 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase-space entropy at acquisition reflects downstream learnability
Dec 22, 2025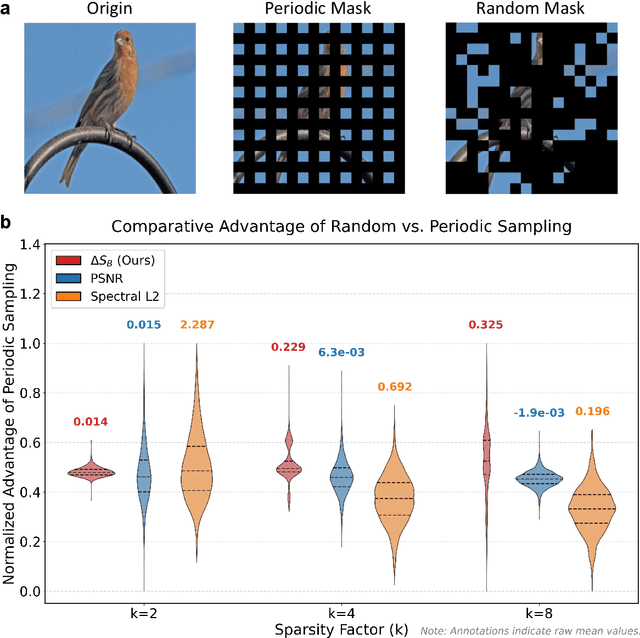
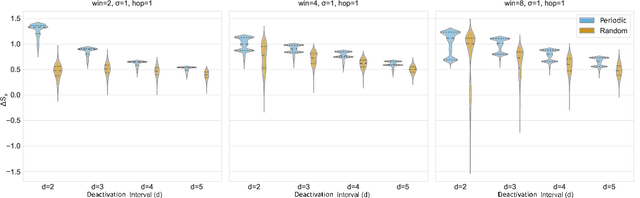
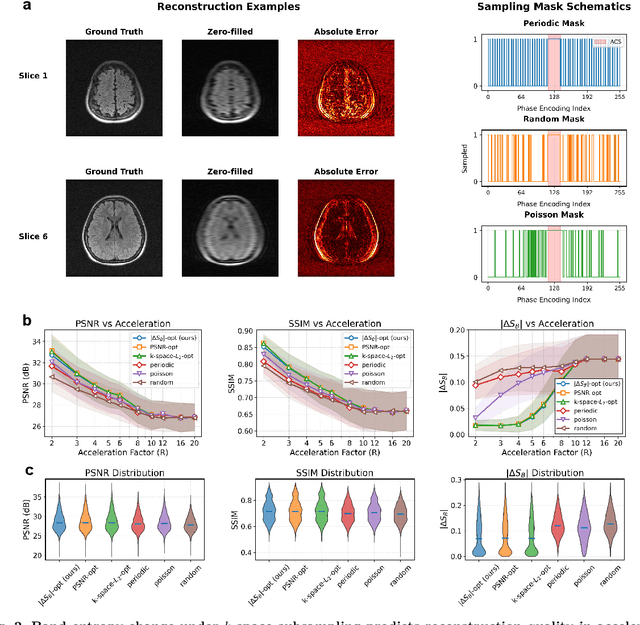

Modern learning systems work with data that vary widely across domains, but they all ultimately depend on how much structure is already present in the measurements before any model is trained. This raises a basic question: is there a general, modality-agnostic way to quantify how acquisition itself preserves or destroys the information that downstream learners could use? Here we propose an acquisition-level scalar $ΔS_{\mathcal B}$ based on instrument-resolved phase space. Unlike pixelwise distortion or purely spectral errors that often saturate under aggressive undersampling, $ΔS_{\mathcal B}$ directly quantifies how acquisition mixes or removes joint space--frequency structure at the instrument scale. We show theoretically that \(ΔS_{\mathcal B}\) correctly identifies the phase-space coherence of periodic sampling as the physical source of aliasing, recovering classical sampling-theorem consequences. Empirically, across masked image classification, accelerated MRI, and massive MIMO (including over-the-air measurements), $|ΔS_{\mathcal B}|$ consistently ranks sampling geometries and predicts downstream reconstruction/recognition difficulty \emph{without training}. In particular, minimizing $|ΔS_{\mathcal B}|$ enables zero-training selection of variable-density MRI mask parameters that matches designs tuned by conventional pre-reconstruction criteria. These results suggest that phase-space entropy at acquisition reflects downstream learnability, enabling pre-training selection of candidate sampling policies and as a shared notion of information preservation across modalities.
