 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseDVFS: Sparse-Aware DVFS for Energy-Efficient Edge Inference
Mar 23, 2026Deploying deep neural networks (DNNs) on power-sensitive edge devices presents a formidable challenge. While Dynamic Voltage and Frequency Scaling (DVFS) is widely employed for energy optimization, traditional model-level scaling is often too coarse to capture intra-inference variations, whereas fine-grained operator-level scaling suffers from prohibitive performance degradation due to significant hardware switching latency. This paper presents SparseDVFS, a fine-grained, sparse-aware DVFS framework designed for energy-efficient edge inference. Our key insight is that operator sparsity is a primary metric for hardware frequency modulation. By distinguishing between compute-bound dense operators and memory-bound sparse operators, the system can apply specialized frequency triplets to maximize energy efficiency. To overcome switching overheads and component interference, SparseDVFS incorporates three key innovations: (1) an offline modeler that established a deterministic mapping between operator sparsity and optimal frequency triplets (CPU/GPU/EMC) via white-box timeline analysis; (2) a runtime graph partitioner that utilizes a greedy merging heuristic to aggregate operators into super-blocks, balancing scaling granularity and DVFS switching latency through a latency amortization constraint; and (3) a unified co-governor that employs a frequency unified scaling engine (FUSE) and a look-ahead instruction queue to eliminate antagonistic effects between independent controllers and hide hardware transition latencies. Extensive evaluations show that SparseDVFS achieves an average 78.17% energy efficiency gain over state-of-the-art solutions while maintaining a superior 14% cost-gain ratio.
Online Optimization for Learning to Communicate over Time-Correlated Channels
Sep 01, 2024



Machine learning techniques have garnered great interest in designing communication systems owing to their capacity in tacking with channel uncertainty. To provide theoretical guarantees for learning-based communication systems, some recent works analyze generalization bounds for devised methods based on the assumption of Independently and Identically Distributed (I.I.D.) channels, a condition rarely met in practical scenarios. In this paper, we drop the I.I.D. channel assumption and study an online optimization problem of learning to communicate over time-correlated channels. To address this issue, we further focus on two specific tasks: optimizing channel decoders for time-correlated fading channels and selecting optimal codebooks for time-correlated additive noise channels. For utilizing temporal dependence of considered channels to better learn communication systems, we develop two online optimization algorithms based on the optimistic online mirror descent framework. Furthermore, we provide theoretical guarantees for proposed algorithms via deriving sub-linear regret bound on the expected error probability of learned systems. Extensive simulation experiments have been conducted to validate that our presented approaches can leverage the channel correlation to achieve a lower average symbol error rate compared to baseline methods, consistent with our theoretical findings.
Intelligent Cross-Organizational Process Mining: A Survey and New Perspectives
Jul 15, 2024



Process mining, as a high-level field in data mining, plays a crucial role in enhancing operational efficiency and decision-making across organizations. In this survey paper, we delve into the growing significance and ongoing trends in the field of process mining, advocating a specific viewpoint on its contents, application, and development in modern businesses and process management, particularly in cross-organizational settings. We first summarize the framework of process mining, common industrial applications, and the latest advances combined with artificial intelligence, such as workflow optimization, compliance checking, and performance analysis. Then, we propose a holistic framework for intelligent process analysis and outline initial methodologies in cross-organizational settings, highlighting both challenges and opportunities. This particular perspective aims to revolutionize process mining by leveraging artificial intelligence to offer sophisticated solutions for complex, multi-organizational data analysis. By integrating advanced machine learning techniques, we can enhance predictive capabilities, streamline processes, and facilitate real-time decision-making. Furthermore, we pinpoint avenues for future investigations within the research community, encouraging the exploration of innovative algorithms, data integration strategies, and privacy-preserving methods to fully harness the potential of process mining in diverse, interconnected business environments.
On the Necessity of Collaboration in Online Model Selection with Decentralized Data
Apr 15, 2024We consider online model selection with decentralized data over $M$ clients, and study a fundamental problem: the necessity of collaboration. Previous work gave a negative answer from the perspective of worst-case regret minimization, while we give a different answer from the perspective of regret-computational cost trade-off. We separately propose a federated algorithm with and without communication constraint and prove regret bounds that show (i) collaboration is unnecessary if we do not limit the computational cost on each client; (ii) collaboration is necessary if we limit the computational cost on each client to $o(K)$, where $K$ is the number of candidate hypothesis spaces. As a by-product, we improve the regret bounds of algorithms for distributed online multi-kernel learning at a smaller computational and communication cost. Our algorithms rely on three new techniques, i.e., an improved Bernstein's inequality for martingale, a federated algorithmic framework, named FOMD-No-LU, and decoupling model selection and predictions, which might be of independent interest.
