 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Long-term Autonomy: A Perspective from Robot Learning
Jan 02, 2023In the future, service robots are expected to be able to operate autonomously for long periods of time without human intervention. Many work striving for this goal have been emerging with the development of robotics, both hardware and software. Today we believe that an important underpinning of long-term robot autonomy is the ability of robots to learn on site and on-the-fly, especially when they are deployed in changing environments or need to traverse different environments. In this paper, we examine the problem of long-term autonomy from the perspective of robot learning, especially in an online way, and discuss in tandem its premise "data" and the subsequent "deployment".
NDT-Transformer: Large-Scale 3D Point Cloud Localisation using the Normal Distribution Transform Representation
Mar 23, 2021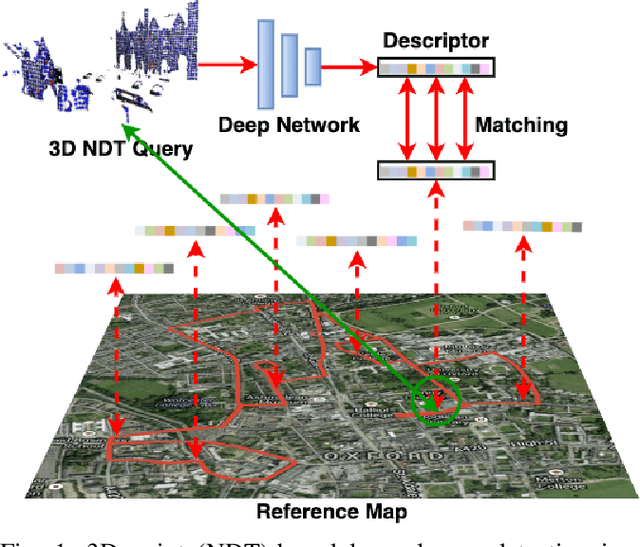

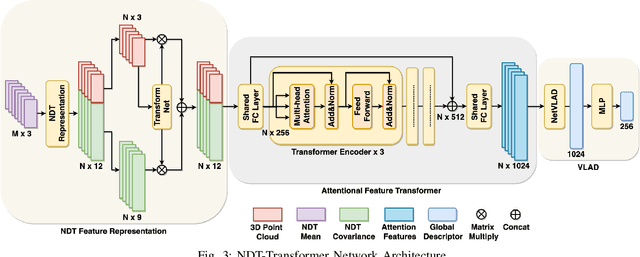
3D point cloud-based place recognition is highly demanded by autonomous driving in GPS-challenged environments and serves as an essential component (i.e. loop-closure detection) in lidar-based SLAM systems. This paper proposes a novel approach, named NDT-Transformer, for realtime and large-scale place recognition using 3D point clouds. Specifically, a 3D Normal Distribution Transform (NDT) representation is employed to condense the raw, dense 3D point cloud as probabilistic distributions (NDT cells) to provide the geometrical shape description. Then a novel NDT-Transformer network learns a global descriptor from a set of 3D NDT cell representations. Benefiting from the NDT representation and NDT-Transformer network, the learned global descriptors are enriched with both geometrical and contextual information. Finally, descriptor retrieval is achieved using a query-database for place recognition. Compared to the state-of-the-art methods, the proposed approach achieves an improvement of 7.52% on average top 1 recall and 2.73% on average top 1% recall on the Oxford Robotcar benchmark.