Is AI Robust Enough for Scientific Research?
Dec 19, 2024



We uncover a phenomenon largely overlooked by the scientific community utilizing AI: neural networks exhibit high susceptibility to minute perturbations, resulting in significant deviations in their outputs. Through an analysis of five diverse application areas -- weather forecasting, chemical energy and force calculations, fluid dynamics, quantum chromodynamics, and wireless communication -- we demonstrate that this vulnerability is a broad and general characteristic of AI systems. This revelation exposes a hidden risk in relying on neural networks for essential scientific computations, calling further studies on their reliability and security.
Symmetry Breaking in Neural Network Optimization: Insights from Input Dimension Expansion
Sep 10, 2024



Understanding the mechanisms behind neural network optimization is crucial for improving network design and performance. While various optimization techniques have been developed, a comprehensive understanding of the underlying principles that govern these techniques remains elusive. Specifically, the role of symmetry breaking, a fundamental concept in physics, has not been fully explored in neural network optimization. This gap in knowledge limits our ability to design networks that are both efficient and effective. Here, we propose the symmetry breaking hypothesis to elucidate the significance of symmetry breaking in enhancing neural network optimization. We demonstrate that a simple input expansion can significantly improve network performance across various tasks, and we show that this improvement can be attributed to the underlying symmetry breaking mechanism. We further develop a metric to quantify the degree of symmetry breaking in neural networks, providing a practical approach to evaluate and guide network design. Our findings confirm that symmetry breaking is a fundamental principle that underpins various optimization techniques, including dropout, batch normalization, and equivariance. By quantifying the degree of symmetry breaking, our work offers a practical technique for performance enhancement and a metric to guide network design without the need for complete datasets and extensive training processes.
