 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Reconfigurable Intelligent Surfaces in Practical Systems: Security and Privacy Perspectives
Dec 12, 2025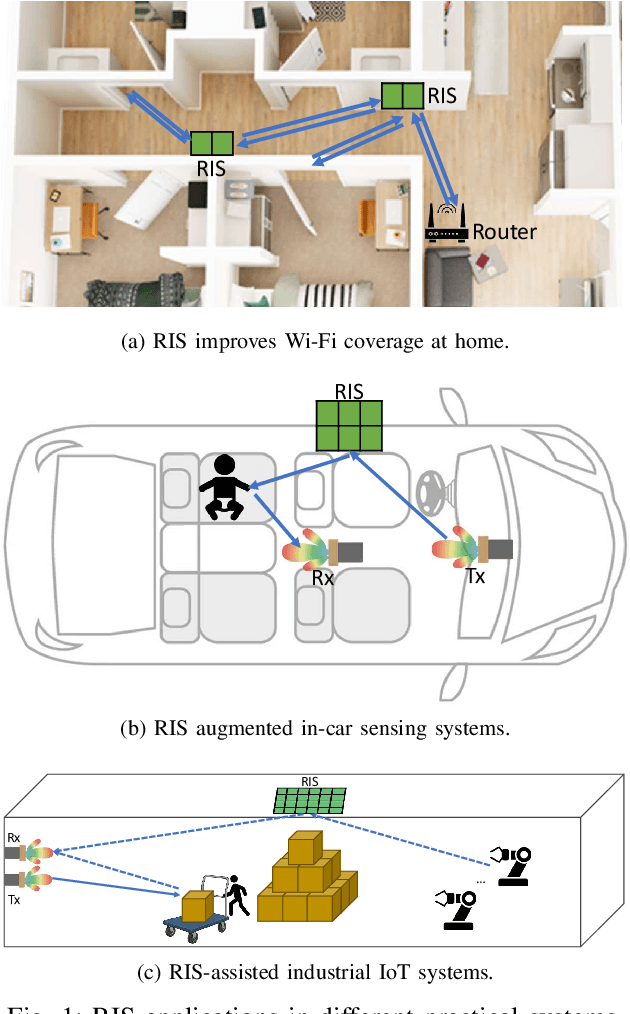
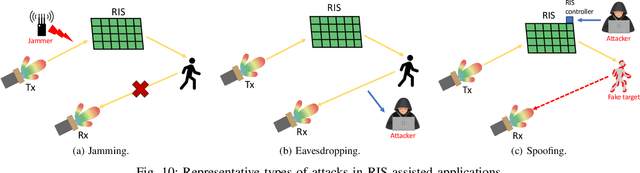
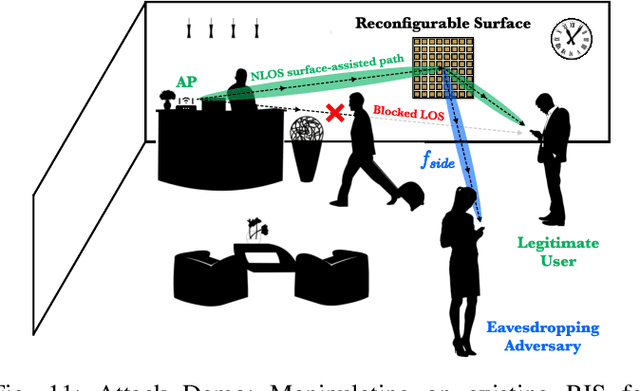
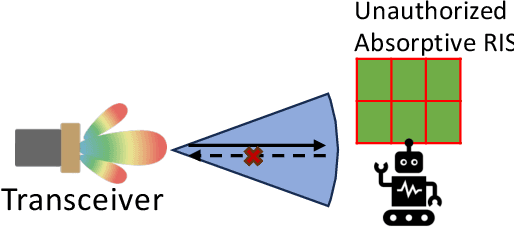
Reconfigurable Intelligent Surfaces (RIS) have emerged as a transformative technology capable of reshaping wireless environments through dynamic manipulation of electromagnetic waves. While extensive research has explored their theoretical benefits for communication and sensing, practical deployments in smart environments such as homes, vehicles, and industrial settings remain limited and under-examined, particularly from security and privacy perspectives. This survey provides a comprehensive examination of RIS applications in real-world systems, with a focus on the security and privacy threats, vulnerabilities, and defensive strategies relevant to practical use. We analyze scenarios with two types of systems (with and without legitimate RIS) and two types of attackers (with and without malicious RIS), and demonstrate how RIS may introduce new attacks to practical systems, including eavesdropping, jamming, and spoofing attacks. In response, we review defenses against RIS-related attacks in these systems, such as applying additional security algorithms, disrupting attackers, and early detection of unauthorized RIS. We also discuss scenarios in which the legitimate user applies an additional RIS to defend against attacks. To support future research, we also provide a collection of open-source tools, datasets, demos, and papers at: https://awesome-ris-security.github.io/. By highlighting RIS's functionality and its security/privacy challenges and opportunities, this survey aims to guide researchers and engineers toward the development of secure, resilient, and privacy-preserving RIS-enabled practical wireless systems and environments.
