 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMTNet: Dynamic Multi-scale Network for Dual-pixel Images Defocus Deblurring with Transformer
Paper and Code
Sep 13, 2022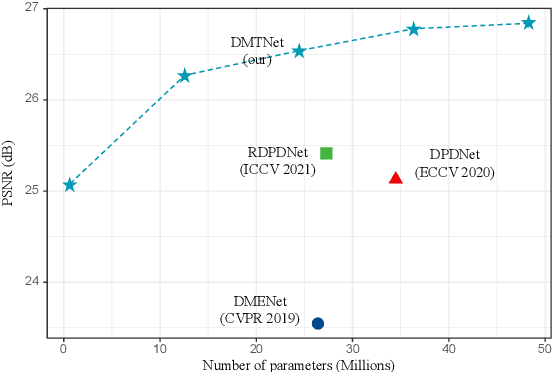



Recent works achieve excellent results in defocus deblurring task based on dual-pixel data using convolutional neural network (CNN), while the scarcity of data limits the exploration and attempt of vision transformer in this task. In addition, the existing works use fixed parameters and network architecture to deblur images with different distribution and content information, which also affects the generalization ability of the model. In this paper, we propose a dynamic multi-scale network, named DMTNet, for dual-pixel images defocus deblurring. DMTNet mainly contains two modules: feature extraction module and reconstruction module. The feature extraction module is composed of several vision transformer blocks, which uses its powerful feature extraction capability to obtain richer features and improve the robustness of the model. The reconstruction module is composed of several Dynamic Multi-scale Sub-reconstruction Module (DMSSRM). DMSSRM can restore images by adaptively assigning weights to features from different scales according to the blur distribution and content information of the input images. DMTNet combines the advantages of transformer and CNN, in which the vision transformer improves the performance ceiling of CNN, and the inductive bias of CNN enables transformer to extract more robust features without relying on a large amount of data. DMTNet might be the first attempt to use vision transformer to restore the blurring images to clarity. By combining with CNN, the vision transformer may achieve better performance on small datasets. Experimental results on the popular benchmarks demonstrate that our DMTNet significantly outperforms state-of-the-art methods.