 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseStreet: Sparse Gaussian Splatting for Real-Time Street Scene Simulation
Jun 02, 2026While 3D Gaussian Splatting has shown promising results in street scene reconstruction, existing methods require massive numbers of Gaussian primitives to capture fine details, leading to prohibitive storage costs and slow rendering speeds. We observe that dynamic objects (e.g., vehicles and pedestrians) demand high-fidelity representations to maintain temporal consistency, while static background regions often contain substantial redundancy. Motivated by this, we propose SparseStreet, a general compression framework specifically designed for street scenes. First, we introduce a node-based learnable pruning strategy that systematically removes low-contributing Gaussian primitives while preserving visually critical regions. Second, after the scene representation stabilizes, we apply background compression, further reducing redundancy in static regions. Our method effectively preserves the geometry and appearance of dynamic objects while significantly reducing the total number of Gaussian primitives. Extensive experiments on the Waymo and nuScenes demonstrate that SparseStreet achieves up to 80% compression ratio with minimal quality degradation, enabling resource-efficient, high-fidelity dynamic scene reconstruction. Project website: https://sparsestreet.github.io/.
ManipDreamer: Boosting Robotic Manipulation World Model with Action Tree and Visual Guidance
Apr 23, 2025



While recent advancements in robotic manipulation video synthesis have shown promise, significant challenges persist in ensuring effective instruction-following and achieving high visual quality. Recent methods, like RoboDreamer, utilize linguistic decomposition to divide instructions into separate lower-level primitives, conditioning the world model on these primitives to achieve compositional instruction-following. However, these separate primitives do not consider the relationships that exist between them. Furthermore, recent methods neglect valuable visual guidance, including depth and semantic guidance, both crucial for enhancing visual quality. This paper introduces ManipDreamer, an advanced world model based on the action tree and visual guidance. To better learn the relationships between instruction primitives, we represent the instruction as the action tree and assign embeddings to tree nodes, each instruction can acquire its embeddings by navigating through the action tree. The instruction embeddings can be used to guide the world model. To enhance visual quality, we combine depth and semantic guidance by introducing a visual guidance adapter compatible with the world model. This visual adapter enhances both the temporal and physical consistency of video generation. Based on the action tree and visual guidance, ManipDreamer significantly boosts the instruction-following ability and visual quality. Comprehensive evaluations on robotic manipulation benchmarks reveal that ManipDreamer achieves large improvements in video quality metrics in both seen and unseen tasks, with PSNR improved from 19.55 to 21.05, SSIM improved from 0.7474 to 0.7982 and reduced Flow Error from 3.506 to 3.201 in unseen tasks, compared to the recent RoboDreamer model. Additionally, our method increases the success rate of robotic manipulation tasks by 2.5% in 6 RLbench tasks on average.
