 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthRAR: Ring Artifacts Reduction in CT with Unrolled Network and Synthetic Data Training
Feb 12, 2026Defective and inconsistent responses in CT detectors can cause ring and streak artifacts in the reconstructed images, making them unusable for clinical purposes. In recent years, several ring artifact reduction solutions have been proposed in the image domain or in the sinogram domain using supervised deep learning methods. However, these methods require dedicated datasets for training, leading to a high data collection cost. Furthermore, existing approaches focus exclusively on either image-space or sinogram-space correction, neglecting the intrinsic correlations from the forward operation of the CT geometry. Based on the theoretical analysis of non-ideal CT detector responses, the RAR problem is reformulated as an inverse problem by using an unrolled network, which considers non-ideal response together with linear forward-projection with CT geometry. Additionally, the intrinsic correlations of ring artifacts between the sinogram and image domains are leveraged through synthetic data derived from natural images, enabling the trained model to correct artifacts without requiring real-world clinical data. Extensive evaluations on diverse scanning geometries and anatomical regions demonstrate that the model trained on synthetic data consistently outperforms existing state-of-the-art methods.
Low performing pixel correction in computed tomography with unrolled network and synthetic data training
Jan 28, 2026Low performance pixels (LPP) in Computed Tomography (CT) detectors would lead to ring and streak artifacts in the reconstructed images, making them clinically unusable. In recent years, several solutions have been proposed to correct LPP artifacts, either in the image domain or in the sinogram domain using supervised deep learning methods. However, these methods require dedicated datasets for training, which are expensive to collect. Moreover, existing approaches focus solely either on image-space or sinogram-space correction, ignoring the intrinsic correlations from the forward operation of the CT geometry. In this work, we propose an unrolled dual-domain method based on synthetic data to correct LPP artifacts. Specifically, the intrinsic correlations of LPP between the sinogram and image domains are leveraged through synthetic data generated from natural images, enabling the trained model to correct artifacts without requiring any real-world clinical data. In experiments simulating 1-2% detectors defect near the isocenter, the proposed method outperformed the state-of-the-art approaches by a large margin. The results indicate that our solution can correct LPP artifacts without the cost of data collection for model training, and it is adaptable to different scanner settings for software-based applications.
Synthetic Volumetric Data Generation Enables Zero-Shot Generalization of Foundation Models in 3D Medical Image Segmentation
Jan 18, 2026Foundation models such as Segment Anything Model 2 (SAM 2) exhibit strong generalization on natural images and videos but perform poorly on medical data due to differences in appearance statistics, imaging physics, and three-dimensional structure. To address this gap, we introduce SynthFM-3D, an analytical framework that mathematically models 3D variability in anatomy, contrast, boundary definition, and noise to generate synthetic data for training promptable segmentation models without real annotations. We fine-tuned SAM 2 on 10,000 SynthFM-3D volumes and evaluated it on eleven anatomical structures across three medical imaging modalities (CT, MR, ultrasound) from five public datasets. SynthFM-3D training led to consistent and statistically significant Dice score improvements over the pretrained SAM 2 baseline, demonstrating stronger zero-shot generalization across modalities. When compared with the supervised SAM-Med3D model on unseen cardiac ultrasound data, SynthFM-3D achieved 2-3x higher Dice scores, establishing analytical 3D data modeling as an effective pathway to modality-agnostic medical segmentation.
SynthFM: Training Modality-agnostic Foundation Models for Medical Image Segmentation without Real Medical Data
Apr 11, 2025



Foundation models like the Segment Anything Model (SAM) excel in zero-shot segmentation for natural images but struggle with medical image segmentation due to differences in texture, contrast, and noise. Annotating medical images is costly and requires domain expertise, limiting large-scale annotated data availability. To address this, we propose SynthFM, a synthetic data generation framework that mimics the complexities of medical images, enabling foundation models to adapt without real medical data. Using SAM's pretrained encoder and training the decoder from scratch on SynthFM's dataset, we evaluated our method on 11 anatomical structures across 9 datasets (CT, MRI, and Ultrasound). SynthFM outperformed zero-shot baselines like SAM and MedSAM, achieving superior results under different prompt settings and on out-of-distribution datasets.
