 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Enhanced Latent Representations for Out-of-Distribution Detection in Autonomous Driving
Paper and Code
May 02, 2024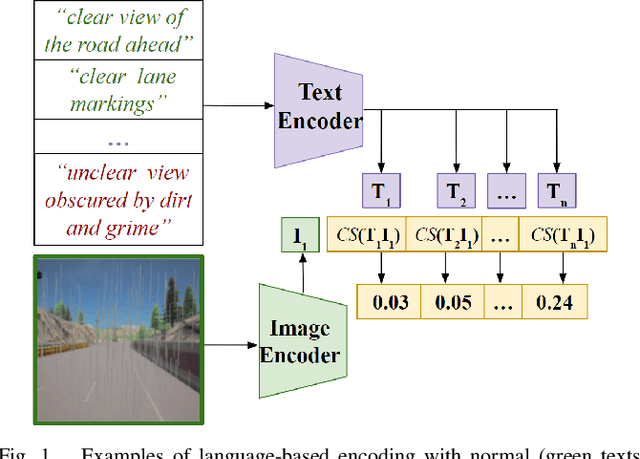


Out-of-distribution (OOD) detection is essential in autonomous driving, to determine when learning-based components encounter unexpected inputs. Traditional detectors typically use encoder models with fixed settings, thus lacking effective human interaction capabilities. With the rise of large foundation models, multimodal inputs offer the possibility of taking human language as a latent representation, thus enabling language-defined OOD detection. In this paper, we use the cosine similarity of image and text representations encoded by the multimodal model CLIP as a new representation to improve the transparency and controllability of latent encodings used for visual anomaly detection. We compare our approach with existing pre-trained encoders that can only produce latent representations that are meaningless from the user's standpoint. Our experiments on realistic driving data show that the language-based latent representation performs better than the traditional representation of the vision encoder and helps improve the detection performance when combined with standard representations.