 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Raise or Not To Raise: The Autonomous Learning Rate Question
Jun 16, 2021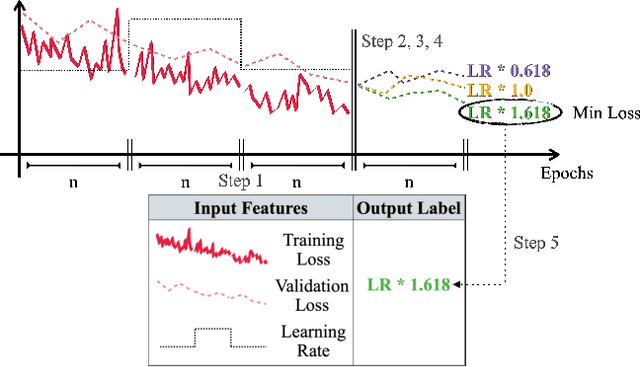
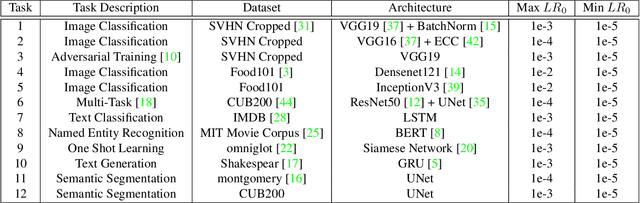

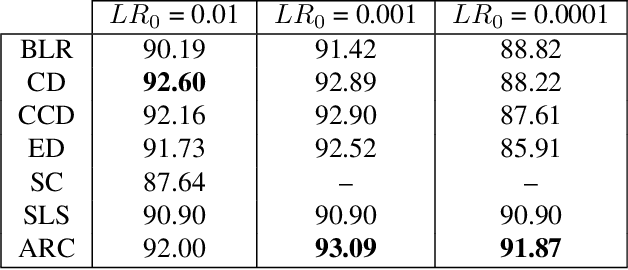
There is a parameter ubiquitous throughout the deep learning world: learning rate. There is likewise a ubiquitous question: what should that learning rate be? The true answer to this question is often tedious and time consuming to obtain, and a great deal of arcane knowledge has accumulated in recent years over how to pick and modify learning rates to achieve optimal training performance. Moreover, the long hours spent carefully crafting the perfect learning rate can come to nothing the moment your network architecture, optimizer, dataset, or initial conditions change ever so slightly. But it need not be this way. We propose a new answer to the great learning rate question: the Autonomous Learning Rate Controller. Find it at https://github.com/fastestimator/ARC
Automating Augmentation Through Random Unidimensional Search
Jun 16, 2021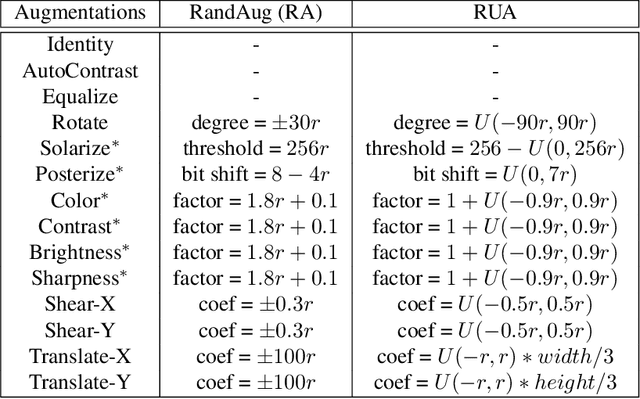
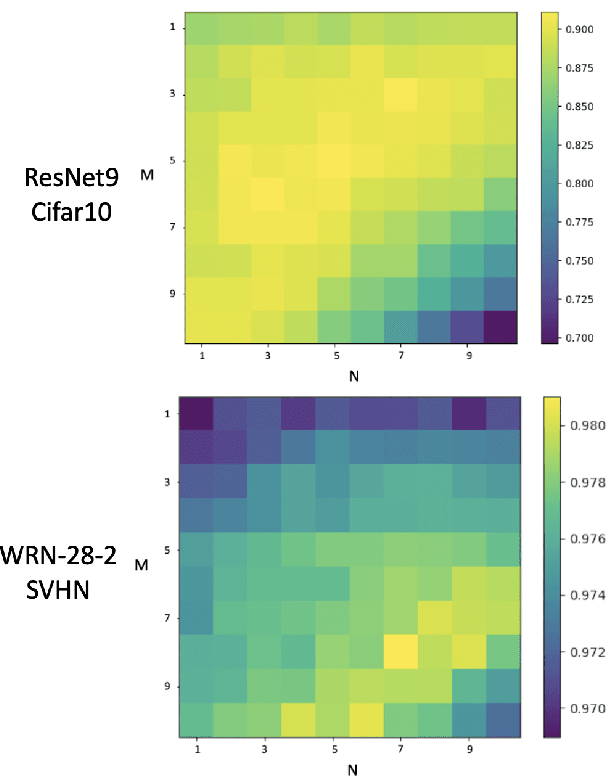
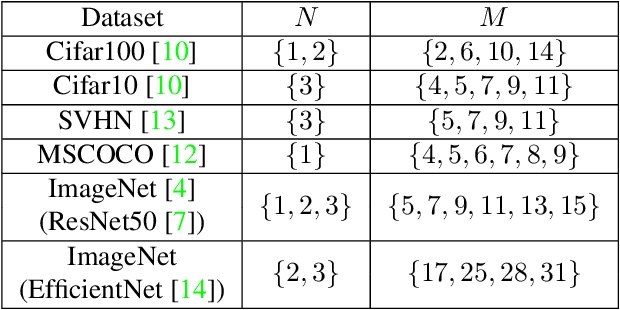
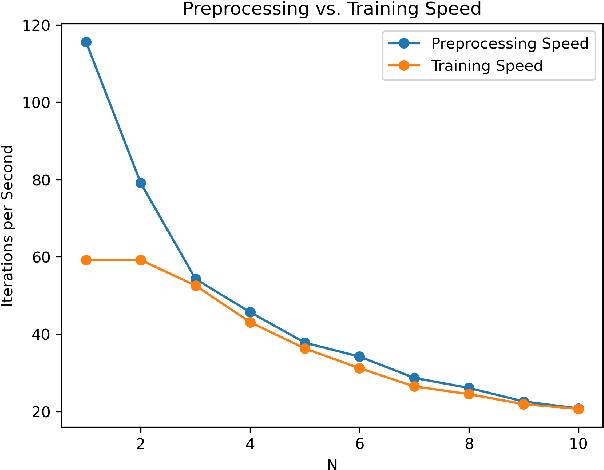