Localising Faster: Efficient and precise lidar-based robot localisation in large-scale environments
Mar 04, 2020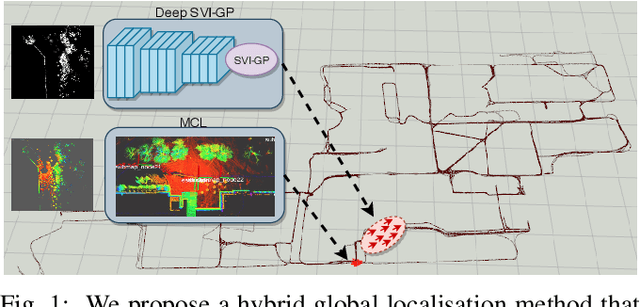
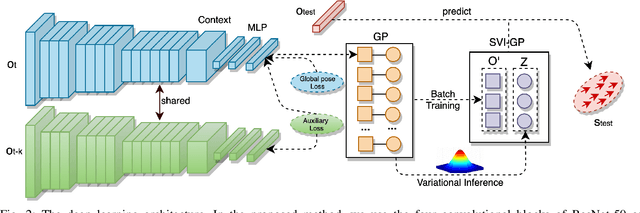
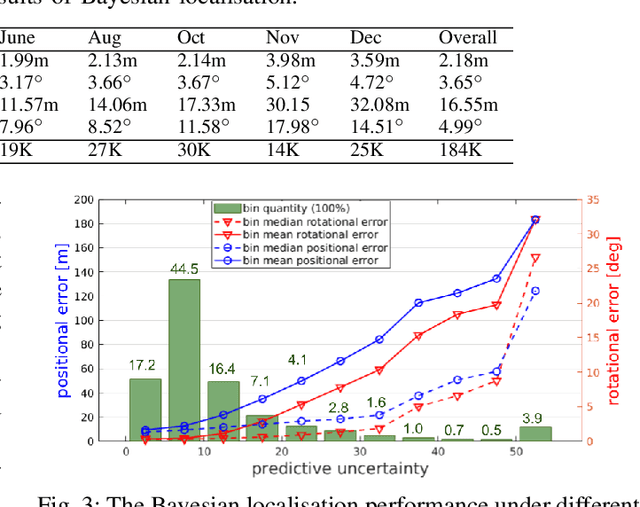
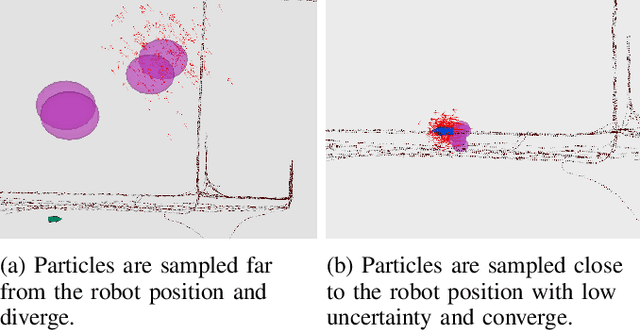
This paper proposes a novel approach for global localisation of mobile robots in large-scale environments. Our method leverages learning-based localisation and filtering-based localisation, to localise the robot efficiently and precisely through seeding Monte Carlo Localisation (MCL) with a deep-learned distribution. In particular, a fast localisation system rapidly estimates the 6-DOF pose through a deep-probabilistic model (Gaussian Process Regression with a deep kernel), then a precise recursive estimator refines the estimated robot pose according to the geometric alignment. More importantly, the Gaussian method (i.e. deep probabilistic localisation) and non-Gaussian method (i.e. MCL) can be integrated naturally via importance sampling. Consequently, the two systems can be integrated seamlessly and mutually benefit from each other. To verify the proposed framework, we provide a case study in large-scale localisation with a 3D lidar sensor. Our experiments on the Michigan NCLT long-term dataset show that the proposed method is able to localise the robot in 1.94 s on average (median of 0.8 s) with precision 0.75~m in a large-scale environment of approximately 0.5 km2.