Wi-Chat: Large Language Model Powered Wi-Fi Sensing
Feb 18, 2025



Recent advancements in Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks. However, their potential to integrate physical model knowledge for real-world signal interpretation remains largely unexplored. In this work, we introduce Wi-Chat, the first LLM-powered Wi-Fi-based human activity recognition system. We demonstrate that LLMs can process raw Wi-Fi signals and infer human activities by incorporating Wi-Fi sensing principles into prompts. Our approach leverages physical model insights to guide LLMs in interpreting Channel State Information (CSI) data without traditional signal processing techniques. Through experiments on real-world Wi-Fi datasets, we show that LLMs exhibit strong reasoning capabilities, achieving zero-shot activity recognition. These findings highlight a new paradigm for Wi-Fi sensing, expanding LLM applications beyond conventional language tasks and enhancing the accessibility of wireless sensing for real-world deployments.
Robust Person Identification: A WiFi Vision-based Approach
Sep 30, 2022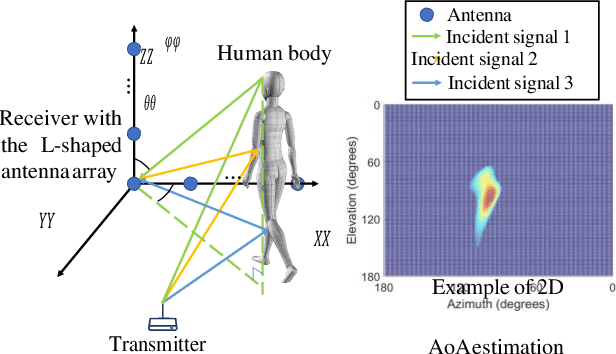
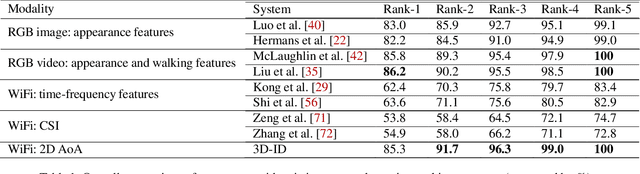
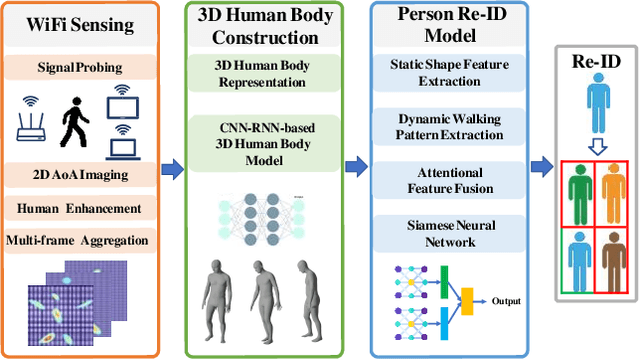
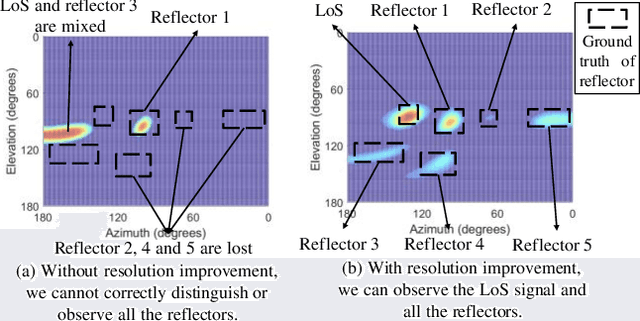
Person re-identification (Re-ID) has become increasingly important as it supports a wide range of security applications. Traditional person Re-ID mainly relies on optical camera-based systems, which incur several limitations due to the changes in the appearance of people, occlusions, and human poses. In this work, we propose a WiFi vision-based system, 3D-ID, for person Re-ID in 3D space. Our system leverages the advances of WiFi and deep learning to help WiFi devices see, identify, and recognize people. In particular, we leverage multiple antennas on next-generation WiFi devices and 2D AoA estimation of the signal reflections to enable WiFi to visualize a person in the physical environment. We then leverage deep learning to digitize the visualization of the person into 3D body representation and extract both the static body shape and dynamic walking patterns for person Re-ID. Our evaluation results under various indoor environments show that the 3D-ID system achieves an overall rank-1 accuracy of 85.3%. Results also show that our system is resistant to various attacks. The proposed 3D-ID is thus very promising as it could augment or complement camera-based systems.
