 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOT-Occ: Sparse Prototype-guided Transformer for Camera-based 3D Occupancy Prediction
Feb 04, 2026Achieving highly accurate and real-time 3D occupancy prediction from cameras is a critical requirement for the safe and practical deployment of autonomous vehicles. While this shift to sparse 3D representations solves the encoding bottleneck, it creates a new challenge for the decoder: how to efficiently aggregate information from a sparse, non-uniformly distributed set of voxel features without resorting to computationally prohibitive dense attention. In this paper, we propose a novel Prototype-based Sparse Transformer Decoder that replaces this costly interaction with an efficient, two-stage process of guided feature selection and focused aggregation. Our core idea is to make the decoder's attention prototype-guided. We achieve this through a sparse prototype selection mechanism, where each query adaptively identifies a compact set of the most salient voxel features, termed prototypes, for focused feature aggregation. To ensure this dynamic selection is stable and effective, we introduce a complementary denoising paradigm. This approach leverages ground-truth masks to provide explicit guidance, guaranteeing a consistent query-prototype association across decoder layers. Our model, dubbed SPOT-Occ, outperforms previous methods with a significant margin in speed while also improving accuracy. Source code is released at https://github.com/chensuzeyu/SpotOcc.
OmniBooth: Learning Latent Control for Image Synthesis with Multi-modal Instruction
Oct 07, 2024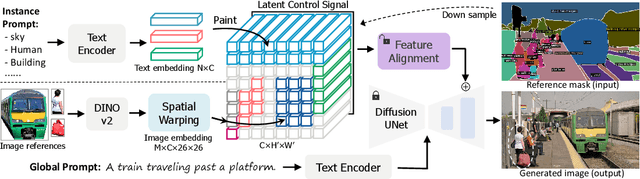
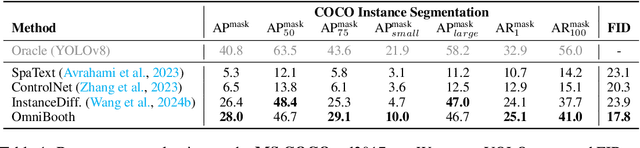
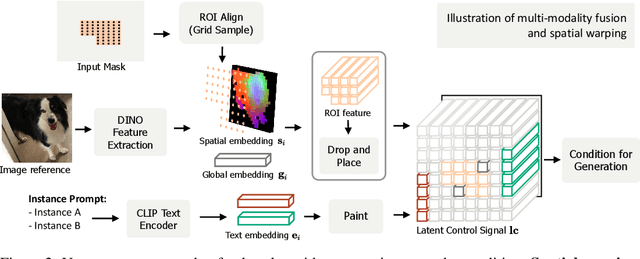
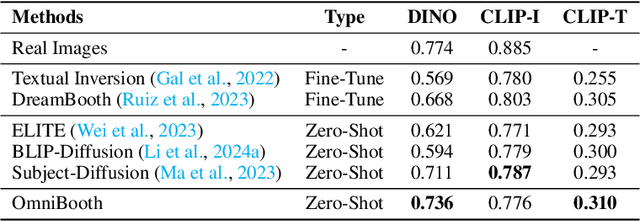
We present OmniBooth, an image generation framework that enables spatial control with instance-level multi-modal customization. For all instances, the multimodal instruction can be described through text prompts or image references. Given a set of user-defined masks and associated text or image guidance, our objective is to generate an image, where multiple objects are positioned at specified coordinates and their attributes are precisely aligned with the corresponding guidance. This approach significantly expands the scope of text-to-image generation, and elevates it to a more versatile and practical dimension in controllability. In this paper, our core contribution lies in the proposed latent control signals, a high-dimensional spatial feature that provides a unified representation to integrate the spatial, textual, and image conditions seamlessly. The text condition extends ControlNet to provide instance-level open-vocabulary generation. The image condition further enables fine-grained control with personalized identity. In practice, our method empowers users with more flexibility in controllable generation, as users can choose multi-modal conditions from text or images as needed. Furthermore, thorough experiments demonstrate our enhanced performance in image synthesis fidelity and alignment across different tasks and datasets. Project page: https://len-li.github.io/omnibooth-web/
Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Sep 26, 2024



Leveraging the visual priors of pre-trained text-to-image diffusion models offers a promising solution to enhance zero-shot generalization in dense prediction tasks. However, existing methods often uncritically use the original diffusion formulation, which may not be optimal due to the fundamental differences between dense prediction and image generation. In this paper, we provide a systemic analysis of the diffusion formulation for the dense prediction, focusing on both quality and efficiency. And we find that the original parameterization type for image generation, which learns to predict noise, is harmful for dense prediction; the multi-step noising/denoising diffusion process is also unnecessary and challenging to optimize. Based on these insights, we introduce Lotus, a diffusion-based visual foundation model with a simple yet effective adaptation protocol for dense prediction. Specifically, Lotus is trained to directly predict annotations instead of noise, thereby avoiding harmful variance. We also reformulate the diffusion process into a single-step procedure, simplifying optimization and significantly boosting inference speed. Additionally, we introduce a novel tuning strategy called detail preserver, which achieves more accurate and fine-grained predictions. Without scaling up the training data or model capacity, Lotus achieves SoTA performance in zero-shot depth and normal estimation across various datasets. It also significantly enhances efficiency, being hundreds of times faster than most existing diffusion-based methods.
Neural Radiance Field in Autonomous Driving: A Survey
Apr 26, 2024