Robot Perception of Static and Dynamic Objects with an Autonomous Floor Scrubber
Feb 24, 2020

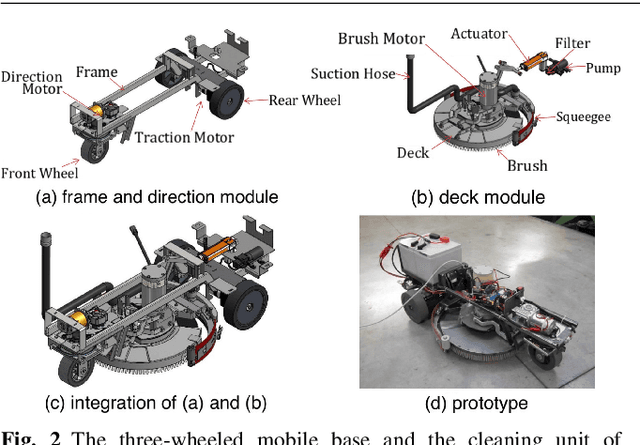
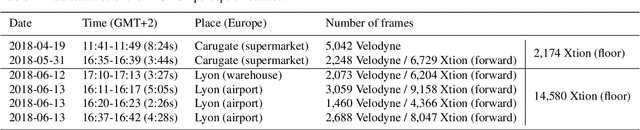
This paper presents the perception system of a new professional cleaning robot for large public places. The proposed system is based on multiple sensors including 3D and 2D lidar, two RGB-D cameras and a stereo camera. The two lidars together with an RGB-D camera are used for dynamic object (human) detection and tracking, while the second RGB-D and stereo camera are used for detection of static objects (dirt and ground objects). A learning and reasoning module for spatial-temporal representation of the environment based on the perception pipeline is also introduced. Furthermore, a new dataset collected with the robot in several public places, including a supermarket, a warehouse and an airport, is released. Baseline results on this dataset for further research and comparison are provided. The proposed system has been fully implemented into the Robot Operating System (ROS) with high modularity, also publicly available to the community.
Kriging-Based Robotic Exploration for Soil Moisture Mapping Using a Cosmic-Ray Sensor
Nov 13, 2018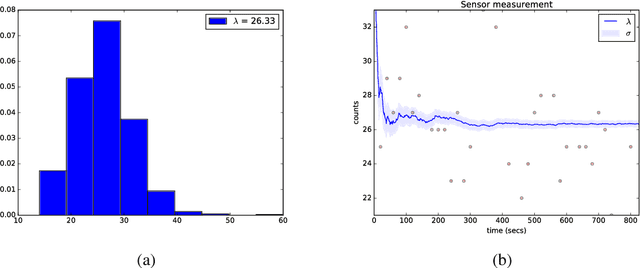
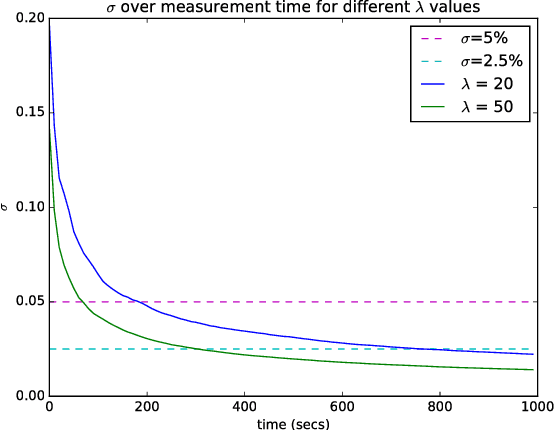

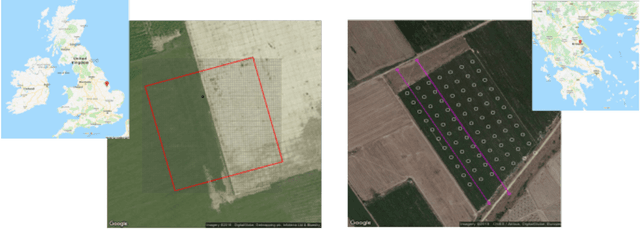
Soil moisture monitoring is a fundamental process to enhance agricultural outcomes and to protect the environment. The traditional methods for measuring moisture content in soil are laborious and expensive, and therefore there is a growing interest in developing sensors and technologies which can reduce the effort and costs. In this work, we propose to use an autonomous mobile robot equipped with a state-of-the-art non-contact soil moisture sensor that builds moisture maps on the fly and automatically selects the most optimal sampling locations. The robot is guided by an autonomous exploration strategy driven by the quality of the soil moisture model which indicates areas of the field where the information is less precise. The sensor model follows the Poisson distribution and we demonstrate how to integrate such measurements into the kriging framework. We also investigate a range of different exploration strategies and assess their usefulness through a set of evaluation experiments based on real soil moisture data collected from two different fields. We demonstrate the benefits of using the adaptive measurement interval and adaptive sampling strategies for building better quality soil moisture models. The presented method is general and can be applied to other scenarios where the measured phenomena directly affects the acquisition time and needs to be spatially mapped.