Topology Learning for Heterogeneous Decentralized Federated Learning over Unreliable D2D Networks
Dec 21, 2023
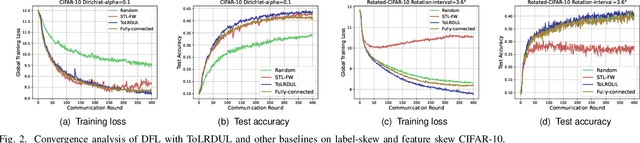
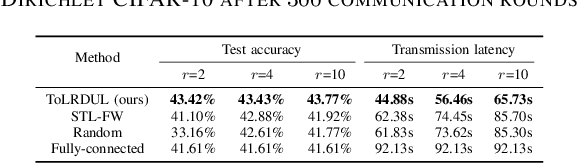
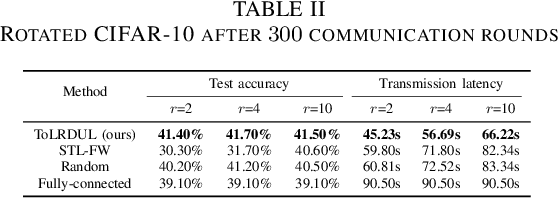
With the proliferation of intelligent mobile devices in wireless device-to-device (D2D) networks, decentralized federated learning (DFL) has attracted significant interest. Compared to centralized federated learning (CFL), DFL mitigates the risk of central server failures due to communication bottlenecks. However, DFL faces several challenges, such as the severe heterogeneity of data distributions in diverse environments, and the transmission outages and package errors caused by the adoption of the User Datagram Protocol (UDP) in D2D networks. These challenges often degrade the convergence of training DFL models. To address these challenges, we conduct a thorough theoretical convergence analysis for DFL and derive a convergence bound. By defining a novel quantity named unreliable links-aware neighborhood discrepancy in this convergence bound, we formulate a tractable optimization objective, and develop a novel Topology Learning method considering the Representation Discrepancy and Unreliable Links in DFL, named ToLRDUL. Intensive experiments under both feature skew and label skew settings have validated the effectiveness of our proposed method, demonstrating improved convergence speed and test accuracy, consistent with our theoretical findings.
Information-Theoretic Generalization Analysis for Topology-aware Heterogeneous Federated Edge Learning over Noisy Channels
Oct 25, 2023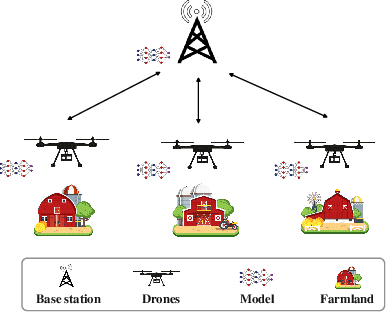
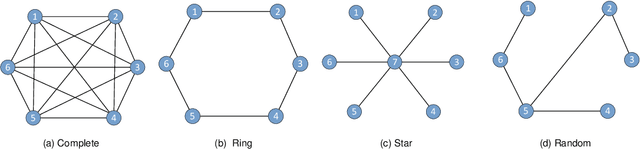
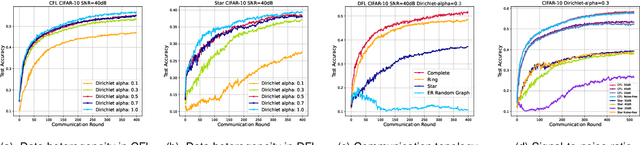
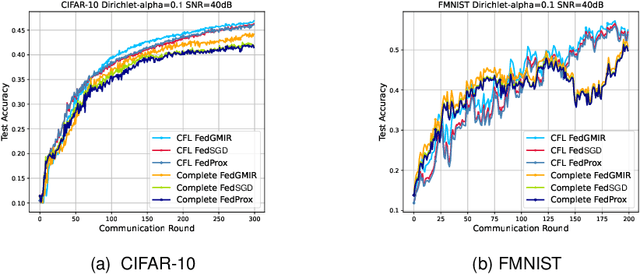
With the rapid growth of edge intelligence, the deployment of federated learning (FL) over wireless networks has garnered increasing attention, which is called Federated Edge Learning (FEEL). In FEEL, both mobile devices transmitting model parameters over noisy channels and collecting data in diverse environments pose challenges to the generalization of trained models. Moreover, devices can engage in decentralized FL via Device-to-Device communication while the communication topology of connected devices also impacts the generalization of models. Most recent theoretical studies overlook the incorporation of all these effects into FEEL when developing generalization analyses. In contrast, our work presents an information-theoretic generalization analysis for topology-aware FEEL in the presence of data heterogeneity and noisy channels. Additionally, we propose a novel regularization method called Federated Global Mutual Information Reduction (FedGMIR) to enhance the performance of models based on our analysis. Numerical results validate our theoretical findings and provide evidence for the effectiveness of the proposed method.
Federated Generalization via Information-Theoretic Distribution Diversification
Oct 13, 2023Federated Learning (FL) has surged in prominence due to its capability of collaborative model training without direct data sharing. However, the vast disparity in local data distributions among clients, often termed the non-Independent Identically Distributed (non-IID) challenge, poses a significant hurdle to FL's generalization efficacy. The scenario becomes even more complex when not all clients participate in the training process, a common occurrence due to unstable network connections or limited computational capacities. This can greatly complicate the assessment of the trained models' generalization abilities. While a plethora of recent studies has centered on the generalization gap pertaining to unseen data from participating clients with diverse distributions, the divergence between the training distributions of participating clients and the testing distributions of non-participating ones has been largely overlooked. In response, our paper unveils an information-theoretic generalization framework for FL. Specifically, it quantifies generalization errors by evaluating the information entropy of local distributions and discerning discrepancies across these distributions. Inspired by our deduced generalization bounds, we introduce a weighted aggregation approach and a duo of client selection strategies. These innovations aim to bolster FL's generalization prowess by encompassing a more varied set of client data distributions. Our extensive empirical evaluations reaffirm the potency of our proposed methods, aligning seamlessly with our theoretical construct.