3D Human Pose Estimation for Free-from and Moving Activities Using WiFi
Apr 16, 2022

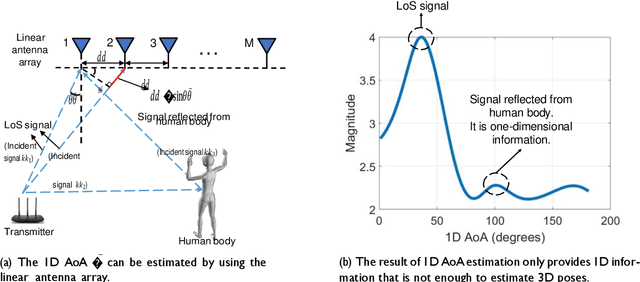
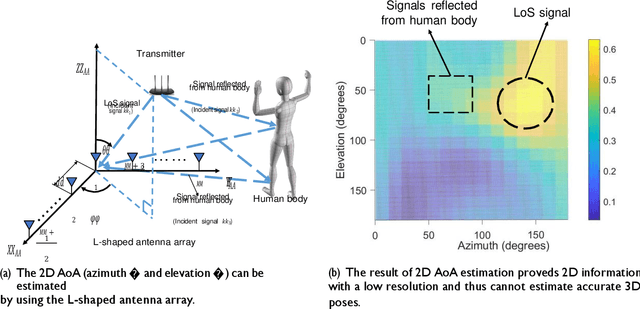
This paper presents GoPose, a 3D skeleton-based human pose estimation system that uses WiFi devices at home. Our system leverages the WiFi signals reflected off the human body for 3D pose estimation. In contrast to prior systems that need specialized hardware or dedicated sensors, our system does not require a user to wear or carry any sensors and can reuse the WiFi devices that already exist in a home environment for mass adoption. To realize such a system, we leverage the 2D AoA spectrum of the signals reflected from the human body and the deep learning techniques. In particular, the 2D AoA spectrum is proposed to locate different parts of the human body as well as to enable environment-independent pose estimation. Deep learning is incorporated to model the complex relationship between the 2D AoA spectrums and the 3D skeletons of the human body for pose tracking. Our evaluation results show GoPose achieves around 4.7cm of accuracy under various scenarios including tracking unseen activities and under NLoS scenarios.
3D Human Pose Estimation for Free-form Activity Using WiFi Signals
Oct 15, 2021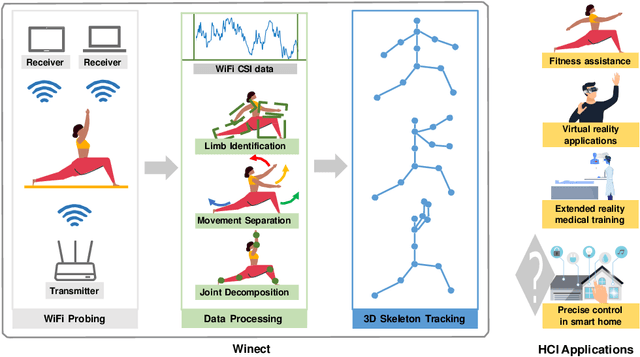
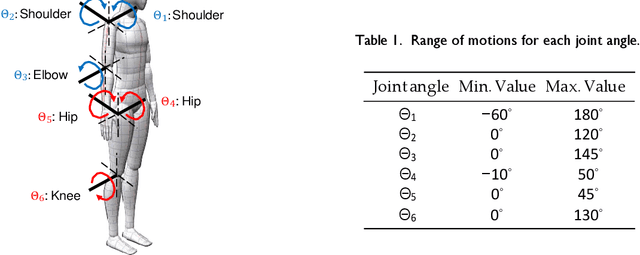
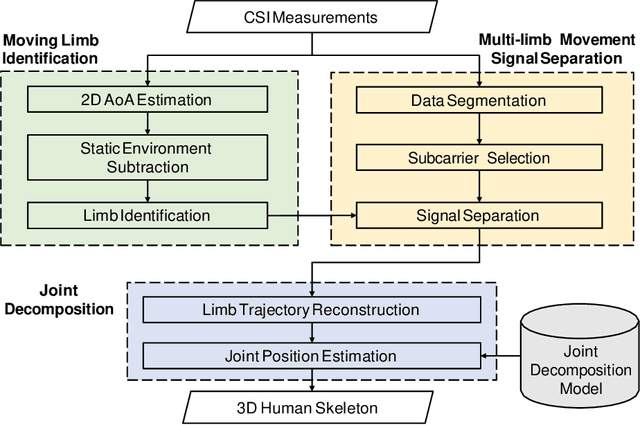

WiFi human sensing has become increasingly attractive in enabling emerging human-computer interaction applications. The corresponding technique has gradually evolved from the classification of multiple activity types to more fine-grained tracking of 3D human poses. However, existing WiFi-based 3D human pose tracking is limited to a set of predefined activities. In this work, we present Winect, a 3D human pose tracking system for free-form activity using commodity WiFi devices. Our system tracks free-form activity by estimating a 3D skeleton pose that consists of a set of joints of the human body. In particular, we combine signal separation and joint movement modeling to achieve free-form activity tracking. Our system first identifies the moving limbs by leveraging the two-dimensional angle of arrival of the