 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Quality Assessment of 3D Gaussian Splatting: A Subjective Dataset and Prediction Metric
Nov 11, 2025
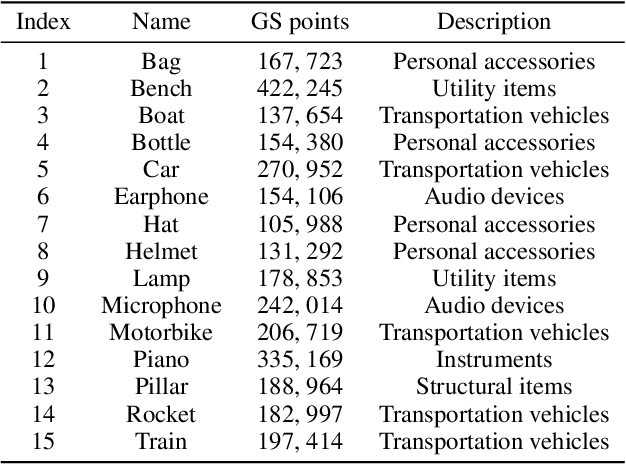
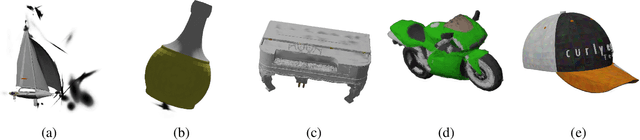
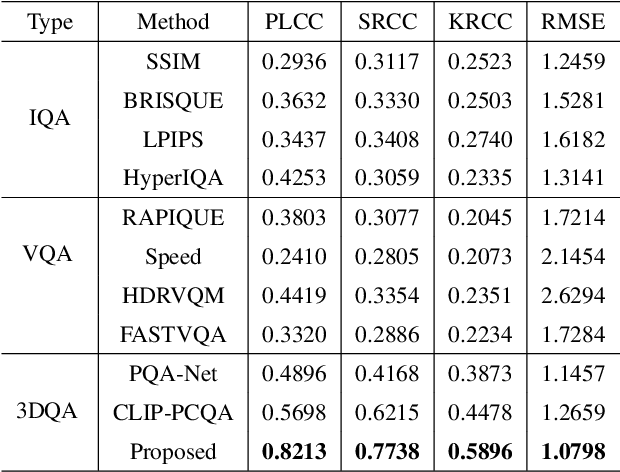
With the rapid advancement of 3D visualization, 3D Gaussian Splatting (3DGS) has emerged as a leading technique for real-time, high-fidelity rendering. While prior research has emphasized algorithmic performance and visual fidelity, the perceptual quality of 3DGS-rendered content, especially under varying reconstruction conditions, remains largely underexplored. In practice, factors such as viewpoint sparsity, limited training iterations, point downsampling, noise, and color distortions can significantly degrade visual quality, yet their perceptual impact has not been systematically studied. To bridge this gap, we present 3DGS-QA, the first subjective quality assessment dataset for 3DGS. It comprises 225 degraded reconstructions across 15 object types, enabling a controlled investigation of common distortion factors. Based on this dataset, we introduce a no-reference quality prediction model that directly operates on native 3D Gaussian primitives, without requiring rendered images or ground-truth references. Our model extracts spatial and photometric cues from the Gaussian representation to estimate perceived quality in a structure-aware manner. We further benchmark existing quality assessment methods, spanning both traditional and learning-based approaches. Experimental results show that our method consistently achieves superior performance, highlighting its robustness and effectiveness for 3DGS content evaluation. The dataset and code are made publicly available at https://github.com/diaoyn/3DGSQA to facilitate future research in 3DGS quality assessment.
MDIQA: Unified Image Quality Assessment for Multi-dimensional Evaluation and Restoration
Aug 23, 2025



Recent advancements in image quality assessment (IQA), driven by sophisticated deep neural network designs, have significantly improved the ability to approach human perceptions. However, most existing methods are obsessed with fitting the overall score, neglecting the fact that humans typically evaluate image quality from different dimensions before arriving at an overall quality assessment. To overcome this problem, we propose a multi-dimensional image quality assessment (MDIQA) framework. Specifically, we model image quality across various perceptual dimensions, including five technical and four aesthetic dimensions, to capture the multifaceted nature of human visual perception within distinct branches. Each branch of our MDIQA is initially trained under the guidance of a separate dimension, and the respective features are then amalgamated to generate the final IQA score. Additionally, when the MDIQA model is ready, we can deploy it for a flexible training of image restoration (IR) models, enabling the restoration results to better align with varying user preferences through the adjustment of perceptual dimension weights. Extensive experiments demonstrate that our MDIQA achieves superior performance and can be effectively and flexibly applied to image restoration tasks. The code is available: https://github.com/YaoShunyu19/MDIQA.