SAS: Segment Anything Small for Ultrasound -- A Non-Generative Data Augmentation Technique for Robust Deep Learning in Ultrasound Imaging
Mar 07, 2025
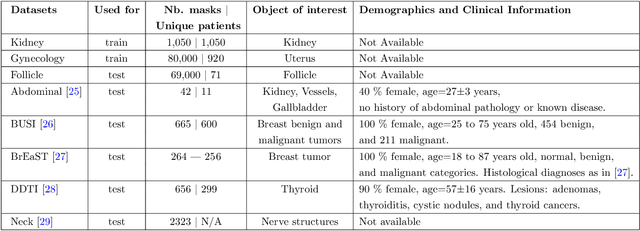
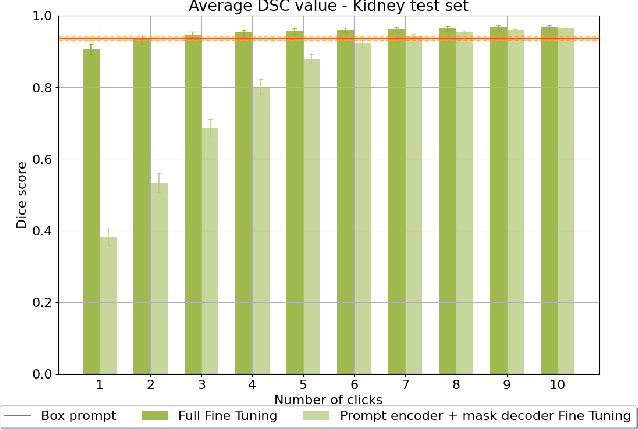
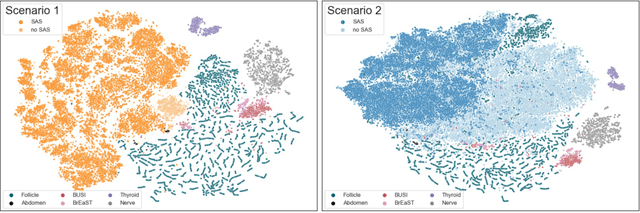
Accurate segmentation of anatomical structures in ultrasound (US) images, particularly small ones, is challenging due to noise and variability in imaging conditions (e.g., probe position, patient anatomy, tissue characteristics and pathology). To address this, we introduce Segment Anything Small (SAS), a simple yet effective scale- and texture-aware data augmentation technique designed to enhance the performance of deep learning models for segmenting small anatomical structures in ultrasound images. SAS employs a dual transformation strategy: (1) simulating diverse organ scales by resizing and embedding organ thumbnails into a black background, and (2) injecting noise into regions of interest to simulate varying tissue textures. These transformations generate realistic and diverse training data without introducing hallucinations or artifacts, improving the model's robustness to noise and variability. We fine-tuned a promptable foundation model on a controlled organ-specific medical imaging dataset and evaluated its performance on one internal and five external datasets. Experimental results demonstrate significant improvements in segmentation performance, with Dice score gains of up to 0.35 and an average improvement of 0.16 [95% CI 0.132,0.188]. Additionally, our iterative point prompts provide precise control and adaptive refinement, achieving performance comparable to bounding box prompts with just two points. SAS enhances model robustness and generalizability across diverse anatomical structures and imaging conditions, particularly for small structures, without compromising the accuracy of larger ones. By offering a computationally efficient solution that eliminates the need for extensive human labeling efforts, SAS emerges as a powerful tool for advancing medical image analysis, particularly in resource-constrained settings.
Quality Enhancement of Radiographic X-ray Images by Interpretable Mapping
Jan 21, 2025X-ray imaging is the most widely used medical imaging modality. However, in the common practice, inconsistency in the initial presentation of X-ray images is a common complaint by radiologists. Different patient positions, patient habitus and scanning protocols can lead to differences in image presentations, e.g., differences in brightness and contrast globally or regionally. To compensate for this, additional work will be executed by clinical experts to adjust the images to the desired presentation, which can be time-consuming. Existing deep-learning-based end-to-end solutions can automatically correct images with promising performances. Nevertheless, these methods are hard to be interpreted and difficult to be understood by clinical experts. In this manuscript, a novel interpretable mapping method by deep learning is proposed, which automatically enhances the image brightness and contrast globally and locally. Meanwhile, because the model is inspired by the workflow of the brightness and contrast manipulation, it can provide interpretable pixel maps for explaining the motivation of image enhancement. The experiment on the clinical datasets show the proposed method can provide consistent brightness and contrast correction on X-ray images with accuracy of 24.75 dB PSNR and 0.8431 SSIM.