signals reflected off the human body and separates the entangled signals for each limb. Then, it tracks each limb and constructs a 3D skeleton of the body by modeling the inherent relationship between the movements of the limb and the corresponding joints. Our evaluation results show that Winect is environment-independent and achieves centimeter-level accuracy for free-form activity tracking under various challenging environments including the none-line-of-sight (NLoS) scenarios.
Liquid Sensing Using WiFi Signals
Jun 18, 2021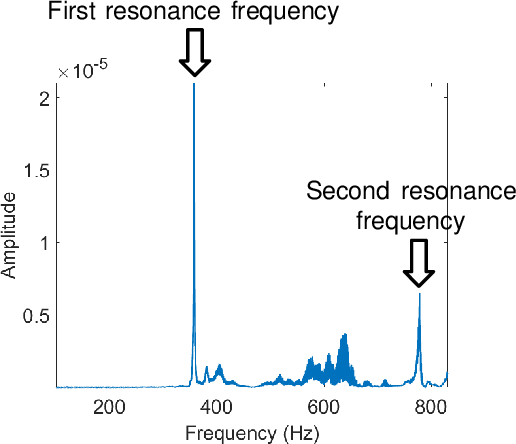

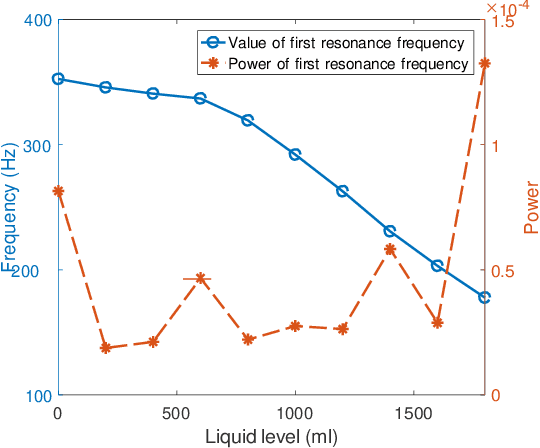

The popularity of Internet-of-Things (IoT) has provided us with unprecedented opportunities to enable a variety of emerging services in a smart home environment. Among those services, sensing the liquid level in a container is critical to building many smart home and mobile healthcare applications that improve the quality of life. This paper presents LiquidSense, a liquid-level sensing system that is low-cost, high accuracy, widely applicable to different daily liquids and containers, and can be easily integrated with existing smart home networks. LiquidSense uses an existing home WiFi network and a low-cost transducer that attached to the container to sense the resonance of the container for liquid level detection. In particular, our system mounts a low-cost transducer on the surface of the container and emits a well-designed chirp signal to make the container resonant, which introduces subtle changes to the home WiFi signals. By analyzing the subtle phase changes of the WiFi signals, LiquidSense extracts the resonance frequency as a feature for liquid level detection. Our system constructs prediction models for both continuous and discrete predictions using curve fitting and SVM respectively. We evaluate LiquidSense in home environments with containers of three different materials and six types of liquids. Results show that LiquidSense achieves an overall accuracy of 97% for continuous prediction and an overall F-score of 0.968 for discrete prediction. Results also show that our system has a large coverage in a home environment and works well under non-line-of-sight (NLOS) scenarios.