 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Paper and Code
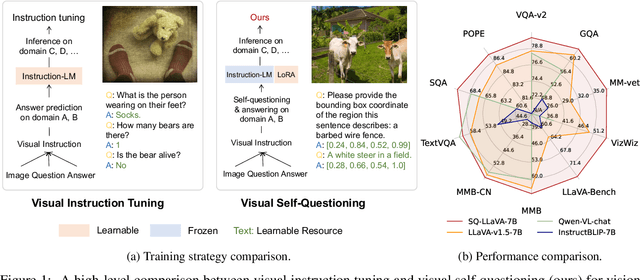
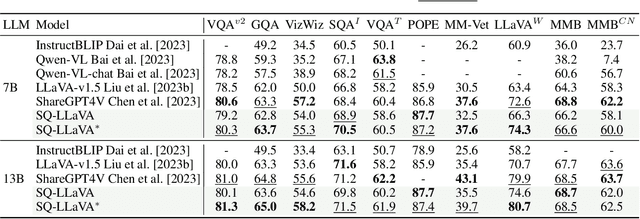
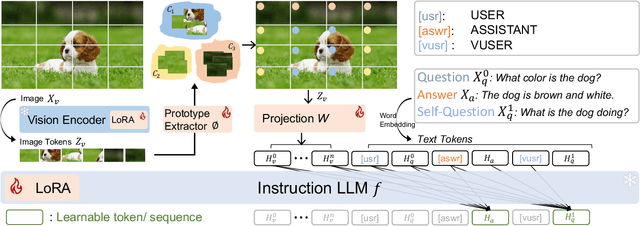
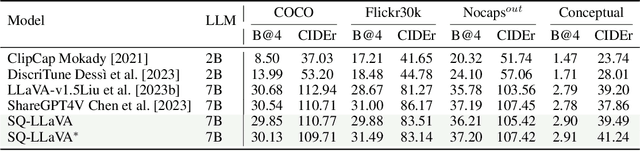
Recent advancements in the vision-language model have shown notable generalization in vision-language tasks after visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which are costly to obtain. However, the image contains rich contextual information that has been largely under-explored. This paper first attempts to harness this overlooked context within visual instruction data, training the model to self-supervised `learning' how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a consistent performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.