 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Pruned Networks with Linear Over-parameterization
Paper and Code
Apr 25, 2022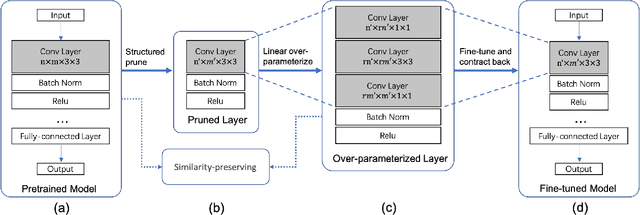
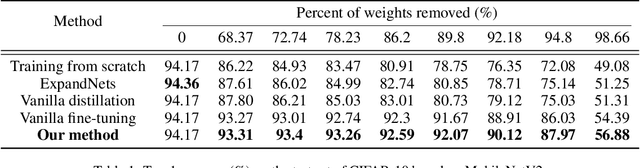
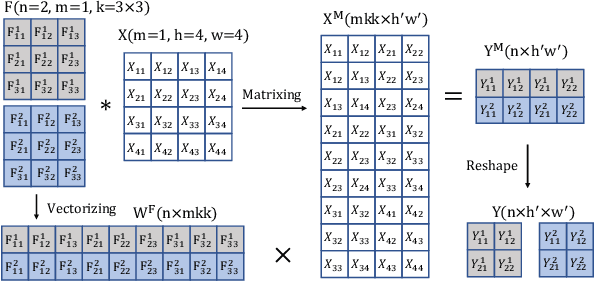
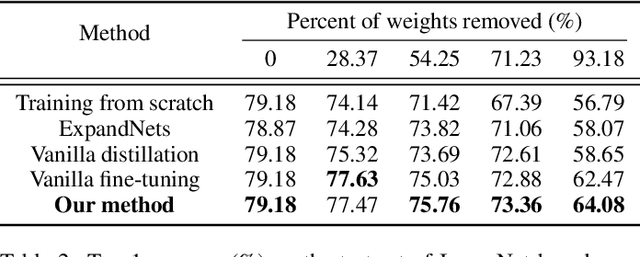
Structured pruning compresses neural networks by reducing channels (filters) for fast inference and low footprint at run-time. To restore accuracy after pruning, fine-tuning is usually applied to pruned networks. However, too few remaining parameters in pruned networks inevitably bring a great challenge to fine-tuning to restore accuracy. To address this challenge, we propose a novel method that first linearly over-parameterizes the compact layers in pruned networks to enlarge the number of fine-tuning parameters and then re-parameterizes them to the original layers after fine-tuning. Specifically, we equivalently expand the convolution/linear layer with several consecutive convolution/linear layers that do not alter the current output feature maps. Furthermore, we utilize similarity-preserving knowledge distillation that encourages the over-parameterized block to learn the immediate data-to-data similarities of the corresponding dense layer to maintain its feature learning ability. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet which significantly outperforms the vanilla fine-tuning strategy, especially for large pruning ratio.