 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can human minimal videos tell us about dynamic recognition models?
Paper and Code
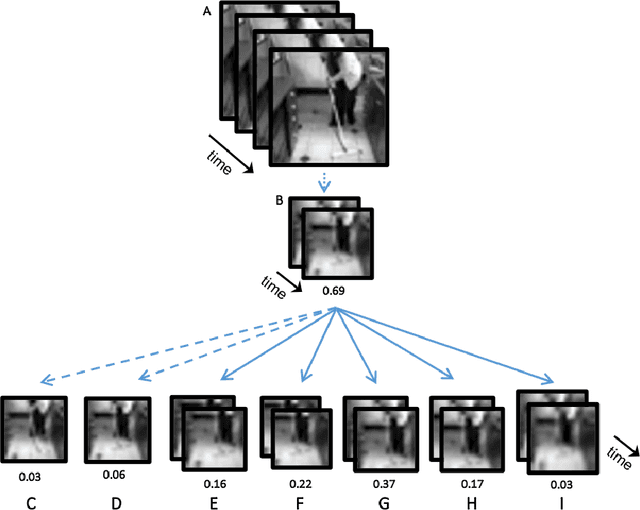

In human vision objects and their parts can be visually recognized from purely spatial or purely temporal information but the mechanisms integrating space and time are poorly understood. Here we show that human visual recognition of objects and actions can be achieved by efficiently combining spatial and motion cues in configurations where each source on its own is insufficient for recognition. This analysis is obtained by identifying minimal videos: these are short and tiny video clips in which objects, parts, and actions can be reliably recognized, but any reduction in either space or time makes them unrecognizable. State-of-the-art deep networks for dynamic visual recognition cannot replicate human behavior in these configurations. This gap between humans and machines points to critical mechanisms in human dynamic vision that are lacking in current models.