 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights
Paper and Code
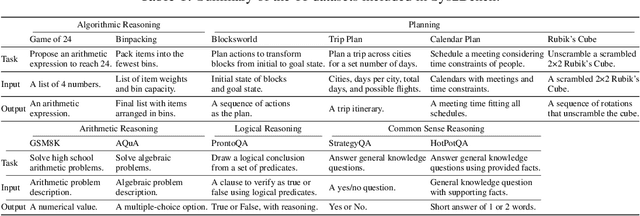

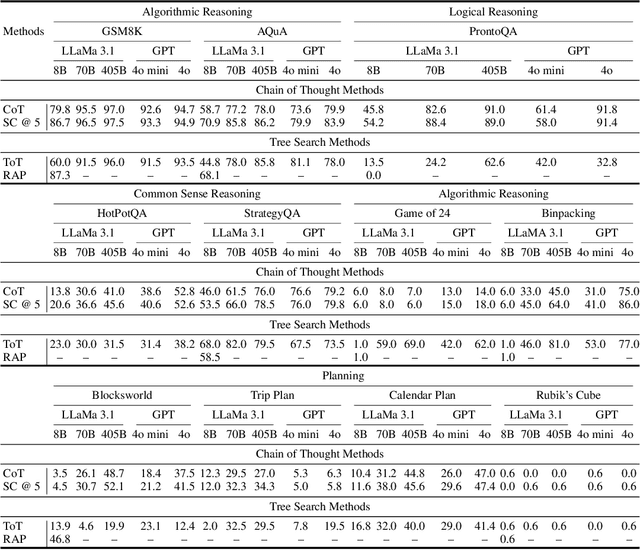

We examine the reasoning and planning capabilities of large language models (LLMs) in solving complex tasks. Recent advances in inference-time techniques demonstrate the potential to enhance LLM reasoning without additional training by exploring intermediate steps during inference. Notably, OpenAI's o1 model shows promising performance through its novel use of multi-step reasoning and verification. Here, we explore how scaling inference-time techniques can improve reasoning and planning, focusing on understanding the tradeoff between computational cost and performance. To this end, we construct a comprehensive benchmark, known as Sys2Bench, and perform extensive experiments evaluating existing inference-time techniques on eleven diverse tasks across five categories, including arithmetic reasoning, logical reasoning, common sense reasoning, algorithmic reasoning, and planning. Our findings indicate that simply scaling inference-time computation has limitations, as no single inference-time technique consistently performs well across all reasoning and planning tasks.