 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020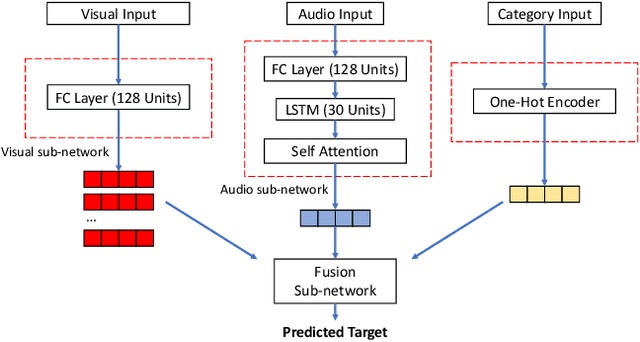
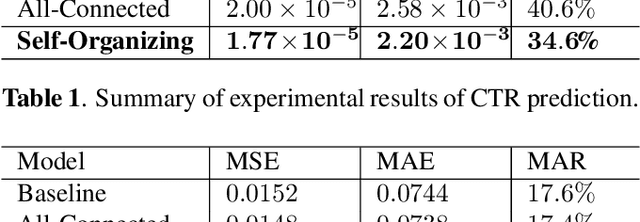
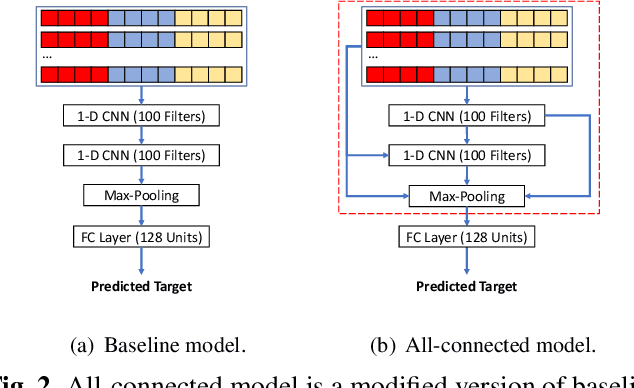
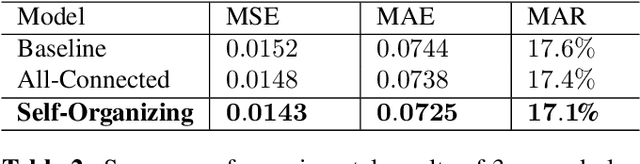
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.
Themes Inferred Audio-visual Correspondence Learning
Sep 14, 2020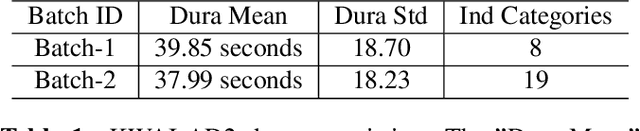
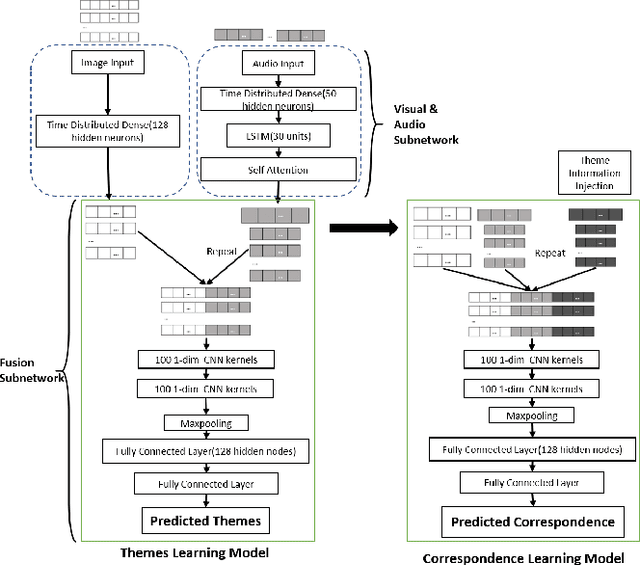
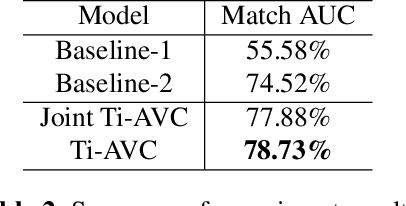
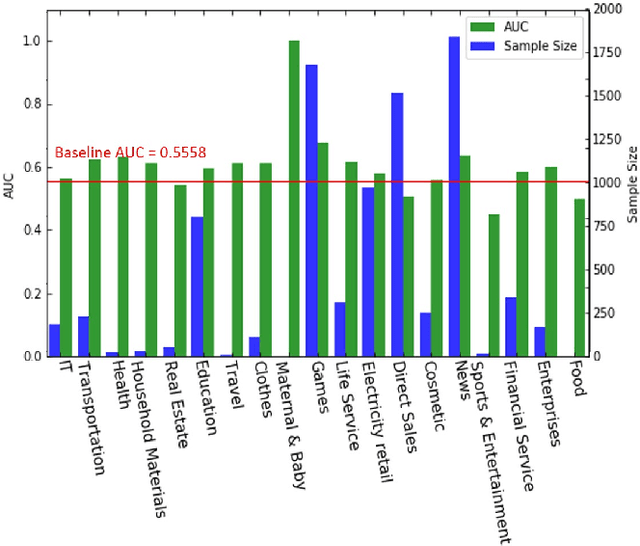
The applications of short-termuser generated video(UGV),such as snapchat, youtube short-term videos, booms recently,raising lots of multimodal machine learning tasks. Amongthem, learning the correspondence between audio and vi-sual information from videos is a challenging one. Mostprevious work of theaudio-visual correspondence(AVC)learning only investigated on constrained videos or simplesettings, which may not fit the application of UGV. In thispaper, we proposed new principles for AVC and introduced anew framework to set sight on the themes of videos to facili-tate AVC learning. We also released the KWAI-AD-AudViscorpus which contained 85432 short advertisement videos(around 913 hours) made by users. We evaluated our pro-posed approach on this corpus and it was able to outperformthe baseline by 23.15% absolute differenc