Warped Hypertime Representations for Long-term Autonomy of Mobile Robots
Oct 09, 2018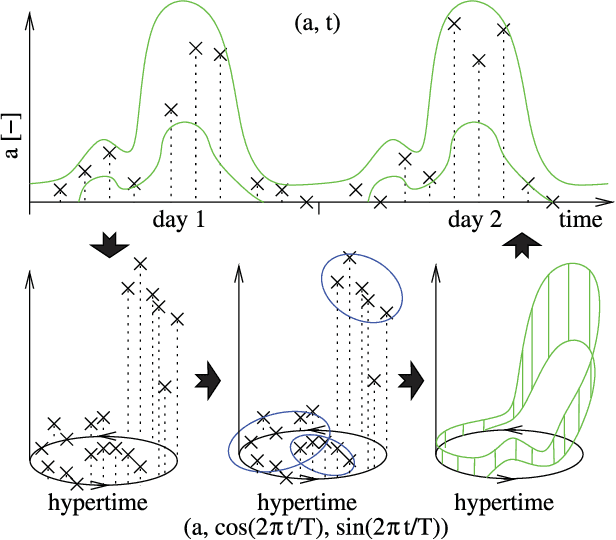
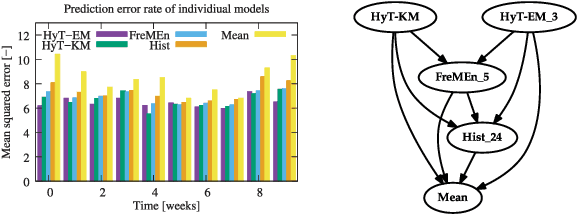
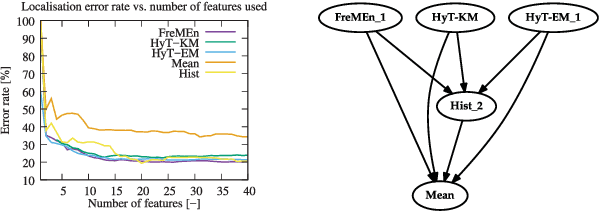
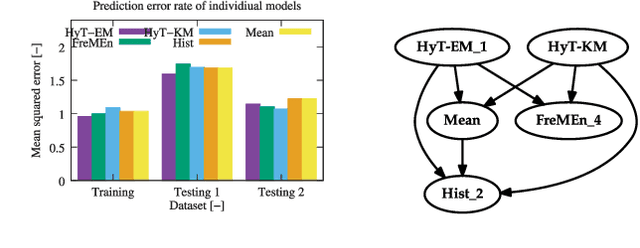
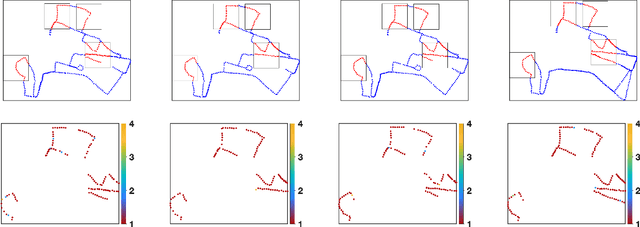
This paper presents a novel method for introducing time into discrete and continuous spatial representations used in mobile robotics, by modelling long-term, pseudo-periodic variations caused by human activities. Unlike previous approaches, the proposed method does not treat time and space separately, and its continuous nature respects both the temporal and spatial continuity of the modeled phenomena. The method extends the given spatial model with a set of wrapped dimensions that represent the periodicities of observed changes. By performing clustering over this extended representation, we obtain a model that allows us to predict future states of both discrete and continuous spatial representations. We apply the proposed algorithm to several long-term datasets and show that the method enables a robot to predict future states of repre- sentations with different dimensions. The experiments further show that the method achieves more accurate predictions than the previous state of the art.
