 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStraightLine: An End-to-End Resource-Aware Scheduler for Machine Learning Application Requests
Jul 25, 2024



The life cycle of machine learning (ML) applications consists of two stages: model development and model deployment. However, traditional ML systems (e.g., training-specific or inference-specific systems) focus on one particular stage or phase of the life cycle of ML applications. These systems often aim at optimizing model training or accelerating model inference, and they frequently assume homogeneous infrastructure, which may not always reflect real-world scenarios that include cloud data centers, local servers, containers, and serverless platforms. We present StraightLine, an end-to-end resource-aware scheduler that schedules the optimal resources (e.g., container, virtual machine, or serverless) for different ML application requests in a hybrid infrastructure. The key innovation is an empirical dynamic placing algorithm that intelligently places requests based on their unique characteristics (e.g., request frequency, input data size, and data distribution). In contrast to existing ML systems, StraightLine offers end-to-end resource-aware placement, thereby it can significantly reduce response time and failure rate for model deployment when facing different computing resources in the hybrid infrastructure.
Improving CNN-base Stock Trading By Considering Data Heterogeneity and Burst
Mar 14, 2023
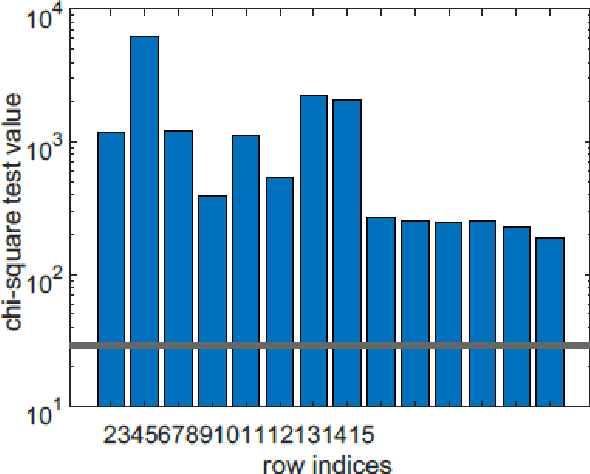
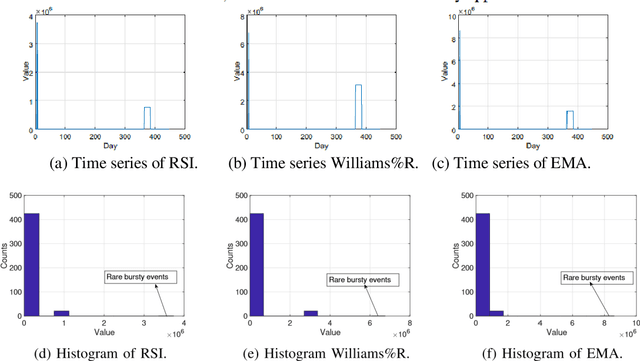

In recent years, there have been quite a few attempts to apply intelligent techniques to financial trading, i.e., constructing automatic and intelligent trading framework based on historical stock price. Due to the unpredictable, uncertainty and volatile nature of financial market, researchers have also resorted to deep learning to construct the intelligent trading framework. In this paper, we propose to use CNN as the core functionality of such framework, because it is able to learn the spatial dependency (i.e., between rows and columns) of the input data. However, different with existing deep learning-based trading frameworks, we develop novel normalization process to prepare the stock data. In particular, we first empirically observe that the stock data is intrinsically heterogeneous and bursty, and then validate the heterogeneity and burst nature of stock data from a statistical perspective. Next, we design the data normalization method in a way such that the data heterogeneity is preserved and bursty events are suppressed. We verify out developed CNN-based trading framework plus our new normalization method on 29 stocks. Experiment results show that our approach can outperform other comparing approaches.
Making Machine Learning Datasets and Models FAIR for HPC: A Methodology and Case Study
Nov 03, 2022



The FAIR Guiding Principles aim to improve the findability, accessibility, interoperability, and reusability of digital content by making them both human and machine actionable. However, these principles have not yet been broadly adopted in the domain of machine learning-based program analyses and optimizations for High-Performance Computing (HPC). In this paper, we design a methodology to make HPC datasets and machine learning models FAIR after investigating existing FAIRness assessment and improvement techniques. Our methodology includes a comprehensive, quantitative assessment for elected data, followed by concrete, actionable suggestions to improve FAIRness with respect to common issues related to persistent identifiers, rich metadata descriptions, license and provenance information. Moreover, we select a representative training dataset to evaluate our methodology. The experiment shows the methodology can effectively improve the dataset and model's FAIRness from an initial score of 19.1% to the final score of 83.0%.