 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion-based Super-Resolution with Dynamic Time-Spatial Sampling
May 17, 2025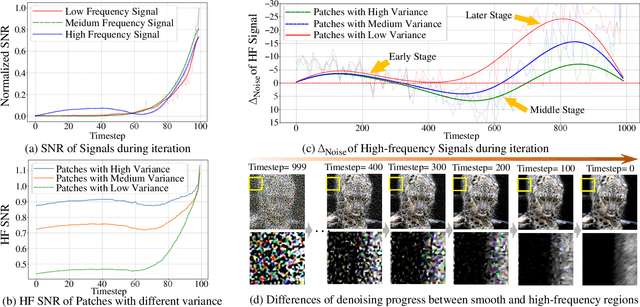
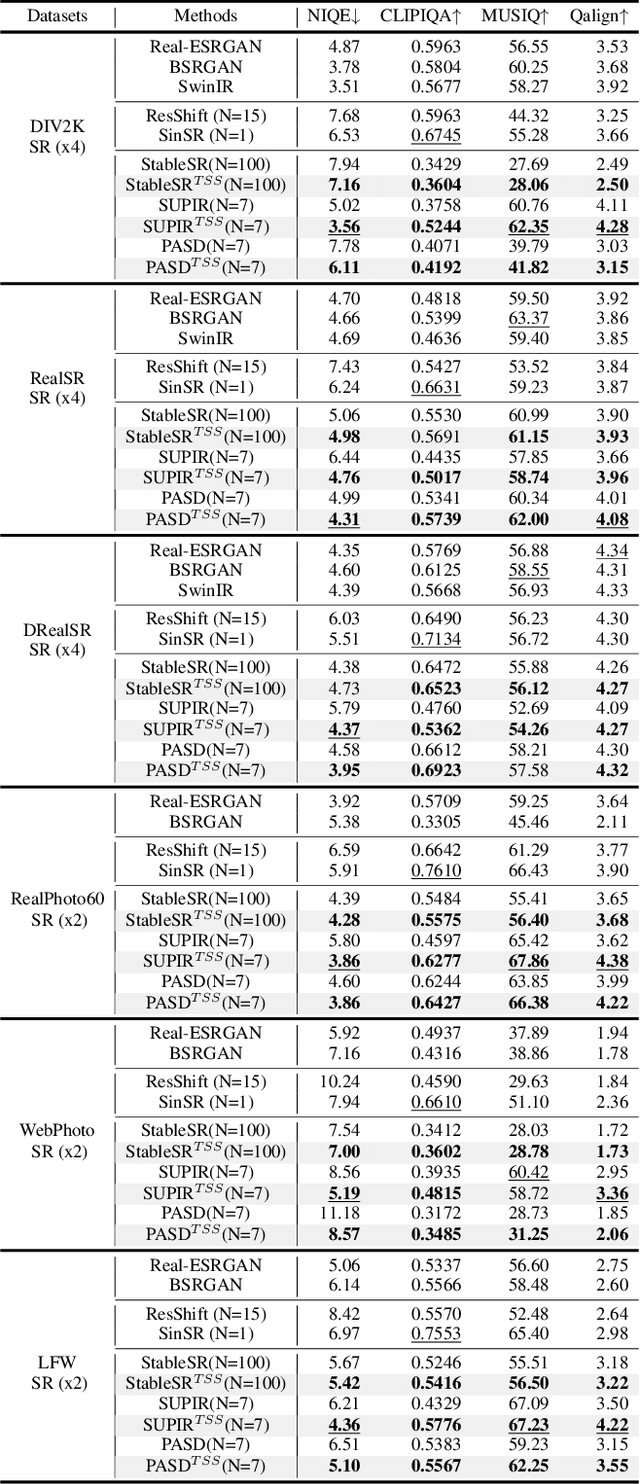
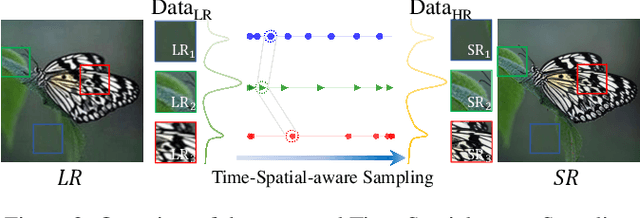
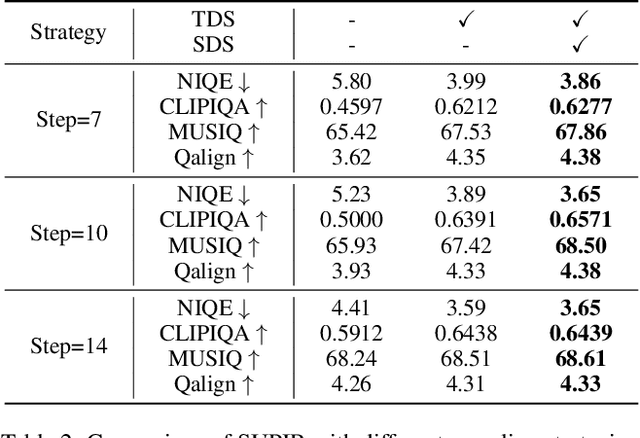
Diffusion models have gained attention for their success in modeling complex distributions, achieving impressive perceptual quality in SR tasks. However, existing diffusion-based SR methods often suffer from high computational costs, requiring numerous iterative steps for training and inference. Existing acceleration techniques, such as distillation and solver optimization, are generally task-agnostic and do not fully leverage the specific characteristics of low-level tasks like super-resolution (SR). In this study, we analyze the frequency- and spatial-domain properties of diffusion-based SR methods, revealing key insights into the temporal and spatial dependencies of high-frequency signal recovery. Specifically, high-frequency details benefit from concentrated optimization during early and late diffusion iterations, while spatially textured regions demand adaptive denoising strategies. Building on these observations, we propose the Time-Spatial-aware Sampling strategy (TSS) for the acceleration of Diffusion SR without any extra training cost. TSS combines Time Dynamic Sampling (TDS), which allocates more iterations to refining textures, and Spatial Dynamic Sampling (SDS), which dynamically adjusts strategies based on image content. Extensive evaluations across multiple benchmarks demonstrate that TSS achieves state-of-the-art (SOTA) performance with significantly fewer iterations, improving MUSIQ scores by 0.2 - 3.0 and outperforming the current acceleration methods with only half the number of steps.
FSL-LVLM: Friction-Aware Safety Locomotion using Large Vision Language Model in Wheeled Robots
Sep 15, 2024



Wheeled-legged robots offer significant mobility and versatility but face substantial challenges when operating on slippery terrains. Traditional model-based controllers for these robots assume no slipping. While reinforcement learning (RL) helps quadruped robots adapt to different surfaces, recovering from slips remains challenging, especially for systems with few contact points. Estimating the ground friction coefficient is another open challenge. In this paper, we propose a novel friction-aware safety locomotion framework that integrates Large Vision