Agricultural Robotics: The Future of Robotic Agriculture
Aug 02, 2018Agri-Food is the largest manufacturing sector in the UK. It supports a food chain that generates over {\pounds}108bn p.a., with 3.9m employees in a truly international industry and exports {\pounds}20bn of UK manufactured goods. However, the global food chain is under pressure from population growth, climate change, political pressures affecting migration, population drift from rural to urban regions and the demographics of an aging global population. These challenges are recognised in the UK Industrial Strategy white paper and backed by significant investment via a Wave 2 Industrial Challenge Fund Investment ("Transforming Food Production: from Farm to Fork"). Robotics and Autonomous Systems (RAS) and associated digital technologies are now seen as enablers of this critical food chain transformation. To meet these challenges, this white paper reviews the state of the art in the application of RAS in Agri-Food production and explores research and innovation needs to ensure these technologies reach their full potential and deliver the necessary impacts in the Agri-Food sector.
Multisensor Online Transfer Learning for 3D LiDAR-based Human Detection with a Mobile Robot
Jul 31, 2018
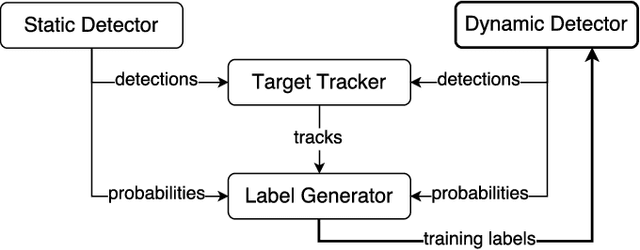
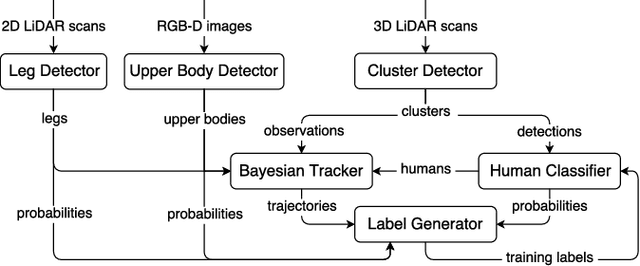

Human detection and tracking is an essential task for service robots, where the combined use of multiple sensors has potential advantages that are yet to be exploited. In this paper, we introduce a framework allowing a robot to learn a new 3D LiDAR-based human classifier from other sensors over time, taking advantage of a multisensor tracking system. The main innovation is the use of different detectors for existing sensors (i.e. RGB-D camera, 2D LiDAR) to train, online, a new 3D LiDAR-based human classifier, exploiting a so-called trajectory probability. Our framework uses this probability to check whether new detections belongs to a human trajectory, estimated by different sensors and/or detectors, and to learn a human classifier in a semi-supervised fashion. The framework has been implemented and tested on a real-world dataset collected by a mobile robot. We present experiments illustrating that our system is able to effectively learn from different sensors and from the environment, and that the performance of the 3D LiDAR-based human classification improves with the number of sensors/detectors used.
