 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivate or Not: Learning Customized Activation
Paper and Code



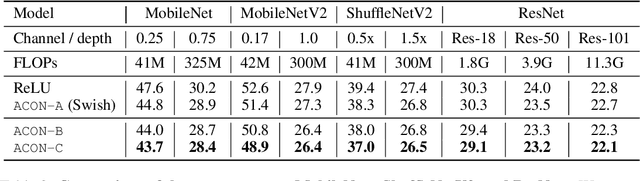
Modern activation layers use non-linear functions to activate the neurons. In this paper, we present a simple but effective activation function we term ACON which learns to activate the neurons or not. Surprisingly, we find Swish, the recent popular NAS-searched activation, can be interpreted as a smooth approximation to ReLU. Intuitively, in the same way, we approximate the variants in the ReLU family to the Swish family, we call ACON, which makes Swish a special case of ACON and remarkably improves the performance. Next, we present meta-ACON, which explicitly learns to optimize the parameter switching between non-linear (activate) and linear (inactivate) and provides a new design space. By simply changing the activation function, we improve the ImageNet top-1 accuracy rate by 6.7% and 1.8% on MobileNet-0.25 and ResNet-152, respectively.