On the uncertainty principle of neural networks
May 03, 2022
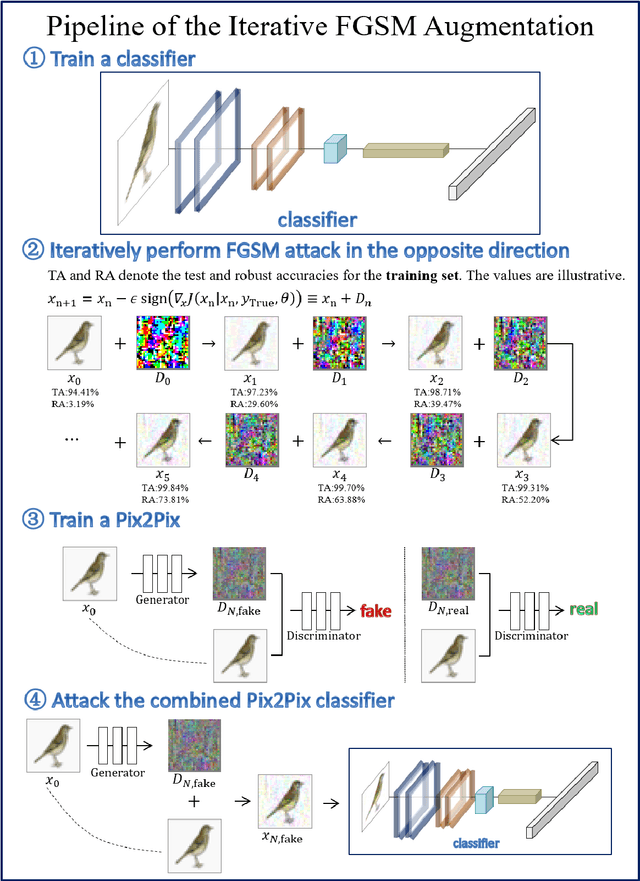
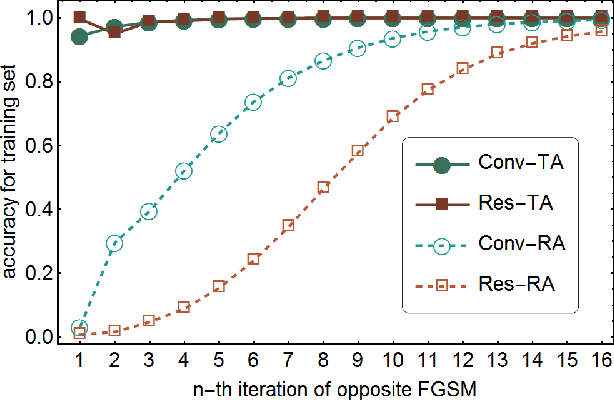
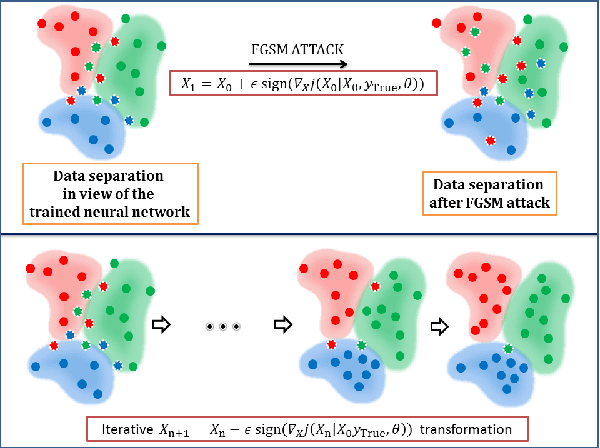
Despite the successes in many fields, it is found that neural networks are vulnerability and difficult to be both accurate and robust (robust means that the prediction of the trained network stays unchanged for inputs with non-random perturbations introduced by adversarial attacks). Various empirical and analytic studies have suggested that there is more or less a trade-off between the accuracy and robustness of neural networks. If the trade-off is inherent, applications based on the neural networks are vulnerable with untrustworthy predictions. It is then essential to ask whether the trade-off is an inherent property or not. Here, we show that the accuracy-robustness trade-off is an intrinsic property whose underlying mechanism is deeply related to the uncertainty principle in quantum mechanics. We find that for a neural network to be both accurate and robust, it needs to resolve the features of the two conjugated parts $x$ (the inputs) and $\Delta$ (the derivatives of the normalized loss function $J$ with respect to $x$), respectively. Analogous to the position-momentum conjugation in quantum mechanics, we show that the inputs and their conjugates cannot be resolved by a neural network simultaneously.
Artificial Intelligence and Machine Learning in Nuclear Physics
Dec 04, 2021
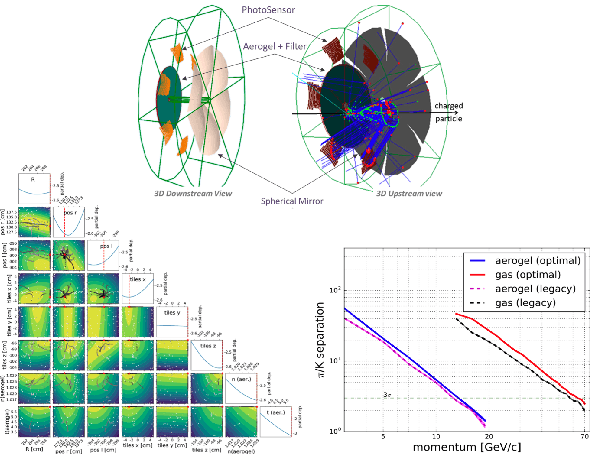
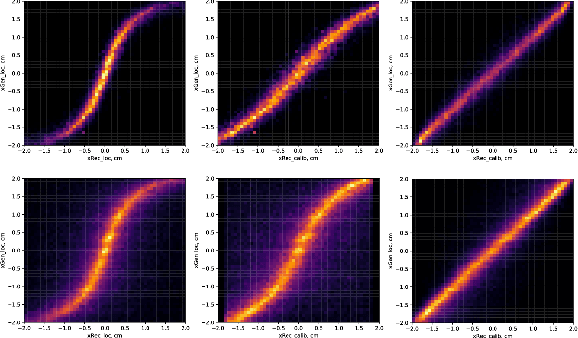
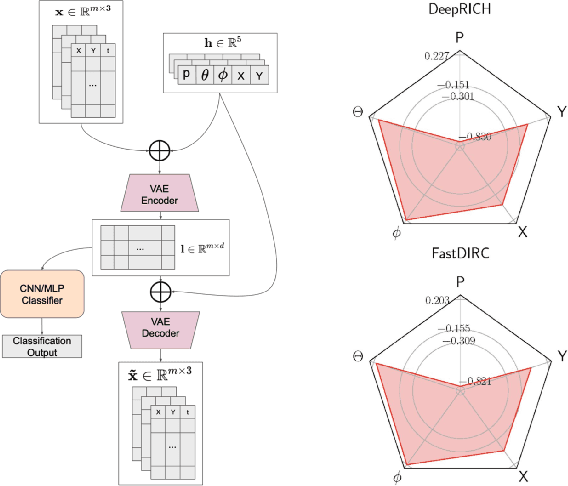
Advances in artificial intelligence/machine learning methods provide tools that have broad applicability in scientific research. These techniques are being applied across the diversity of nuclear physics research topics, leading to advances that will facilitate scientific discoveries and societal applications. This Review gives a snapshot of nuclear physics research which has been transformed by artificial intelligence and machine learning techniques.