Recurrent-OctoMap: Learning State-based Map Refinement for Long-Term Semantic Mapping with 3D-Lidar Data
Jul 29, 2018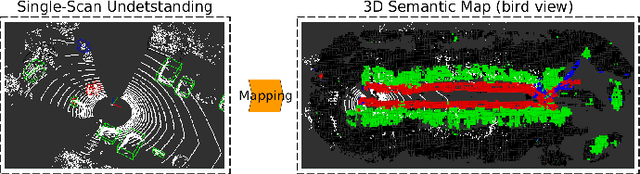

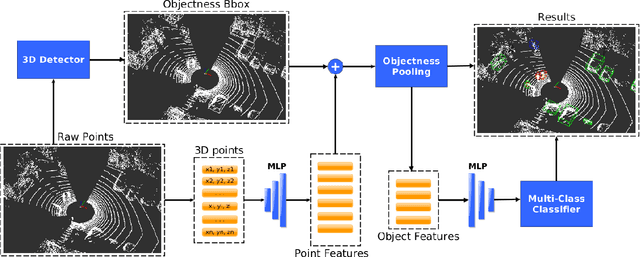
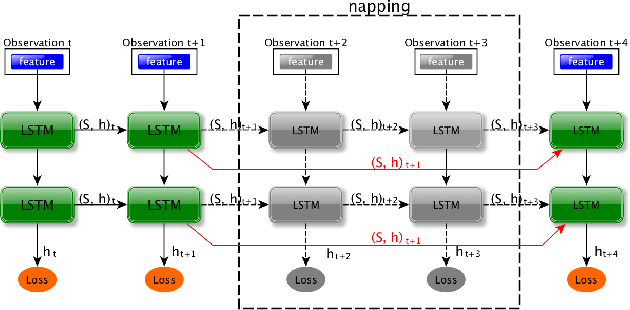
This paper presents a novel semantic mapping approach, Recurrent-OctoMap, learned from long-term 3D Lidar data. Most existing semantic mapping approaches focus on improving semantic understanding of single frames, rather than 3D refinement of semantic maps (i.e. fusing semantic observations). The most widely-used approach for 3D semantic map refinement is a Bayesian update, which fuses the consecutive predictive probabilities following a Markov-Chain model. Instead, we propose a learning approach to fuse the semantic features, rather than simply fusing predictions from a classifier. In our approach, we represent and maintain our 3D map as an OctoMap, and model each cell as a recurrent neural network (RNN), to obtain a Recurrent-OctoMap. In this case, the semantic mapping process can be formulated as a sequence-to-sequence encoding-decoding problem. Moreover, in order to extend the duration of observations in our Recurrent-OctoMap, we developed a robust 3D localization and mapping system for successively mapping a dynamic environment using more than two weeks of data, and the system can be trained and deployed with arbitrary memory length. We validate our approach on the ETH long-term 3D Lidar dataset [1]. The experimental results show that our proposed approach outperforms the conventional "Bayesian update" approach.