It is no secret amongst deep learning researchers that finding the right data augmentation strategy during training can mean the difference between a state-of-the-art result and a run-of-the-mill ranking. To that end, the community has seen many efforts to automate the process of finding the perfect augmentation procedure for any task at hand. Unfortunately, even recent cutting-edge methods bring massive computational overhead, requiring as many as 100 full model trainings to settle on an ideal configuration. We show how to achieve even better performance in just 7: with Random Unidimensional Augmentation. Source code is available at https://github.com/fastestimator/RUA
FastEstimator: A Deep Learning Library for Fast Prototyping and Productization
Nov 18, 2019
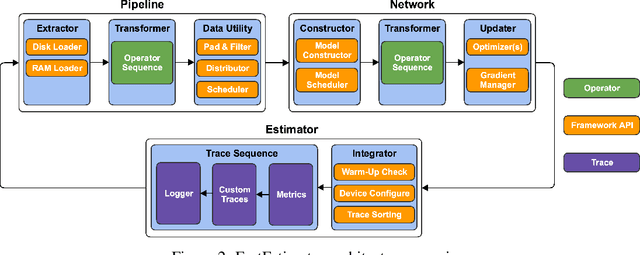

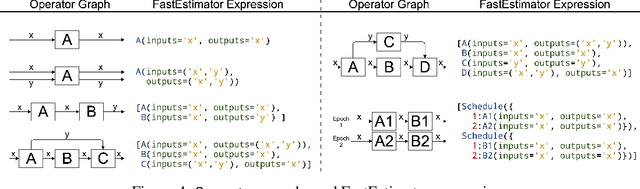
As the complexity of state-of-the-art deep learning models increases by the month, implementation, interpretation, and traceability become ever-more-burdensome challenges for AI practitioners around the world. Several AI frameworks have risen in an effort to stem this tide, but the steady advance of the field has begun to test the bounds of their flexibility, expressiveness, and ease of use. To address these concerns, we introduce a radically flexible high-level open source deep learning framework for both research and industry. We introduce FastEstimator.
