 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonoSAMTrack -- Segment and Track Anything on Ultrasound Images
Paper and Code
Nov 07, 2023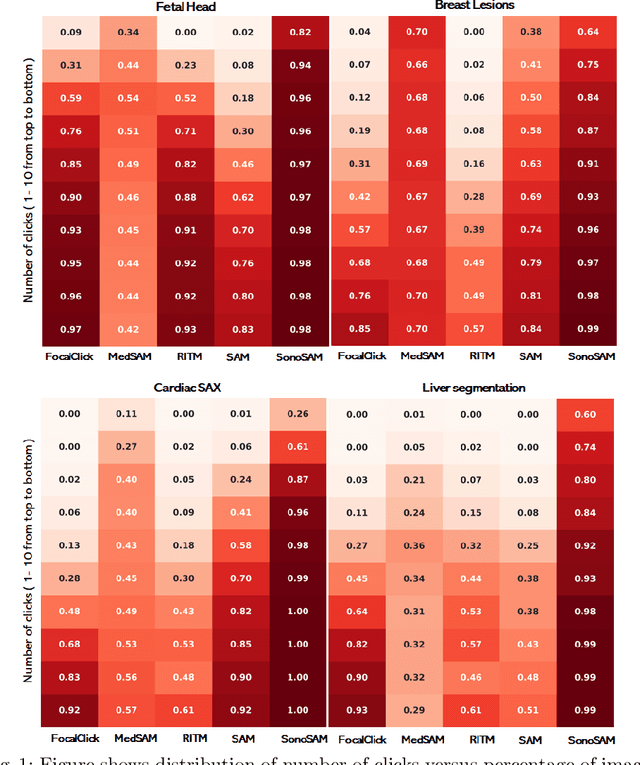
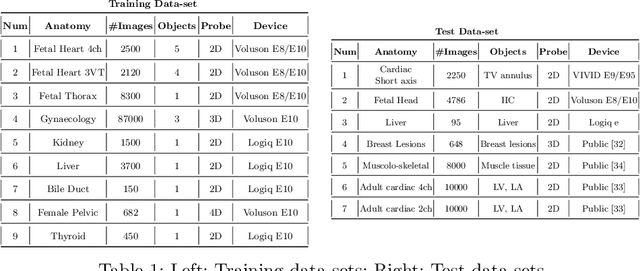
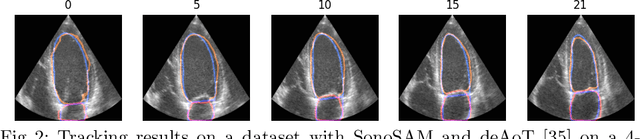
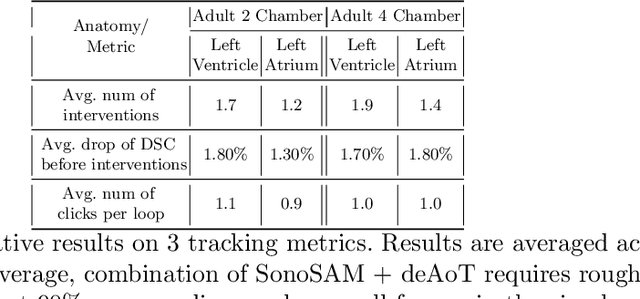
In this paper, we present SonoSAM - a promptable foundational model for segmenting objects of interest on ultrasound images, followed by state of the art tracking model to perform segmentations on 2D+t and 3D ultrasound datasets. Fine-tuned exclusively on a rich, diverse set of objects from $\approx200$k ultrasound image-mask pairs, SonoSAM demonstrates state-of-the-art performance on $8$ unseen ultrasound data-sets, outperforming competing methods by a significant margin on all metrics of interest. SonoSAM achieves average dice similarity score of $>90\%$ on almost all test data-sets within 2-6 clicks on an average, making it a valuable tool for annotating ultrasound images. We also extend SonoSAM to 3-D (2-D +t) applications and demonstrate superior performance making it a valuable tool for generating dense annotations from ultrasound cine-loops. Further, to increase practical utility of SonoSAM, we propose a two-step process of fine-tuning followed by knowledge distillation to a smaller footprint model without comprising the performance. We present detailed qualitative and quantitative comparisons of SonoSAM with state-of-the-art methods showcasing efficacy of SonoSAM as one of the first reliable, generic foundational model for ultrasound.