Toward Accurate Camera-based 3D Object Detection via Cascade Depth Estimation and Calibration
Feb 07, 2024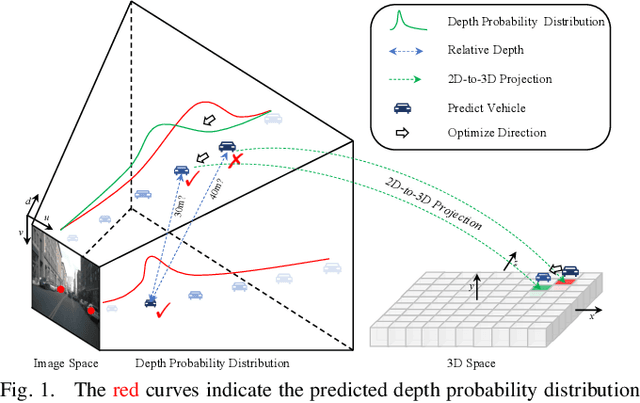
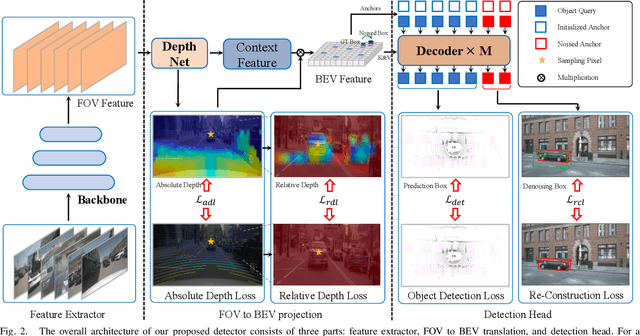
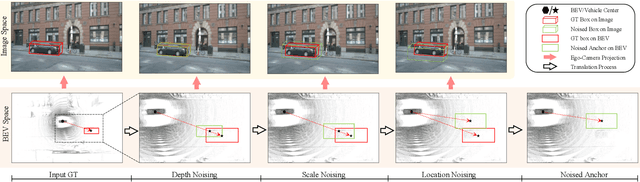
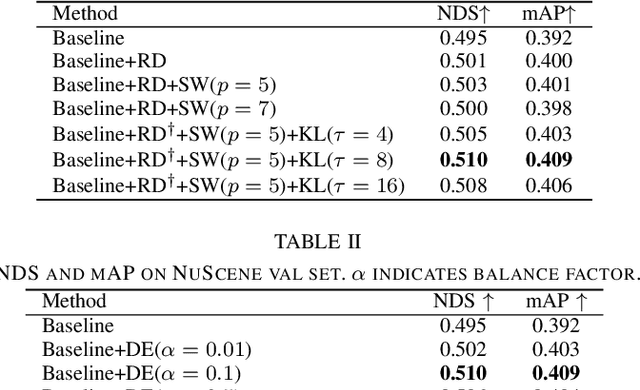
Recent camera-based 3D object detection is limited by the precision of transforming from image to 3D feature spaces, as well as the accuracy of object localization within the 3D space. This paper aims to address such a fundamental problem of camera-based 3D object detection: How to effectively learn depth information for accurate feature lifting and object localization. Different from previous methods which directly predict depth distributions by using a supervised estimation model, we propose a cascade framework consisting of two depth-aware learning paradigms. First, a depth estimation (DE) scheme leverages relative depth information to realize the effective feature lifting from 2D to 3D spaces. Furthermore, a depth calibration (DC) scheme introduces depth reconstruction to further adjust the 3D object localization perturbation along the depth axis. In practice, the DE is explicitly realized by using both the absolute and relative depth optimization loss to promote the precision of depth prediction, while the capability of DC is implicitly embedded into the detection Transformer through a depth denoising mechanism in the training phase. The entire model training is accomplished through an end-to-end manner. We propose a baseline detector and evaluate the effectiveness of our proposal with +2.2%/+2.7% NDS/mAP improvements on NuScenes benchmark, and gain a comparable performance with 55.9%/45.7% NDS/mAP. Furthermore, we conduct extensive experiments to demonstrate its generality based on various detectors with about +2% NDS improvements.
SupFusion: Supervised LiDAR-Camera Fusion for 3D Object Detection
Sep 13, 2023



In this paper, we propose a novel training strategy called SupFusion, which provides an auxiliary feature level supervision for effective LiDAR-Camera fusion and significantly boosts detection performance. Our strategy involves a data enhancement method named Polar Sampling, which densifies sparse objects and trains an assistant model to generate high-quality features as the supervision. These features are then used to train the LiDAR-Camera fusion model, where the fusion feature is optimized to simulate the generated high-quality features. Furthermore, we propose a simple yet effective deep fusion module, which contiguously gains superior performance compared with previous fusion methods with SupFusion strategy. In such a manner, our proposal shares the following advantages. Firstly, SupFusion introduces auxiliary feature-level supervision which could boost LiDAR-Camera detection performance without introducing extra inference costs. Secondly, the proposed deep fusion could continuously improve the detector's abilities. Our proposed SupFusion and deep fusion module is plug-and-play, we make extensive experiments to demonstrate its effectiveness. Specifically, we gain around 2% 3D mAP improvements on KITTI benchmark based on multiple LiDAR-Camera 3D detectors.
Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
Apr 07, 2023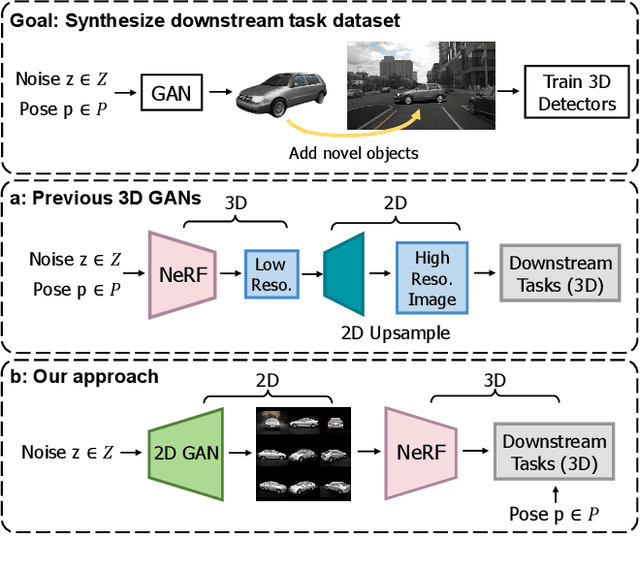
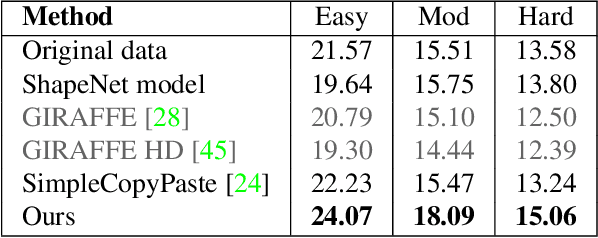
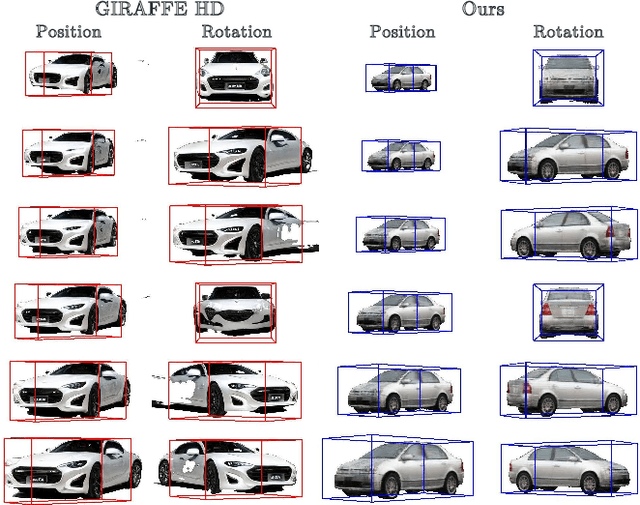

This work explores the use of 3D generative models to synthesize training data for 3D vision tasks. The key requirements of the generative models are that the generated data should be photorealistic to match the real-world scenarios, and the corresponding 3D attributes should be aligned with given sampling labels. However, we find that the recent NeRF-based 3D GANs hardly meet the above requirements due to their designed generation pipeline and the lack of explicit 3D supervision. In this work, we propose Lift3D, an inverted 2D-to-3D generation framework to achieve the data generation objectives. Lift3D has several merits compared to prior methods: (1) Unlike previous 3D GANs that the output resolution is fixed after training, Lift3D can generalize to any camera intrinsic with higher resolution and photorealistic output. (2) By lifting well-disentangled 2D GAN to 3D object NeRF, Lift3D provides explicit 3D information of generated objects, thus offering accurate 3D annotations for downstream tasks. We evaluate the effectiveness of our framework by augmenting autonomous driving datasets. Experimental results demonstrate that our data generation framework can effectively improve the performance of 3D object detectors. Project page: https://len-li.github.io/lift3d-web.