CSG: A Context-Semantic Guided Diffusion Approach in De Novo Musculoskeletal Ultrasound Image Generation
Dec 08, 2024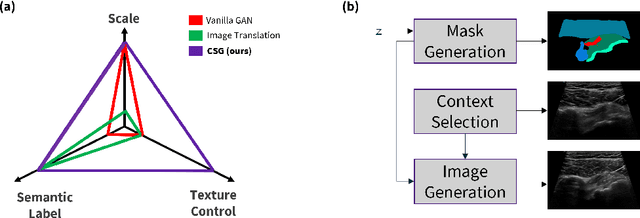
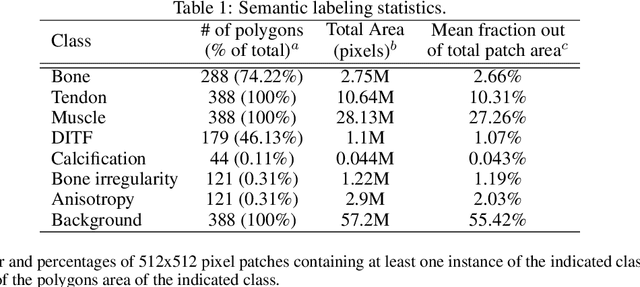
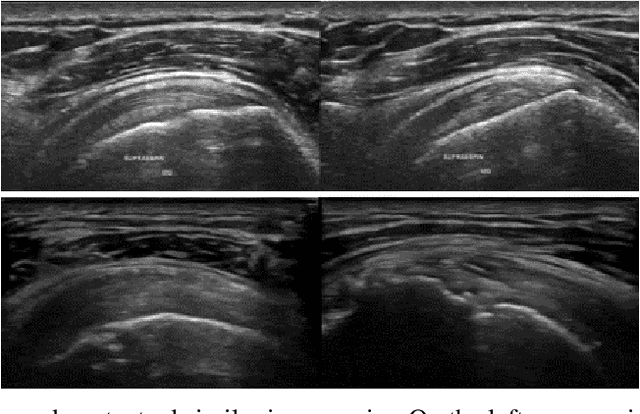
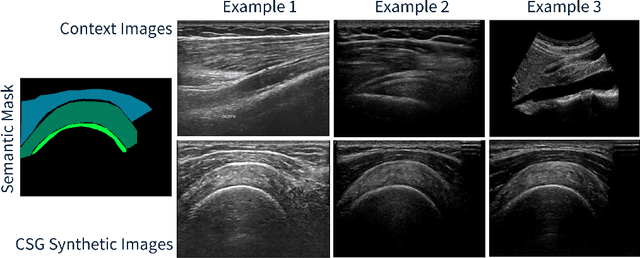
The use of synthetic images in medical imaging Artificial Intelligence (AI) solutions has been shown to be beneficial in addressing the limited availability of diverse, unbiased, and representative data. Despite the extensive use of synthetic image generation methods, controlling the semantics variability and context details remains challenging, limiting their effectiveness in producing diverse and representative medical image datasets. In this work, we introduce a scalable semantic and context-conditioned generative model, coined CSG (Context-Semantic Guidance). This dual conditioning approach allows for comprehensive control over both structure and appearance, advancing the synthesis of realistic and diverse ultrasound images. We demonstrate the ability of CSG to generate findings (pathological anomalies) in musculoskeletal (MSK) ultrasound images. Moreover, we test the quality of the synthetic images using a three-fold validation protocol. The results show that the synthetic images generated by CSG improve the performance of semantic segmentation models, exhibit enhanced similarity to real images compared to the baseline methods, and are undistinguishable from real images according to a Turing test. Furthermore, we demonstrate an extension of the CSG that allows enhancing the variability space of images by synthetically generating augmentations of anatomical geometries and textures.
