 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonoSAMTrack -- Segment and Track Anything on Ultrasound Images
Nov 07, 2023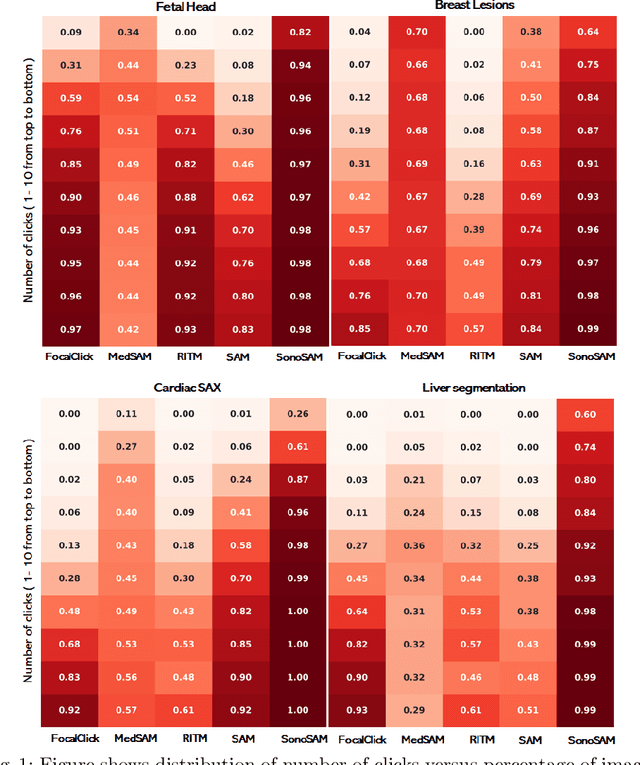
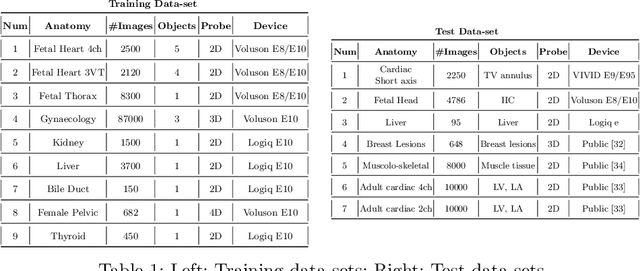
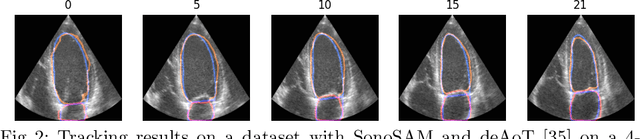
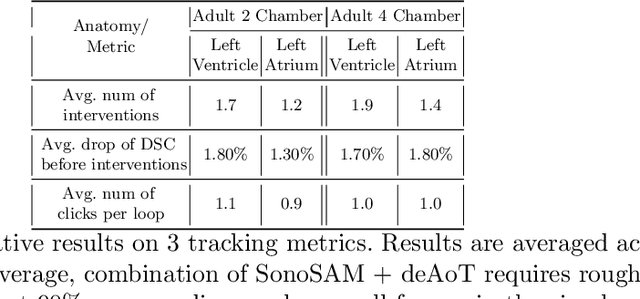
In this paper, we present SonoSAM - a promptable foundational model for segmenting objects of interest on ultrasound images, followed by state of the art tracking model to perform segmentations on 2D+t and 3D ultrasound datasets. Fine-tuned exclusively on a rich, diverse set of objects from $\approx200$k ultrasound image-mask pairs, SonoSAM demonstrates state-of-the-art performance on $8$ unseen ultrasound data-sets, outperforming competing methods by a significant margin on all metrics of interest. SonoSAM achieves average dice similarity score of $>90\%$ on almost all test data-sets within 2-6 clicks on an average, making it a valuable tool for annotating ultrasound images. We also extend SonoSAM to 3-D (2-D +t) applications and demonstrate superior performance making it a valuable tool for generating dense annotations from ultrasound cine-loops. Further, to increase practical utility of SonoSAM, we propose a two-step process of fine-tuning followed by knowledge distillation to a smaller footprint model without comprising the performance. We present detailed qualitative and quantitative comparisons of SonoSAM with state-of-the-art methods showcasing efficacy of SonoSAM as one of the first reliable, generic foundational model for ultrasound.
Fast Marching based Tissue Adaptive Delay Estimation for Aberration Corrected Delay and Sum Beamforming in Ultrasound Imaging
Apr 19, 2023Conventional ultrasound (US) imaging employs the delay and sum (DAS) receive beamforming with dynamic receive focus for image reconstruction due to its simplicity and robustness. However, the DAS beamforming follows a geometrical method of delay estimation with a spatially constant speed-of-sound (SoS) of 1540 m/s throughout the medium irrespective of the tissue in-homogeneity. This approximation leads to errors in delay estimations that accumulate with depth and degrades the resolution, contrast and overall accuracy of the US image. In this work, we propose a fast marching based DAS for focused transmissions which leverages the approximate SoS map to estimate the refraction corrected propagation delays for each pixel in the medium. The proposed approach is validated qualitatively and quantitatively for imaging depths of upto ~ 11 cm through simulations, where fat layer induced aberration is employed to alter the SoS in the medium. To the best of authors' knowledge, this is the first work considering the effect of SoS on image quality for deeper imaging.
Pristine annotations-based multi-modal trained artificial intelligence solution to triage chest X-ray for COVID-19
Nov 10, 2020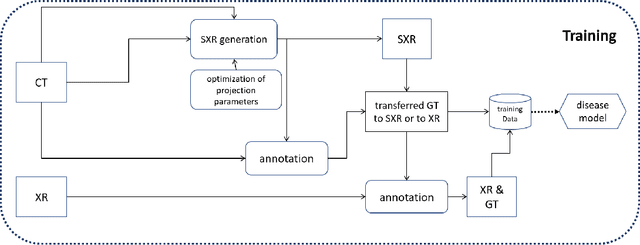



The COVID-19 pandemic continues to spread and impact the well-being of the global population. The front-line modalities including computed tomography (CT) and X-ray play an important role for triaging COVID patients. Considering the limited access of resources (both hardware and trained personnel) and decontamination considerations, CT may not be ideal for triaging suspected subjects. Artificial intelligence (AI) assisted X-ray based applications for triaging and monitoring require experienced radiologists to identify COVID patients in a timely manner and to further delineate the disease region boundary are seen as a promising solution. Our proposed solution differs from existing solutions by industry and academic communities, and demonstrates a functional AI model to triage by inferencing using a single x-ray image, while the deep-learning model is trained using both X-ray and CT data. We report on how such a multi-modal training improves the solution compared to X-ray only training. The multi-modal solution increases the AUC (area under the receiver operating characteristic curve) from 0.89 to 0.93 and also positively impacts the Dice coefficient (0.59 to 0.62) for localizing the pathology. To the best our knowledge, it is the first X-ray solution by leveraging multi-modal information for the development.