RepVGG: Making VGG-style ConvNets Great Again
Jan 11, 2021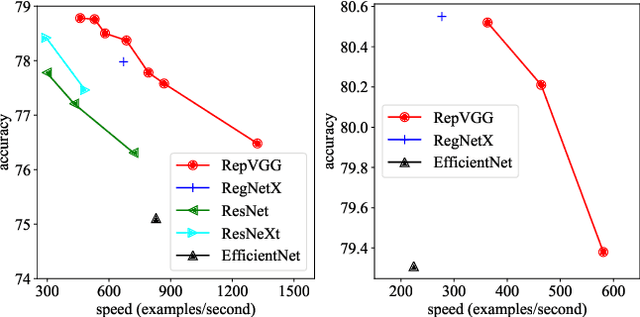
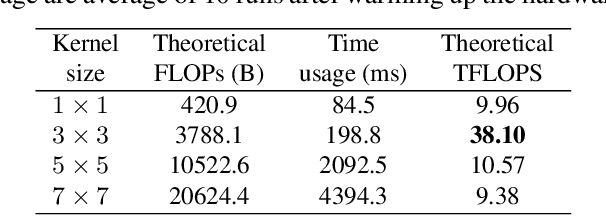
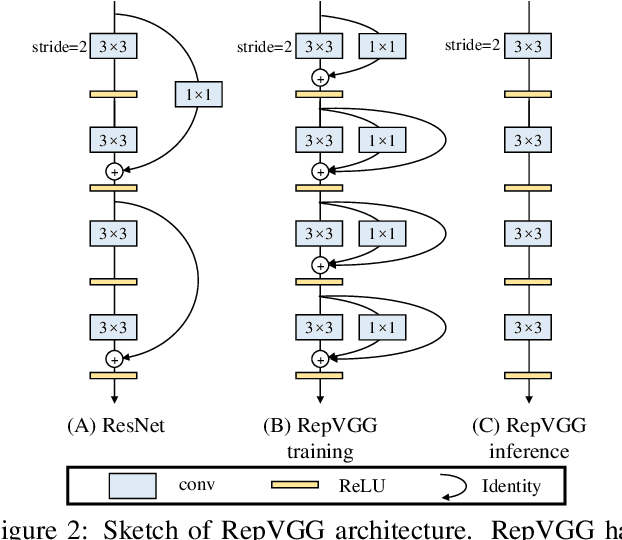

We present a simple but powerful architecture of convolutional neural network, which has a VGG-like inference-time body composed of nothing but a stack of 3x3 convolution and ReLU, while the training-time model has a multi-branch topology. Such decoupling of the training-time and inference-time architecture is realized by a structural re-parameterization technique so that the model is named RepVGG. On ImageNet, RepVGG reaches over 80\% top-1 accuracy, which is the first time for a plain model, to the best of our knowledge. On NVIDIA 1080Ti GPU, RepVGG models run 83% faster than ResNet-50 or 101% faster than ResNet-101 with higher accuracy and show favorable accuracy-speed trade-off compared to the state-of-the-art models like EfficientNet and RegNet. The code and trained models are available at https://github.com/megvii-model/RepVGG.