AI Assisted Annotator using Reinforcement Learning
Oct 09, 2019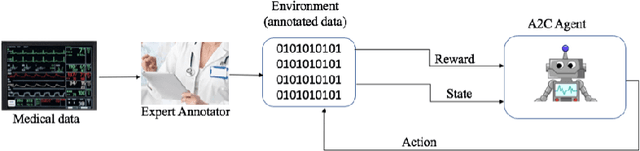



Healthcare data suffers from both noise and lack of ground truth. The cost of data increases as it is cleaned and annotated in healthcare. Unlike other data sets, medical data annotation, which is critical to accurate ground truth, requires medical domain expertise for a better patient outcome. In this work, we report on the use of reinforcement learning to mimic the decision making process of annotators for medical events, to automate annotation and labelling. The reinforcement agent learns to annotate alarm data based on annotations done by an expert. Our method shows promising results on medical alarm data sets. We trained DQN and A2C agents using the data from monitoring devices annotated by an expert. Initial results from these RL agents learning the expert annotation behavior are promising. The A2C agent performs better in terms of learning the sparse events in a given state, thereby choosing more right actions compared to DQN agent. To the best of our knowledge, this is the first reinforcement learning application for the automation of medical events annotation, which has far-reaching practical use.
Impact of Inference Accelerators on hardware selection
Oct 07, 2019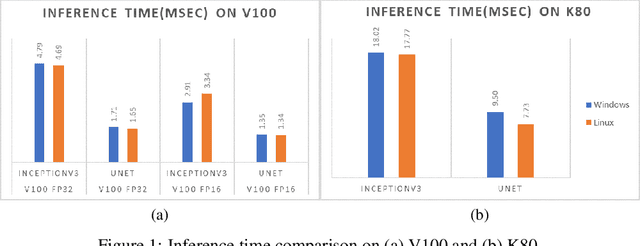
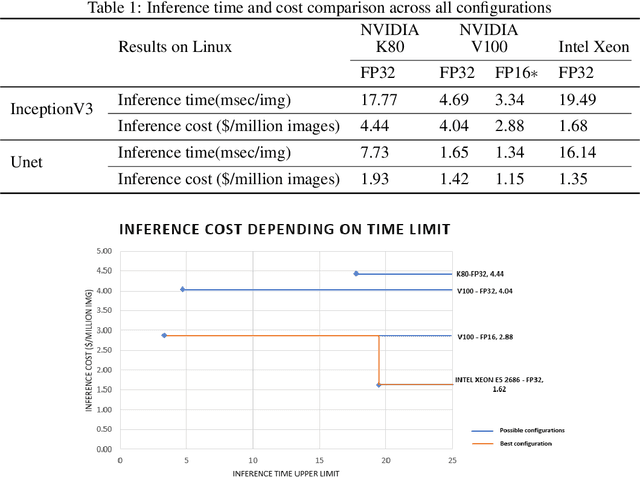
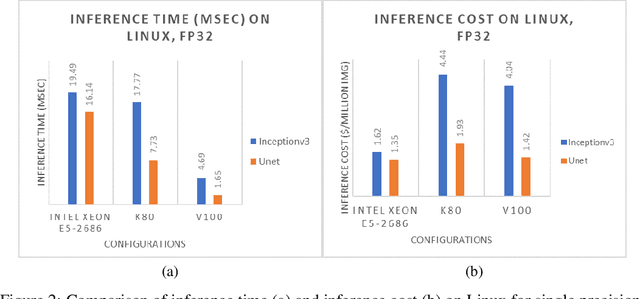

As opportunities for AI-assisted healthcare grow steadily, model deployment faces challenges due to the specific characteristics of the industry. The configuration choice for a production device can impact model performance while influencing operational costs. Moreover, in healthcare some situations might require fast, but not real time, inference. We study different configurations and conduct a cost-performance analysis to determine the optimized hardware for the deployment of a model subject to healthcare domain constraints. We observe that a naive performance comparison may not lead to an optimal configuration selection. In fact, given realistic domain constraints, CPU execution might be preferable to GPU accelerators. Hence, defining beforehand precise expectations for model deployment is crucial.