A Self-adaptive Neuroevolution Approach to Constructing Deep Neural Network Architectures Across Different Types
Nov 30, 2022Neuroevolution has greatly promoted Deep Neural Network (DNN) architecture design and its applications, while there is a lack of methods available across different DNN types concerning both their scale and performance. In this study, we propose a self-adaptive neuroevolution (SANE) approach to automatically construct various lightweight DNN architectures for different tasks. One of the key settings in SANE is the search space defined by cells and organs self-adapted to different DNN types. Based on this search space, a constructive evolution strategy with uniform evolution settings and operations is designed to grow DNN architectures gradually. SANE is able to self-adaptively adjust evolution exploration and exploitation to improve search efficiency. Moreover, a speciation scheme is developed to protect evolution from early convergence by restricting selection competition within species. To evaluate SANE, we carry out neuroevolution experiments to generate different DNN architectures including convolutional neural network, generative adversarial network and long short-term memory. The results illustrate that the obtained DNN architectures could have smaller scale with similar performance compared to existing DNN architectures. Our proposed SANE provides an efficient approach to self-adaptively search DNN architectures across different types.
Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment
Apr 19, 2022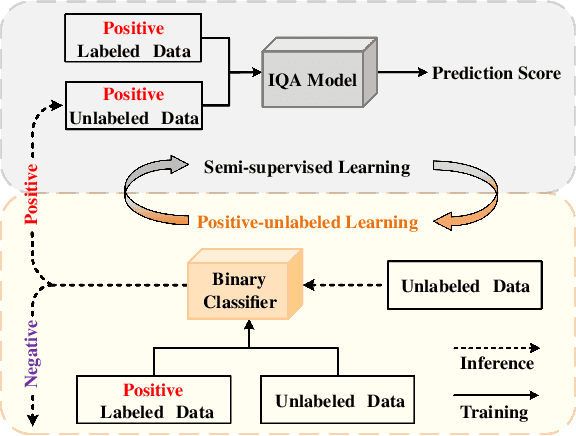
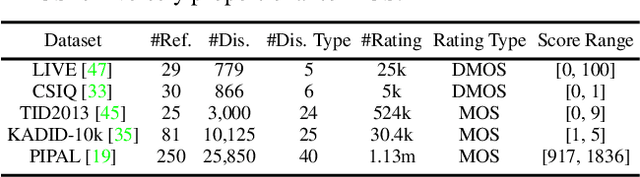
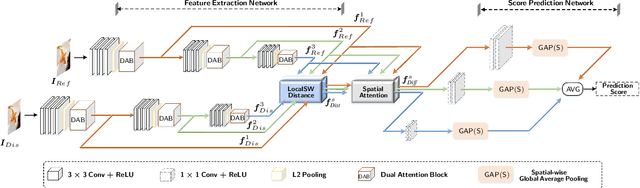
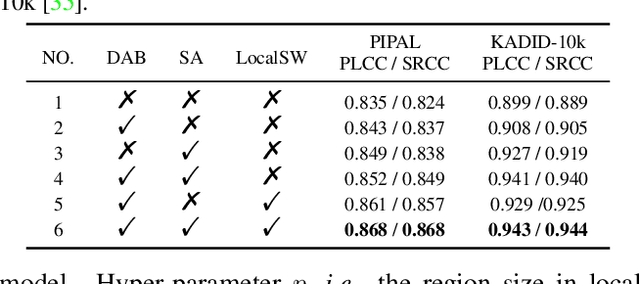
Full-reference (FR) image quality assessment (IQA) evaluates the visual quality of a distorted image by measuring its perceptual difference with pristine-quality reference, and has been widely used in low-level vision tasks. Pairwise labeled data with mean opinion score (MOS) are required in training FR-IQA model, but is time-consuming and cumbersome to collect. In contrast, unlabeled data can be easily collected from an image degradation or restoration process, making it encouraging to exploit unlabeled training data to boost FR-IQA performance. Moreover, due to the distribution inconsistency between labeled and unlabeled data, outliers may occur in unlabeled data, further increasing the training difficulty. In this paper, we suggest to incorporate semi-supervised and positive-unlabeled (PU) learning for exploiting unlabeled data while mitigating the adverse effect of outliers. Particularly, by treating all labeled data as positive samples, PU learning is leveraged to identify negative samples (i.e., outliers) from unlabeled data. Semi-supervised learning (SSL) is further deployed to exploit positive unlabeled data by dynamically generating pseudo-MOS. We adopt a dual-branch network including reference and distortion branches. Furthermore, spatial attention is introduced in the reference branch to concentrate more on the informative regions, and sliced Wasserstein distance is used for robust difference map computation to address the misalignment issues caused by images recovered by GAN models. Extensive experiments show that our method performs favorably against state-of-the-arts on the benchmark datasets PIPAL, KADID-10k, TID2013, LIVE and CSIQ.