Activate or Not: Learning Customized Activation
Sep 10, 2020


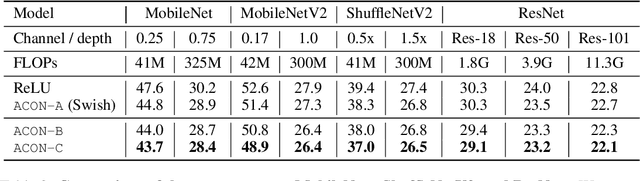
Modern activation layers use non-linear functions to activate the neurons. In this paper, we present a simple but effective activation function we term ACON which learns to activate the neurons or not. Surprisingly, we find Swish, the recent popular NAS-searched activation, can be interpreted as a smooth approximation to ReLU. Intuitively, in the same way, we approximate the variants in the ReLU family to the Swish family, we call ACON, which makes Swish a special case of ACON and remarkably improves the performance. Next, we present meta-ACON, which explicitly learns to optimize the parameter switching between non-linear (activate) and linear (inactivate) and provides a new design space. By simply changing the activation function, we improve the ImageNet top-1 accuracy rate by 6.7% and 1.8% on MobileNet-0.25 and ResNet-152, respectively.
WeightNet: Revisiting the Design Space of Weight Networks
Jul 24, 2020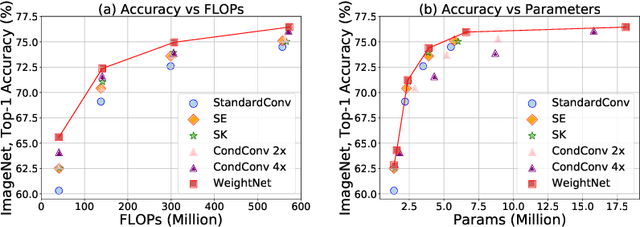
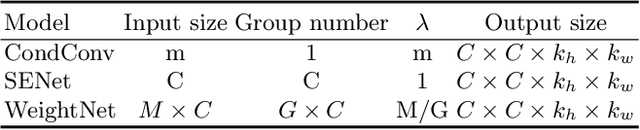
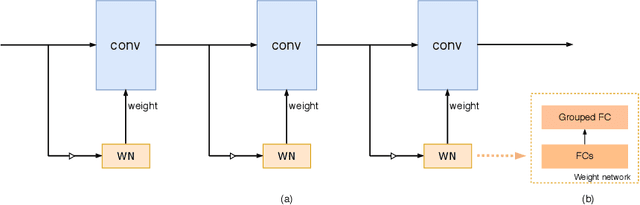
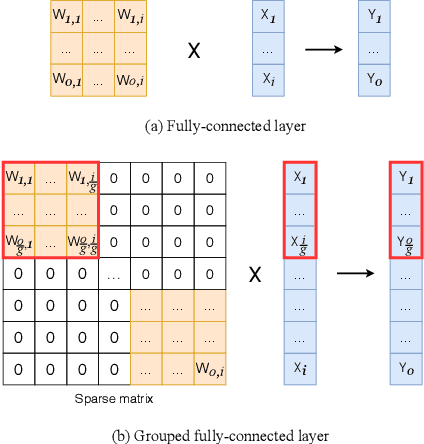
We present a conceptually simple, flexible and effective framework for weight generating networks. Our approach is general that unifies two current distinct and extremely effective SENet and CondConv into the same framework on weight space. The method, called WeightNet, generalizes the two methods by simply adding one more grouped fully-connected layer to the attention activation layer. We use the WeightNet, composed entirely of (grouped) fully-connected layers, to directly output the convolutional weight. WeightNet is easy and memory-conserving to train, on the kernel space instead of the feature space. Because of the flexibility, our method outperforms existing approaches on both ImageNet and COCO detection tasks, achieving better Accuracy-FLOPs and Accuracy-Parameter trade-offs. The framework on the flexible weight space has the potential to further improve the performance. Code is available at https://github.com/megvii-model/WeightNet.
