 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Encoder-based Reliable Classification
Feb 19, 2020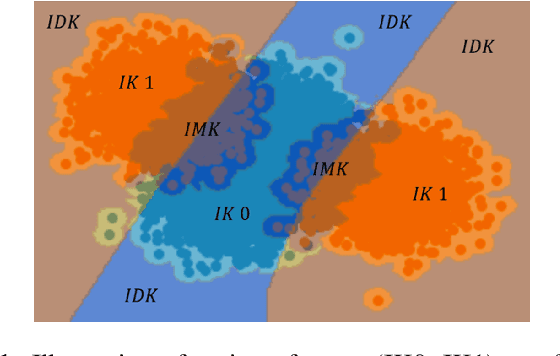
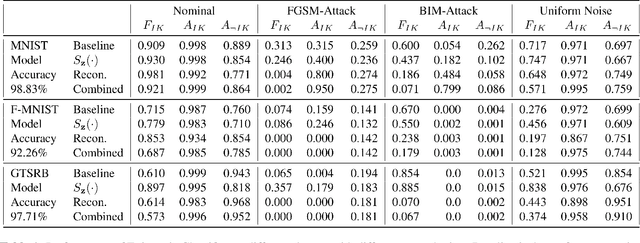
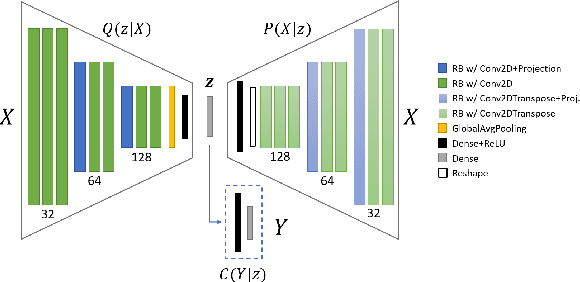
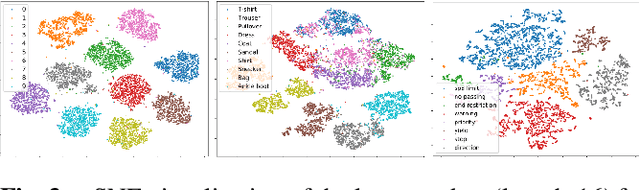
Machine learning models provide statistically impressive results which might be individually unreliable. To provide reliability, we propose an Epistemic Classifier (EC) that can provide justification of its belief using support from the training dataset as well as quality of reconstruction. Our approach is based on modified variational auto-encoders that can identify a semantically meaningful low-dimensional space where perceptually similar instances are close in $\ell_2$-distance too. Our results demonstrate improved reliability of predictions and robust identification of samples with adversarial attacks as compared to baseline of softmax-based thresholding.
Justification-Based Reliability in Machine Learning
Nov 18, 2019
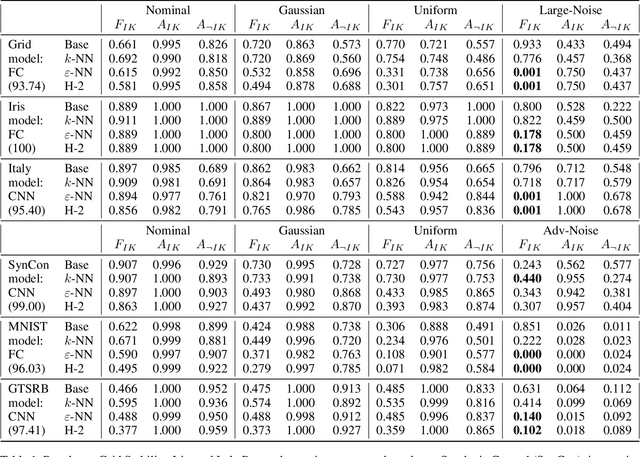

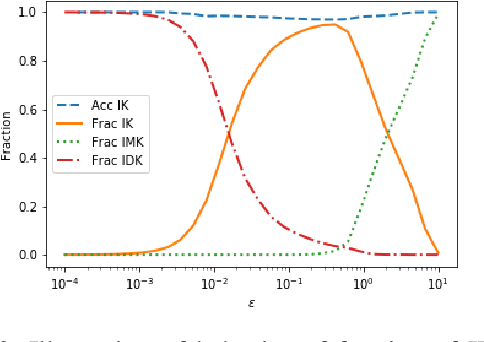
With the advent of Deep Learning, the field of machine learning (ML) has surpassed human-level performance on diverse classification tasks. At the same time, there is a stark need to characterize and quantify reliability of a model's prediction on individual samples. This is especially true in application of such models in safety-critical domains of industrial control and healthcare. To address this need, we link the question of reliability of a model's individual prediction to the epistemic uncertainty of the model's prediction. More specifically, we extend the theory of Justified True Belief (JTB) in epistemology, created to study the validity and limits of human-acquired knowledge, towards characterizing the validity and limits of knowledge in supervised classifiers. We present an analysis of neural network classifiers linking the reliability of its prediction on an input to characteristics of the support gathered from the input and latent spaces of the network. We hypothesize that the JTB analysis exposes the epistemic uncertainty (or ignorance) of a model with respect to its inference, thereby allowing for the inference to be only as strong as the justification permits. We explore various forms of support (for e.g., k-nearest neighbors (k-NN) and l_p-norm based) generated for an input, using the training data to construct a justification for the prediction with that input. Through experiments conducted on simulated and real datasets, we demonstrate that our approach can provide reliability for individual predictions and characterize regions where such reliability cannot be ascertained.
