 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNecessary and Sufficient Conditions and a Provably Efficient Algorithm for Separable Topic Discovery
Paper and Code
Dec 04, 2015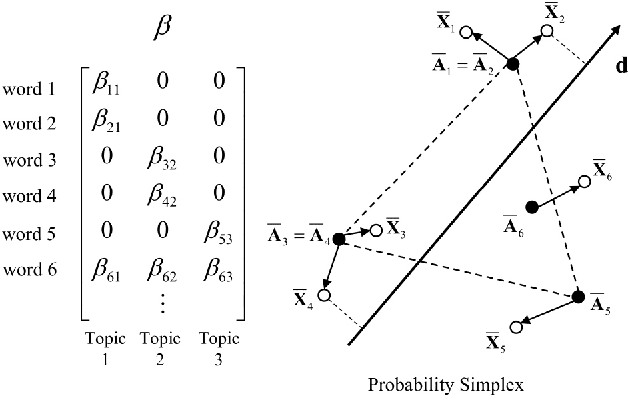
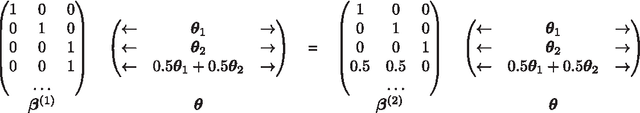
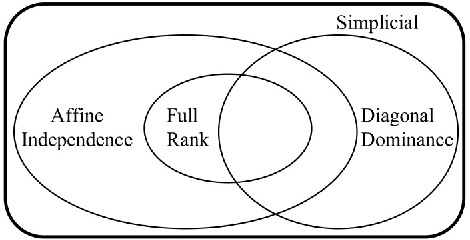
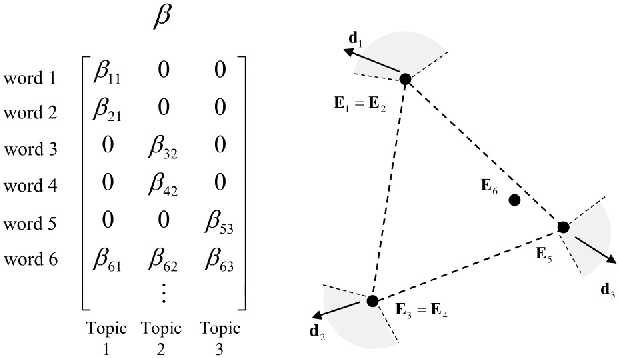
We develop necessary and sufficient conditions and a novel provably consistent and efficient algorithm for discovering topics (latent factors) from observations (documents) that are realized from a probabilistic mixture of shared latent factors that have certain properties. Our focus is on the class of topic models in which each shared latent factor contains a novel word that is unique to that factor, a property that has come to be known as separability. Our algorithm is based on the key insight that the novel words correspond to the extreme points of the convex hull formed by the row-vectors of a suitably normalized word co-occurrence matrix. We leverage this geometric insight to establish polynomial computation and sample complexity bounds based on a few isotropic random projections of the rows of the normalized word co-occurrence matrix. Our proposed random-projections-based algorithm is naturally amenable to an efficient distributed implementation and is attractive for modern web-scale distributed data mining applications.