Funnel Activation for Visual Recognition
Jul 24, 2020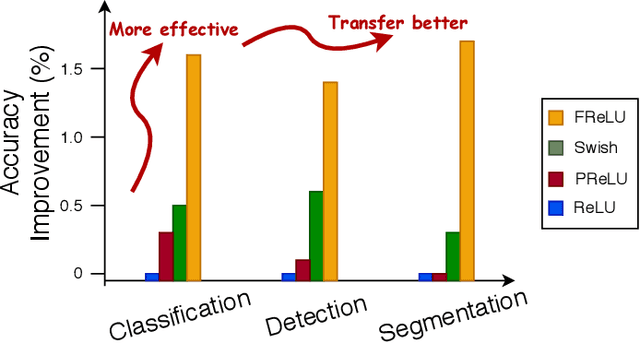



We present a conceptually simple but effective funnel activation for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition. The forms of ReLU and PReLU are y = max(x, 0) and y = max(x, px), respectively, while FReLU is in the form of y = max(x,T(x)), where T(x) is the 2D spatial condition. Moreover, the spatial condition achieves a pixel-wise modeling capacity in a simple way, capturing complicated visual layouts with regular convolutions. We conduct experiments on ImageNet, COCO detection, and semantic segmentation tasks, showing great improvements and robustness of FReLU in the visual recognition tasks. Code is available at https://github.com/megvii-model/FunnelAct.
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
Jul 30, 2018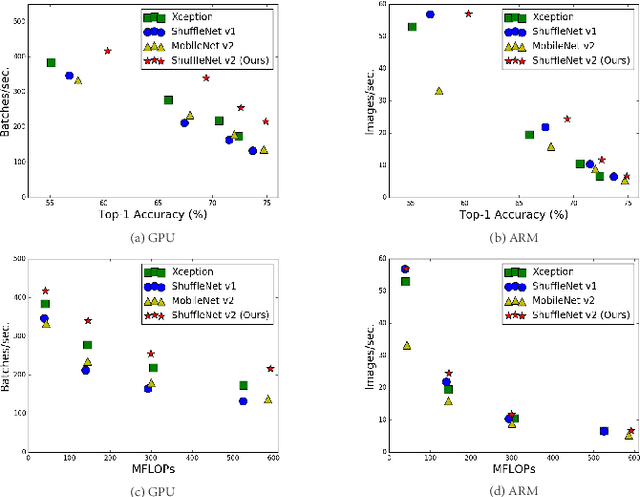
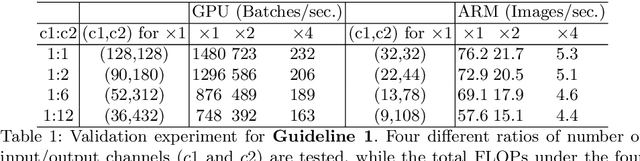
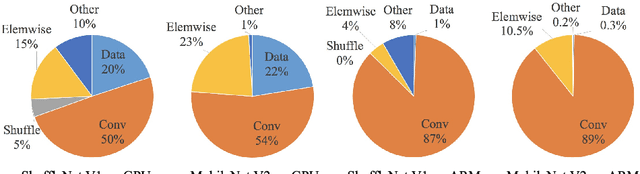
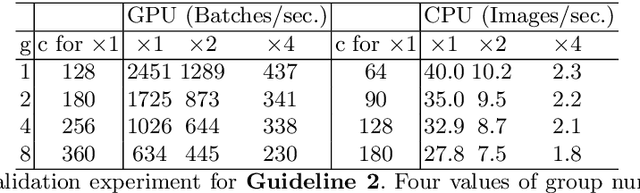
Currently, the neural network architecture design is mostly guided by the \emph{indirect} metric of computation complexity, i.e., FLOPs. However, the \emph{direct} metric, e.g., speed, also depends on the other factors such as memory access cost and platform characterics. Thus, this work proposes to evaluate the direct metric on the target platform, beyond only considering FLOPs. Based on a series of controlled experiments, this work derives several practical \emph{guidelines} for efficient network design. Accordingly, a new architecture is presented, called \emph{ShuffleNet V2}. Comprehensive ablation experiments verify that our model is the state-of-the-art in terms of speed and accuracy tradeoff.