 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLC3Net: Ladder context correlation complementary network for salient object detection
Paper and Code
Oct 21, 2021
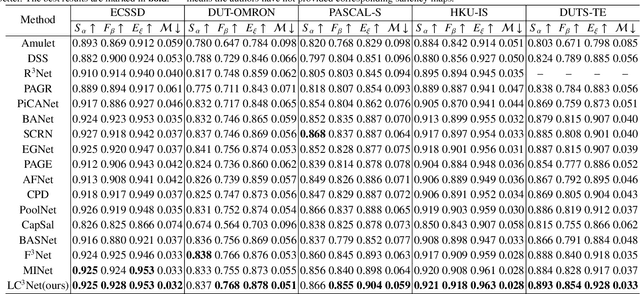
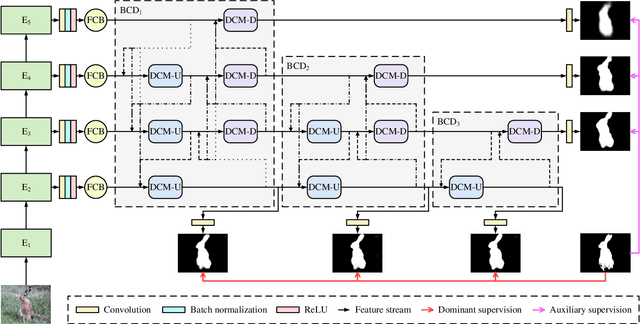
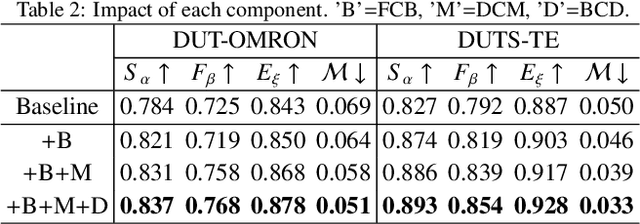
Currently, existing salient object detection methods based on convolutional neural networks commonly resort to constructing discriminative networks to aggregate high level and low level features. However, contextual information is always not fully and reasonably utilized, which usually causes either the absence of useful features or contamination of redundant features. To address these issues, we propose a novel ladder context correlation complementary network (LC3Net) in this paper, which is equipped with three crucial components. At the beginning, we propose a filterable convolution block (FCB) to assist the automatic collection of information on the diversity of initial features, and it is simple yet practical. Besides, we propose a dense cross module (DCM) to facilitate the intimate aggregation of different levels of features by validly integrating semantic information and detailed information of both adjacent and non-adjacent layers. Furthermore, we propose a bidirectional compression decoder (BCD) to help the progressive shrinkage of multi-scale features from coarse to fine by leveraging multiple pairs of alternating top-down and bottom-up feature interaction flows. Extensive experiments demonstrate the superiority of our method against 16 state-of-the-art methods.