 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPGP: A Hybrid 2D-3D Dual Path Potential Ghost Probe Zone Prediction Framework for Safe Autonomous Driving
Apr 23, 2025



Modern robots must coexist with humans in dense urban environments. A key challenge is the ghost probe problem, where pedestrians or objects unexpectedly rush into traffic paths. This issue affects both autonomous vehicles and human drivers. Existing works propose vehicle-to-everything (V2X) strategies and non-line-of-sight (NLOS) imaging for ghost probe zone detection. However, most require high computational power or specialized hardware, limiting real-world feasibility. Additionally, many methods do not explicitly address this issue. To tackle this, we propose DPGP, a hybrid 2D-3D fusion framework for ghost probe zone prediction using only a monocular camera during training and inference. With unsupervised depth prediction, we observe ghost probe zones align with depth discontinuities, but different depth representations offer varying robustness. To exploit this, we fuse multiple feature embeddings to improve prediction. To validate our approach, we created a 12K-image dataset annotated with ghost probe zones, carefully sourced and cross-checked for accuracy. Experimental results show our framework outperforms existing methods while remaining cost-effective. To our knowledge, this is the first work extending ghost probe zone prediction beyond vehicles, addressing diverse non-vehicle objects. We will open-source our code and dataset for community benefit.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021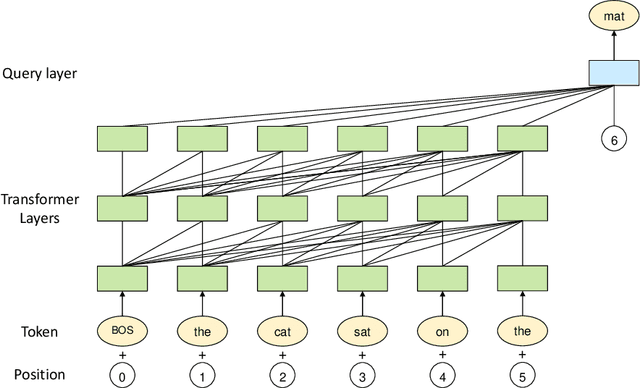
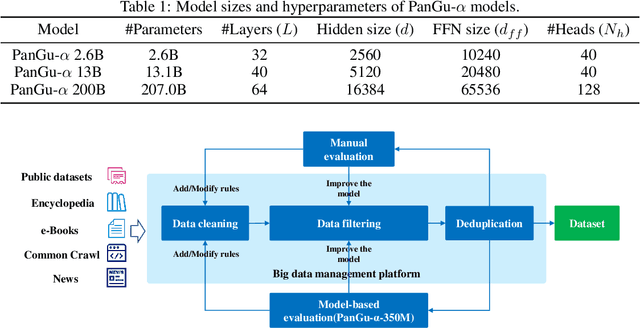
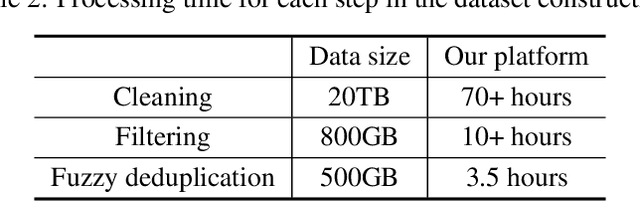
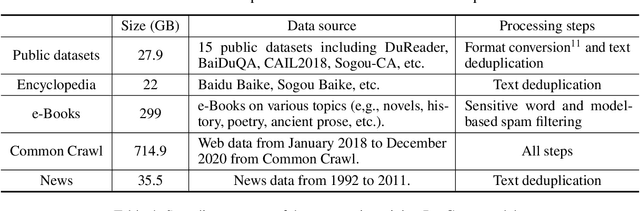
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.