Design of intentional backdoors in sequential models
Feb 26, 2019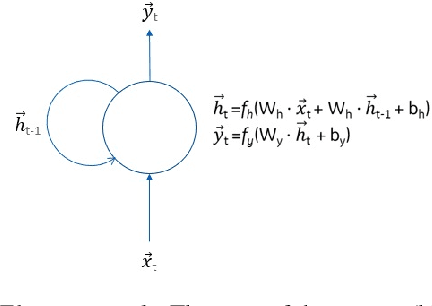
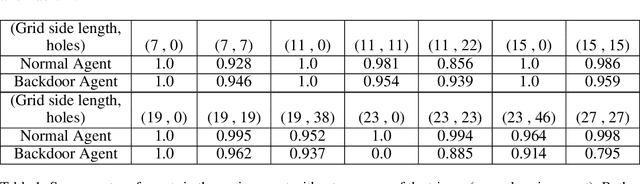
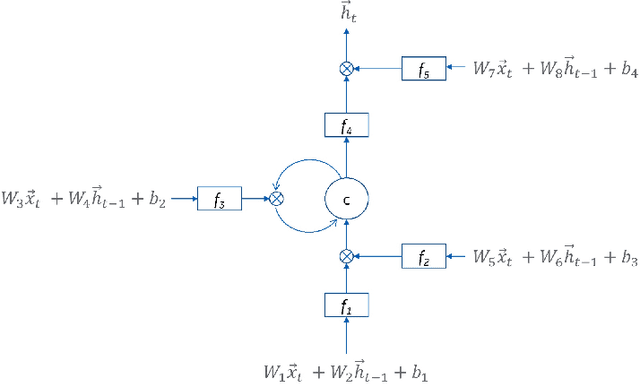
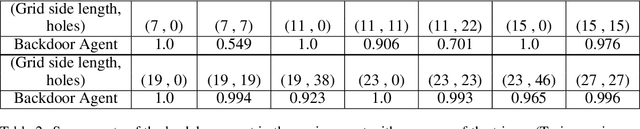
Recent work has demonstrated robust mechanisms by which attacks can be orchestrated on machine learning models. In contrast to adversarial examples, backdoor or trojan attacks embed surgically modified samples with targeted labels in the model training process to cause the targeted model to learn to misclassify chosen samples in the presence of specific triggers, while keeping the model performance stable across other nominal samples. However, current published research on trojan attacks mainly focuses on classification problems, which ignores sequential dependency between inputs. In this paper, we propose methods to discreetly introduce and exploit novel backdoor attacks within a sequential decision-making agent, such as a reinforcement learning agent, by training multiple benign and malicious policies within a single long short-term memory (LSTM) network. We demonstrate the effectiveness as well as the damaging impact of such attacks through initial outcomes generated from our approach, employed on grid-world environments. We also provide evidence as well as intuition on how the trojan trigger and malicious policy is activated. Challenges with network size and unintentional triggers are identified and analogies with adversarial examples are also discussed. In the end, we propose potential approaches to defend against or serve as early detection for such attacks. Results of our work can also be extended to many applications of LSTM and recurrent networks.