An equation-of-state-meter of QCD transition from deep learning
Aug 02, 2017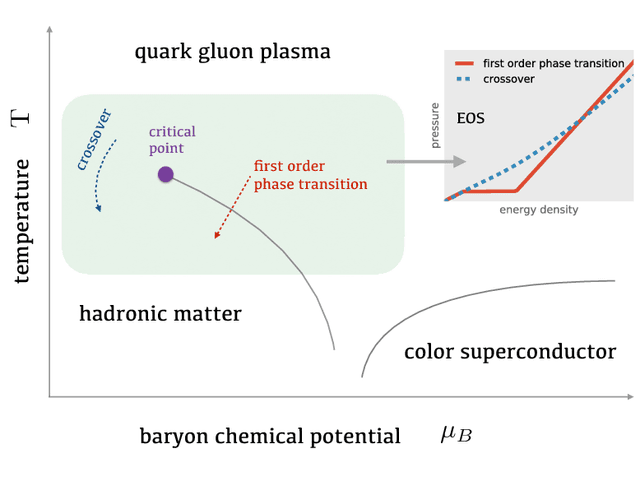
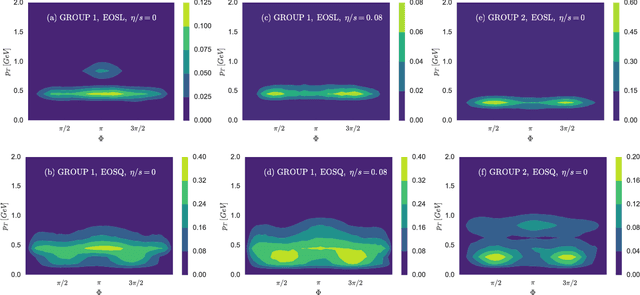
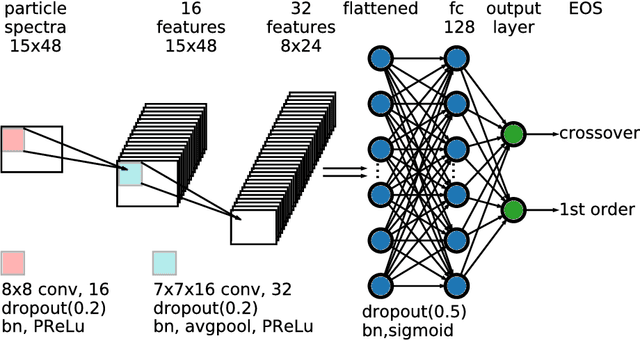
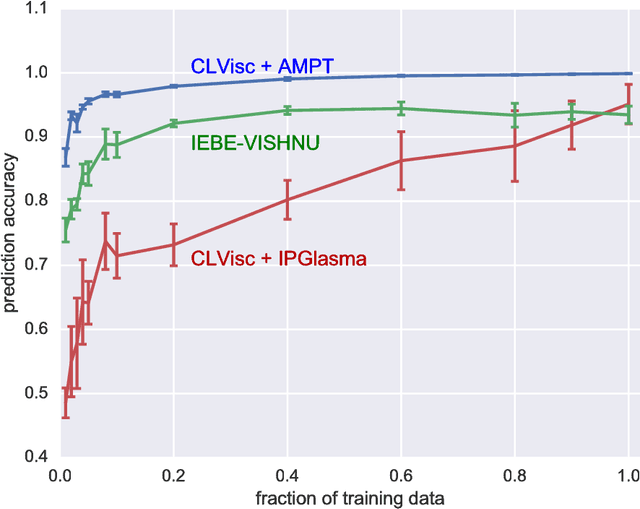
Supervised learning with a deep convolutional neural network is used to identify the QCD equation of state (EoS) employed in relativistic hydrodynamic simulations of heavy-ion collisions from the simulated final-state particle spectra $\rho(p_T,\Phi)$. High-level correlations of $\rho(p_T,\Phi)$ learned by the neural network act as an effective "EoS-meter" in detecting the nature of the QCD transition. The EoS-meter is model independent and insensitive to other simulation inputs, especially the initial conditions. Thus it provides a powerful direct-connection of heavy-ion collision observables with the bulk properties of QCD.