Learning monocular visual odometry with dense 3D mapping from dense 3D flow
Jul 25, 2018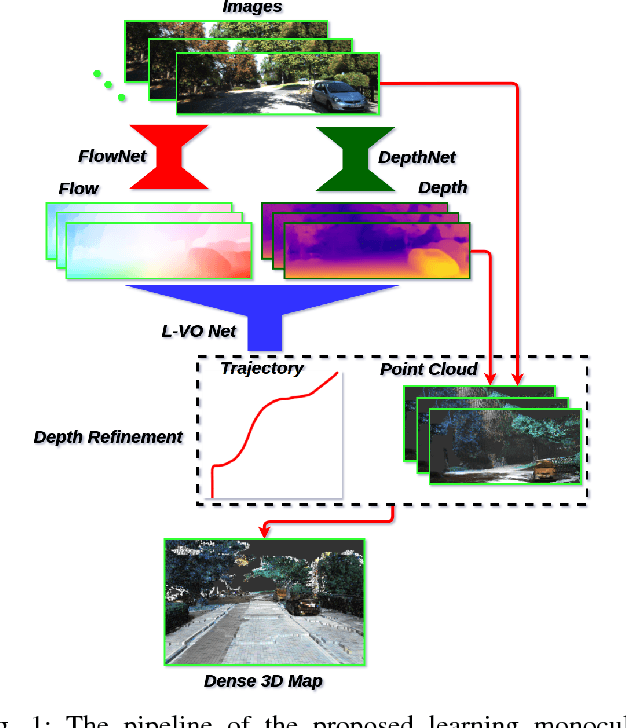
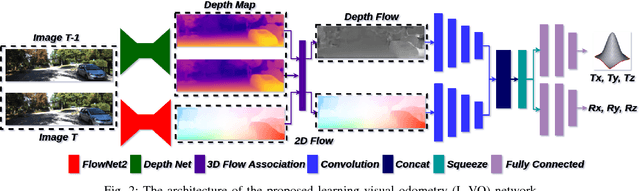
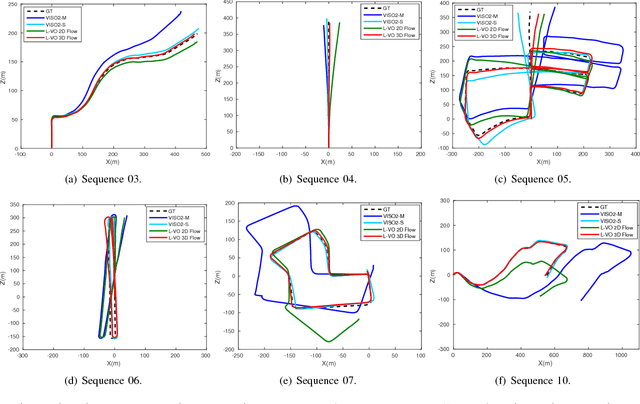
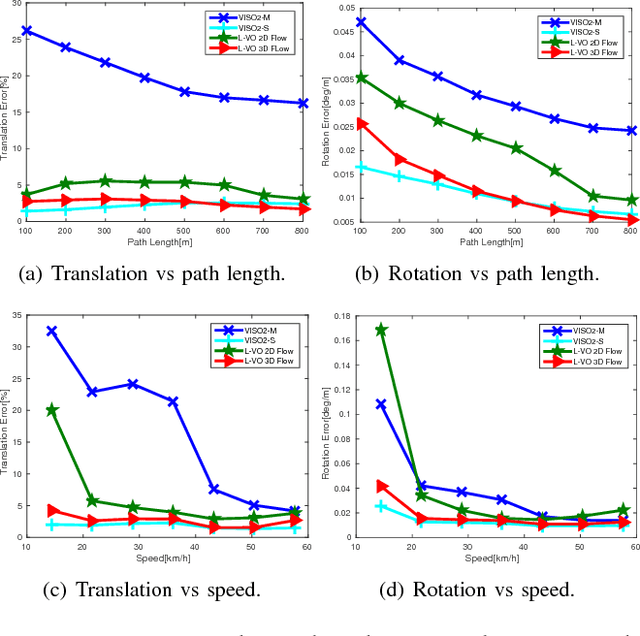
This paper introduces a fully deep learning approach to monocular SLAM, which can perform simultaneous localization using a neural network for learning visual odometry (L-VO) and dense 3D mapping. Dense 2D flow and a depth image are generated from monocular images by sub-networks, which are then used by a 3D flow associated layer in the L-VO network to generate dense 3D flow. Given this 3D flow, the dual-stream L-VO network can then predict the 6DOF relative pose and furthermore reconstruct the vehicle trajectory. In order to learn the correlation between motion directions, the Bivariate Gaussian modelling is employed in the loss function. The L-VO network achieves an overall performance of 2.68% for average translational error and 0.0143 deg/m for average rotational error on the KITTI odometry benchmark. Moreover, the learned depth is fully leveraged to generate a dense 3D map. As a result, an entire visual SLAM system, that is, learning monocular odometry combined with dense 3D mapping, is achieved.
* International Conference on Intelligent Robots and Systems(IROS 2018)