Language Models (LVLMs) with a RL policy. Our approach explicitly incorporates the estimated friction coefficient into the RL policy, enabling the robot to adapt its behavior in advance based on the surface type before reaching it. We introduce a Friction-From-Vision (FFV) module, which leverages LVLMs to estimate ground friction coefficients, eliminating the need for large datasets and extensive training. The framework was validated on a customized wheeled inverted pendulum, and experimental results demonstrate that our framework increases the success rate in completing driving tasks by adjusting speed according to terrain type, while achieving better tracking performance compared to baseline methods. Our framework can be simply integrated with any other RL policies.
CapS-Adapter: Caption-based MultiModal Adapter in Zero-Shot Classification
May 26, 2024



Recent advances in vision-language foundational models, such as CLIP, have demonstrated significant strides in zero-shot classification. However, the extensive parameterization of models like CLIP necessitates a resource-intensive fine-tuning process. In response, TIP-Adapter and SuS-X have introduced training-free methods aimed at bolstering the efficacy of downstream tasks. While these approaches incorporate support sets to maintain data distribution consistency between knowledge cache and test sets, they often fall short in terms of generalization on the test set, particularly when faced with test data exhibiting substantial distributional variations. In this work, we present CapS-Adapter, an innovative method that employs a caption-based support set, effectively harnessing both image and caption features to exceed existing state-of-the-art techniques in training-free scenarios. CapS-Adapter adeptly constructs support sets that closely mirror target distributions, utilizing instance-level distribution features extracted from multimodal large models. By leveraging CLIP's single and cross-modal strengths, CapS-Adapter enhances predictive accuracy through the use of multimodal support sets. Our method achieves outstanding zero-shot classification results across 19 benchmark datasets, improving accuracy by 2.19\% over the previous leading method. Our contributions are substantiated through extensive validation on multiple benchmark datasets, demonstrating superior performance and robust generalization capabilities. Our code is made publicly available at https://github.com/WLuLi/CapS-Adapter.