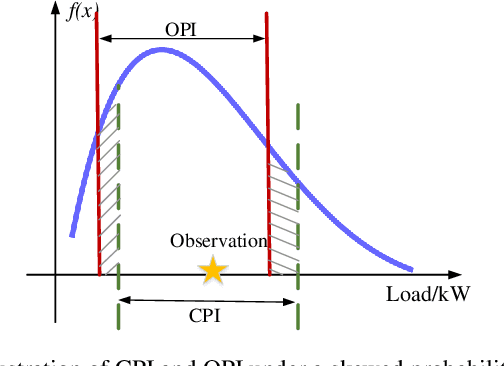
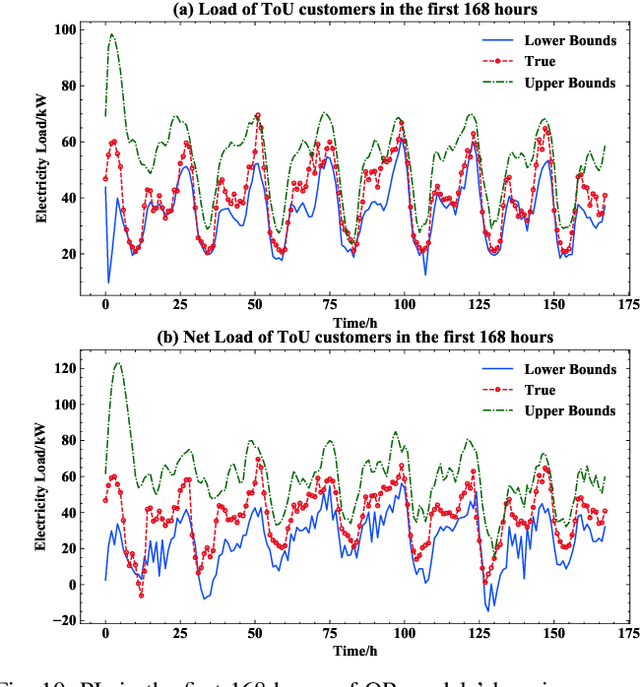

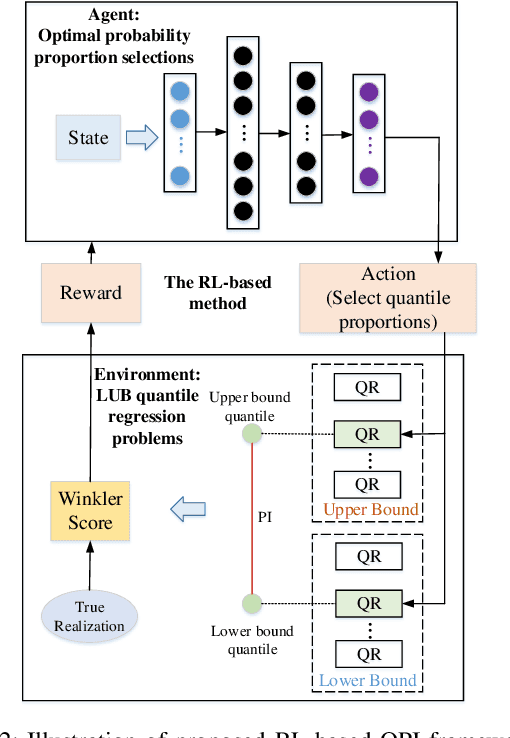
Prediction intervals offer an effective tool for quantifying the uncertainty of loads in distribution systems. The traditional central PIs cannot adapt well to skewed distributions, and their offline training fashion is vulnerable to unforeseen changes in future load patterns. Therefore, we propose an optimal PI estimation approach, which is online and adaptive to different data distributions by adaptively determining symmetric or asymmetric probability proportion pairs for quantiles. It relies on the online learning ability of reinforcement learning to integrate the two online tasks, i.e., the adaptive selection of probability proportion pairs and quantile predictions, both of which are modeled by neural networks. As such, the quality of quantiles-formed PI can guide the selection process of optimal probability proportion pairs, which forms a closed loop to improve the quality of PIs. Furthermore, to improve the learning efficiency of quantile forecasts, a prioritized experience replay strategy is proposed for online quantile regression processes. Case studies on both load and net load demonstrate that the proposed method can better adapt to data distribution compared with online central PIs method. Compared with offline-trained methods, it obtains PIs with better quality and is more robust against concept drift.