Neural Radiance Field (NeRF) has garnered significant attention from both academia and industry due to its intrinsic advantages, particularly its implicit representation and novel view synthesis capabilities. With the rapid advancements in deep learning, a multitude of methods have emerged to explore the potential applications of NeRF in the domain of Autonomous Driving (AD). However, a conspicuous void is apparent within the current literature. To bridge this gap, this paper conducts a comprehensive survey of NeRF's applications in the context of AD. Our survey is structured to categorize NeRF's applications in Autonomous Driving (AD), specifically encompassing perception, 3D reconstruction, simultaneous localization and mapping (SLAM), and simulation. We delve into in-depth analysis and summarize the findings for each application category, and conclude by providing insights and discussions on future directions in this field. We hope this paper serves as a comprehensive reference for researchers in this domain. To the best of our knowledge, this is the first survey specifically focused on the applications of NeRF in the Autonomous Driving domain.
Adv3D: Generating 3D Adversarial Examples in Driving Scenarios with NeRF
Sep 04, 2023Deep neural networks (DNNs) have been proven extremely susceptible to adversarial examples, which raises special safety-critical concerns for DNN-based autonomous driving stacks (i.e., 3D object detection). Although there are extensive works on image-level attacks, most are restricted to 2D pixel spaces, and such attacks are not always physically realistic in our 3D world. Here we present Adv3D, the first exploration of modeling adversarial examples as Neural Radiance Fields (NeRFs). Advances in NeRF provide photorealistic appearances and 3D accurate generation, yielding a more realistic and realizable adversarial example. We train our adversarial NeRF by minimizing the surrounding objects' confidence predicted by 3D detectors on the training set. Then we evaluate Adv3D on the unseen validation set and show that it can cause a large performance reduction when rendering NeRF in any sampled pose. To generate physically realizable adversarial examples, we propose primitive-aware sampling and semantic-guided regularization that enable 3D patch attacks with camouflage adversarial texture. Experimental results demonstrate that the trained adversarial NeRF generalizes well to different poses, scenes, and 3D detectors. Finally, we provide a defense method to our attacks that involves adversarial training through data augmentation. Project page: https://len-li.github.io/adv3d-web
Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
Apr 07, 2023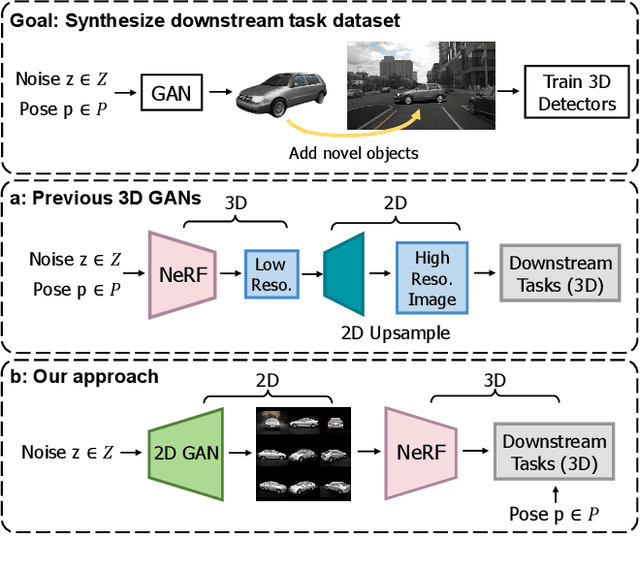
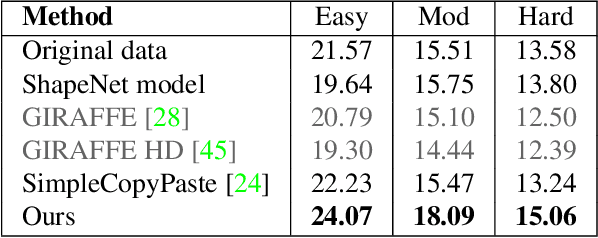
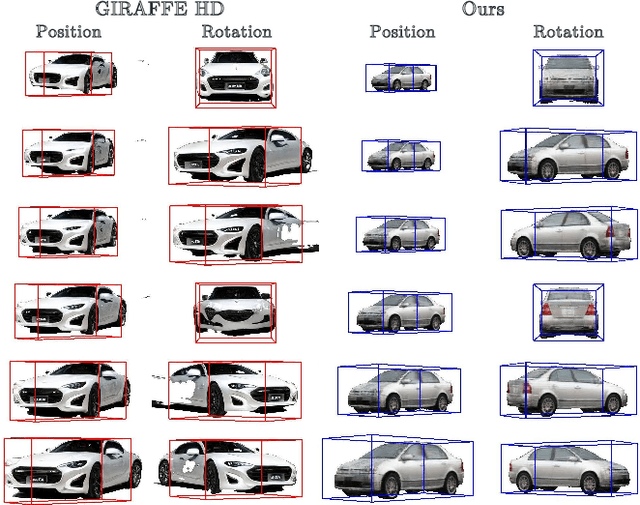

This work explores the use of 3D generative models to synthesize training data for 3D vision tasks. The key requirements of the generative models are that the generated data should be photorealistic to match the real-world scenarios, and the corresponding 3D attributes should be aligned with given sampling labels. However, we find that the recent NeRF-based 3D GANs hardly meet the above requirements due to their designed generation pipeline and the lack of explicit 3D supervision. In this work, we propose Lift3D, an inverted 2D-to-3D generation framework to achieve the data generation objectives. Lift3D has several merits compared to prior methods: (1) Unlike previous 3D GANs that the output resolution is fixed after training, Lift3D can generalize to any camera intrinsic with higher resolution and photorealistic output. (2) By lifting well-disentangled 2D GAN to 3D object NeRF, Lift3D provides explicit 3D information of generated objects, thus offering accurate 3D annotations for downstream tasks. We evaluate the effectiveness of our framework by augmenting autonomous driving datasets. Experimental results demonstrate that our data generation framework can effectively improve the performance of 3D object detectors. Project page: https://len-li.github.io/lift3d-web.