 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRTGaussian: Efficient Relighting Using 3D Gaussians with Precomputed Radiance Transfer
Aug 10, 2024We present PRTGaussian, a realtime relightable novel-view synthesis method made possible by combining 3D Gaussians and Precomputed Radiance Transfer (PRT). By fitting relightable Gaussians to multi-view OLAT data, our method enables real-time, free-viewpoint relighting. By estimating the radiance transfer based on high-order spherical harmonics, we achieve a balance between capturing detailed relighting effects and maintaining computational efficiency. We utilize a two-stage process: in the first stage, we reconstruct a coarse geometry of the object from multi-view images. In the second stage, we initialize 3D Gaussians with the obtained point cloud, then simultaneously refine the coarse geometry and learn the light transport for each Gaussian. Extensive experiments on synthetic datasets show that our approach can achieve fast and high-quality relighting for general objects. Code and data are available at https://github.com/zhanglbthu/PRTGaussian.
Relightable and Animatable Neural Avatars from Videos
Dec 20, 2023



Lightweight creation of 3D digital avatars is a highly desirable but challenging task. With only sparse videos of a person under unknown illumination, we propose a method to create relightable and animatable neural avatars, which can be used to synthesize photorealistic images of humans under novel viewpoints, body poses, and lighting. The key challenge here is to disentangle the geometry, material of the clothed body, and lighting, which becomes more difficult due to the complex geometry and shadow changes caused by body motions. To solve this ill-posed problem, we propose novel techniques to better model the geometry and shadow changes. For geometry change modeling, we propose an invertible deformation field, which helps to solve the inverse skinning problem and leads to better geometry quality. To model the spatial and temporal varying shading cues, we propose a pose-aware part-wise light visibility network to estimate light occlusion. Extensive experiments on synthetic and real datasets show that our approach reconstructs high-quality geometry and generates realistic shadows under different body poses. Code and data are available at \url{https://wenbin-lin.github.io/RelightableAvatar-page/}.
EditableNeRF: Editing Topologically Varying Neural Radiance Fields by Key Points
Dec 07, 2022

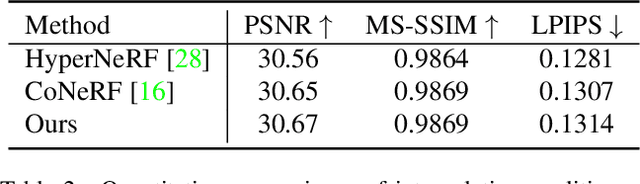

Neural radiance fields (NeRF) achieve highly photo-realistic novel-view synthesis, but it's a challenging problem to edit the scenes modeled by NeRF-based methods, especially for dynamic scenes. We propose editable neural radiance fields that enable end-users to easily edit dynamic scenes and even support topological changes. Input with an image sequence from a single camera, our network is trained fully automatically and models topologically varying dynamics using our picked-out surface key points. Then end-users can edit the scene by easily dragging the key points to desired new positions. To achieve this, we propose a scene analysis method to detect and initialize key points by considering the dynamics in the scene, and a weighted key points strategy to model topologically varying dynamics by joint key points and weights optimization. Our method supports intuitive multi-dimensional (up to 3D) editing and can generate novel scenes that are unseen in the input sequence. Experiments demonstrate that our method achieves high-quality editing on various dynamic scenes and outperforms the state-of-the-art. We will release our code and captured data.
OcclusionFusion: Occlusion-aware Motion Estimation for Real-time Dynamic 3D Reconstruction
Mar 15, 2022


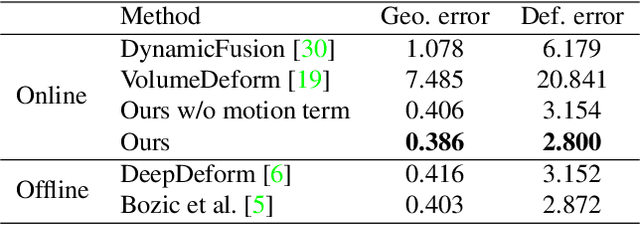
RGBD-based real-time dynamic 3D reconstruction suffers from inaccurate inter-frame motion estimation as errors may accumulate with online tracking. This problem is even more severe for single-view-based systems due to strong occlusions. Based on these observations, we propose OcclusionFusion, a novel method to calculate occlusion-aware 3D motion to guide the reconstruction. In our technique, the motion of visible regions is first estimated and combined with temporal information to infer the motion of the occluded regions through an LSTM-involved graph neural network. Furthermore, our method computes the confidence of the estimated motion by modeling the network output with a probabilistic model, which alleviates untrustworthy motions and enables robust tracking. Experimental results on public datasets and our own recorded data show that our technique outperforms existing single-view-based real-time methods by a large margin. With the reduction of the motion errors, the proposed technique can handle long and challenging motion sequences. Please check out the project page for sequence results: https://wenbin-lin.github.io/OcclusionFusion.