A Random Matrix Theoretical Approach to Early Event Detection in Smart Grid
Sep 15, 2015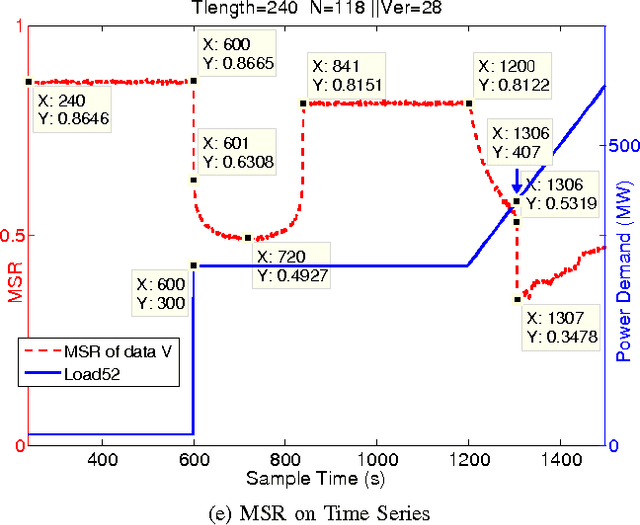
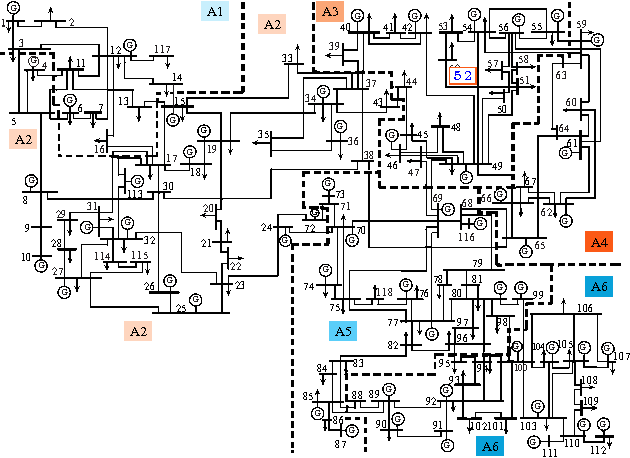
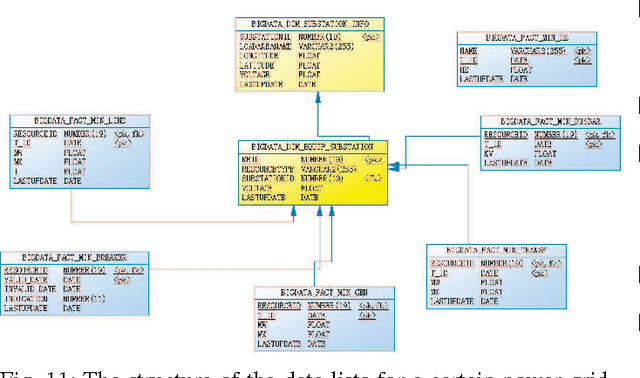
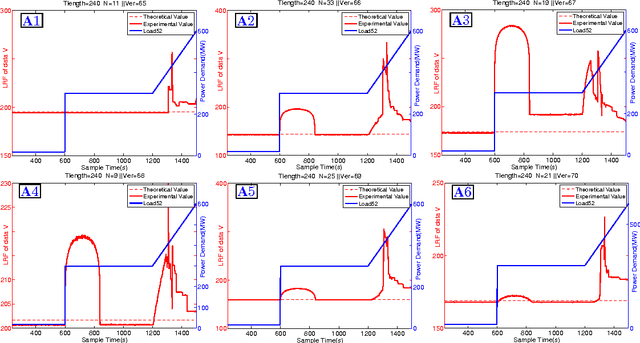
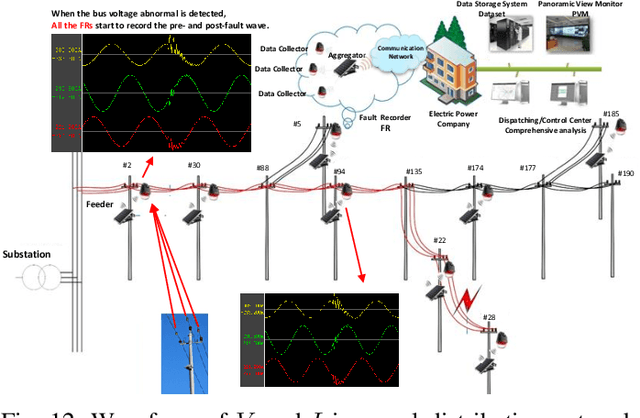
Power systems are developing very fast nowadays, both in size and in complexity; this situation is a challenge for Early Event Detection (EED). This paper proposes a data- driven unsupervised learning method to handle this challenge. Specifically, the random matrix theories (RMTs) are introduced as the statistical foundations for random matrix models (RMMs); based on the RMMs, linear eigenvalue statistics (LESs) are defined via the test functions as the system indicators. By comparing the values of the LES between the experimental and the theoretical ones, the anomaly detection is conducted. Furthermore, we develop 3D power-map to visualize the LES; it provides a robust auxiliary decision-making mechanism to the operators. In this sense, the proposed method conducts EED with a pure statistical procedure, requiring no knowledge of system topologies, unit operation/control models, etc. The LES, as a key ingredient during this procedure, is a high dimensional indictor derived directly from raw data. As an unsupervised learning indicator, the LES is much more sensitive than the low dimensional indictors obtained from supervised learning. With the statistical procedure, the proposed method is universal and fast; moreover, it is robust against traditional EED challenges (such as error accumulations, spurious correlations, and even bad data in core area). Case studies, with both simulated data and real ones, validate the proposed method. To manage large-scale distributed systems, data fusion is mentioned as another data processing ingredient.