Pristine annotations-based multi-modal trained artificial intelligence solution to triage chest X-ray for COVID-19
Nov 10, 2020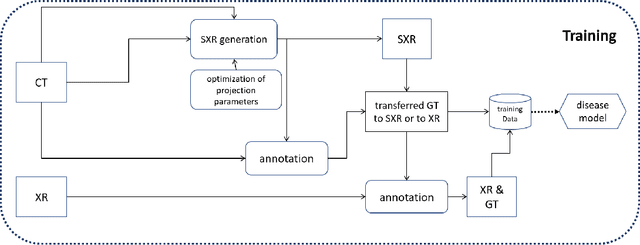



The COVID-19 pandemic continues to spread and impact the well-being of the global population. The front-line modalities including computed tomography (CT) and X-ray play an important role for triaging COVID patients. Considering the limited access of resources (both hardware and trained personnel) and decontamination considerations, CT may not be ideal for triaging suspected subjects. Artificial intelligence (AI) assisted X-ray based applications for triaging and monitoring require experienced radiologists to identify COVID patients in a timely manner and to further delineate the disease region boundary are seen as a promising solution. Our proposed solution differs from existing solutions by industry and academic communities, and demonstrates a functional AI model to triage by inferencing using a single x-ray image, while the deep-learning model is trained using both X-ray and CT data. We report on how such a multi-modal training improves the solution compared to X-ray only training. The multi-modal solution increases the AUC (area under the receiver operating characteristic curve) from 0.89 to 0.93 and also positively impacts the Dice coefficient (0.59 to 0.62) for localizing the pathology. To the best our knowledge, it is the first X-ray solution by leveraging multi-modal information for the development.
FastEstimator: A Deep Learning Library for Fast Prototyping and Productization
Nov 18, 2019
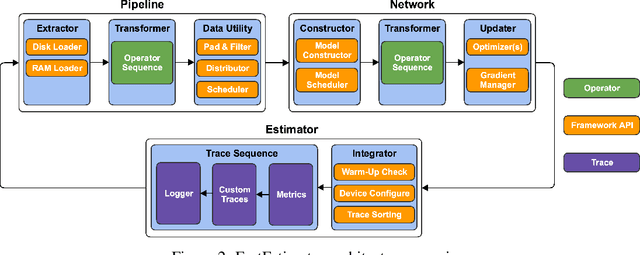

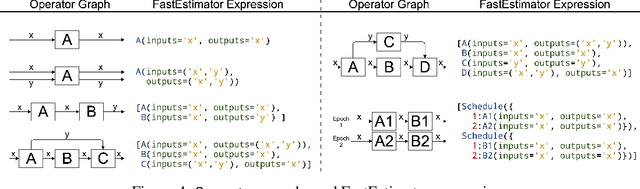
As the complexity of state-of-the-art deep learning models increases by the month, implementation, interpretation, and traceability become ever-more-burdensome challenges for AI practitioners around the world. Several AI frameworks have risen in an effort to stem this tide, but the steady advance of the field has begun to test the bounds of their flexibility, expressiveness, and ease of use. To address these concerns, we introduce a radically flexible high-level open source deep learning framework for both research and industry. We introduce FastEstimator.
AI Assisted Annotator using Reinforcement Learning
Oct 09, 2019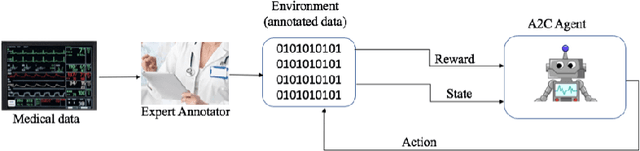



Healthcare data suffers from both noise and lack of ground truth. The cost of data increases as it is cleaned and annotated in healthcare. Unlike other data sets, medical data annotation, which is critical to accurate ground truth, requires medical domain expertise for a better patient outcome. In this work, we report on the use of reinforcement learning to mimic the decision making process of annotators for medical events, to automate annotation and labelling. The reinforcement agent learns to annotate alarm data based on annotations done by an expert. Our method shows promising results on medical alarm data sets. We trained DQN and A2C agents using the data from monitoring devices annotated by an expert. Initial results from these RL agents learning the expert annotation behavior are promising. The A2C agent performs better in terms of learning the sparse events in a given state, thereby choosing more right actions compared to DQN agent. To the best of our knowledge, this is the first reinforcement learning application for the automation of medical events annotation, which has far-reaching practical use.