 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicEraser: Erasing Any Objects via Semantics-Aware Control
Oct 14, 2024The traditional image inpainting task aims to restore corrupted regions by referencing surrounding background and foreground. However, the object erasure task, which is in increasing demand, aims to erase objects and generate harmonious background. Previous GAN-based inpainting methods struggle with intricate texture generation. Emerging diffusion model-based algorithms, such as Stable Diffusion Inpainting, exhibit the capability to generate novel content, but they often produce incongruent results at the locations of the erased objects and require high-quality text prompt inputs. To address these challenges, we introduce MagicEraser, a diffusion model-based framework tailored for the object erasure task. It consists of two phases: content initialization and controllable generation. In the latter phase, we develop two plug-and-play modules called prompt tuning and semantics-aware attention refocus. Additionally, we propose a data construction strategy that generates training data specially suitable for this task. MagicEraser achieves fine and effective control of content generation while mitigating undesired artifacts. Experimental results highlight a valuable advancement of our approach in the object erasure task.
EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
Aug 01, 2024



We present a novel approach for synthesizing 3D talking heads with controllable emotion, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a \textit{`Speech-to-Geometry-to-Appearance'} mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model enables controllable emotion in the generated talking heads and can be rendered in wide-range views. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset are released at https://nju-3dv.github.io/projects/EmoTalk3D.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021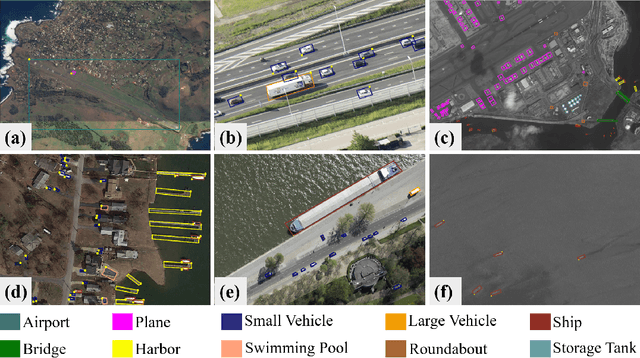

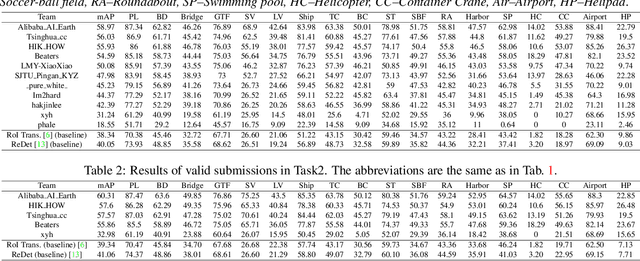
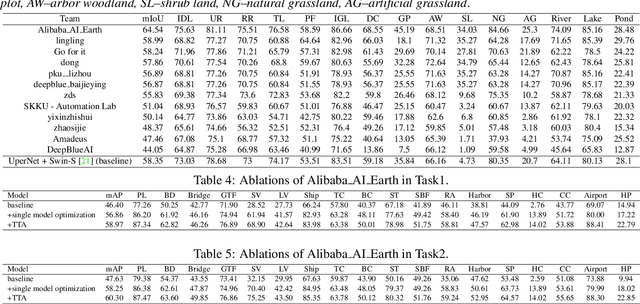
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.