 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedOBD: Opportunistic Block Dropout for Efficiently Training Large-scale Neural Networks through Federated Learning
Paper and Code
Aug 10, 2022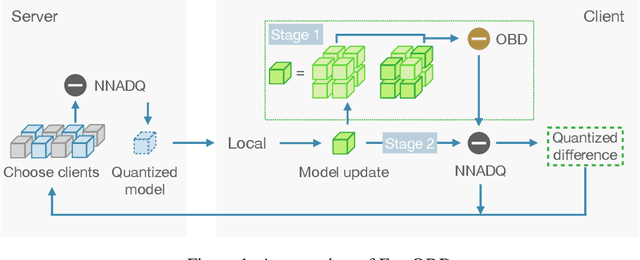
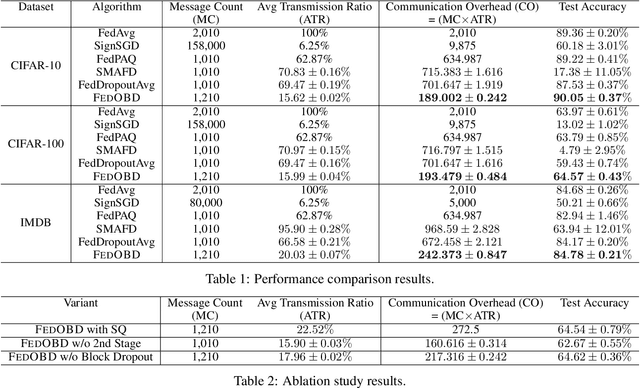
Large-scale neural networks possess considerable expressive power. They are well-suited for complex learning tasks in industrial applications. However, large-scale models pose significant challenges for training under the current Federated Learning (FL) paradigm. Existing approaches for efficient FL training often leverage model parameter dropout. However, manipulating individual model parameters is not only inefficient in meaningfully reducing the communication overhead when training large-scale FL models, but may also be detrimental to the scaling efforts and model performance as shown by recent research. To address these issues, we propose the Federated Opportunistic Block Dropout (FedOBD) approach. The key novelty is that it decomposes large-scale models into semantic blocks so that FL participants can opportunistically upload quantized blocks, which are deemed to be significant towards training the model, to the FL server for aggregation. Extensive experiments evaluating FedOBD against five state-of-the-art approaches based on multiple real-world datasets show that it reduces the overall communication overhead by more than 70% compared to the best performing baseline approach, while achieving the highest test accuracy. To the best of our knowledge, FedOBD is the first approach to perform dropout on FL models at the block level rather than at the individual parameter level.