 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupTransNet: Group Transformer Network for RGB-D Salient Object Detection
Mar 21, 2022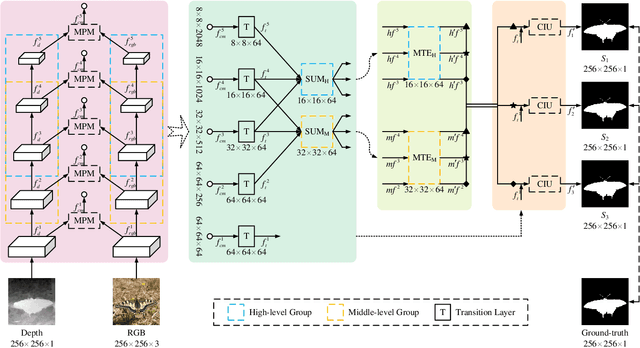
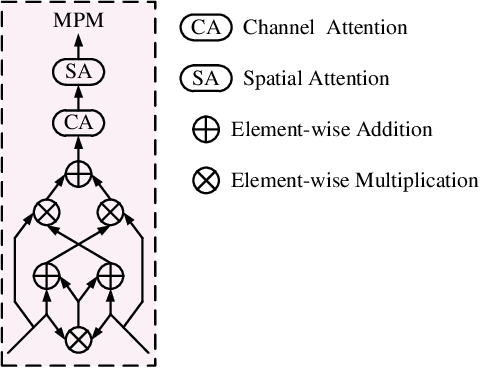
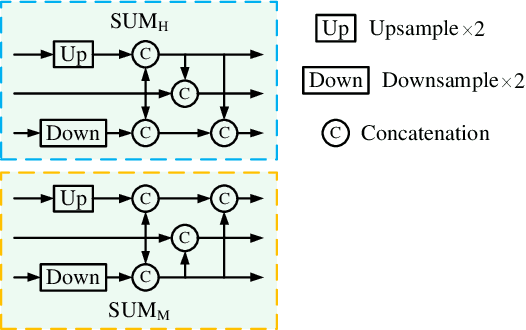
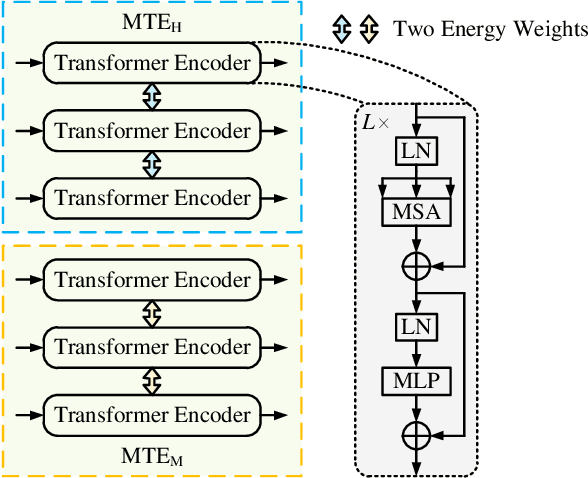
Salient object detection on RGB-D images is an active topic in computer vision. Although the existing methods have achieved appreciable performance, there are still some challenges. The locality of convolutional neural network requires that the model has a sufficiently deep global receptive field, which always leads to the loss of local details. To address the challenge, we propose a novel Group Transformer Network (GroupTransNet) for RGB-D salient object detection. This method is good at learning the long-range dependencies of cross layer features to promote more perfect feature expression. At the beginning, the features of the slightly higher classes of the middle three levels and the latter three levels are soft grouped to absorb the advantages of the high-level features. The input features are repeatedly purified and enhanced by the attention mechanism to purify the cross modal features of color modal and depth modal. The features of the intermediate process are first fused by the features of different layers, and then processed by several transformers in multiple groups, which not only makes the size of the features of each scale unified and interrelated, but also achieves the effect of sharing the weight of the features within the group. The output features in different groups complete the clustering staggered by two owing to the level difference, and combine with the low-level features. Extensive experiments demonstrate that GroupTransNet outperforms the comparison models and achieves the new state-of-the-art performance.
LC3Net: Ladder context correlation complementary network for salient object detection
Oct 21, 2021
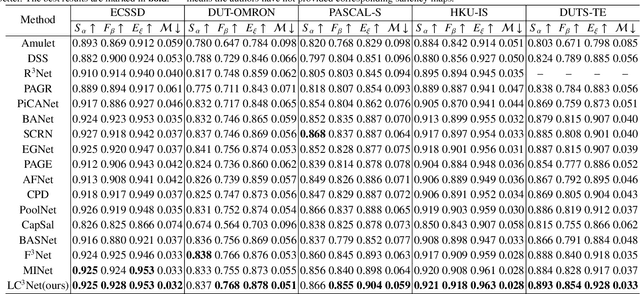
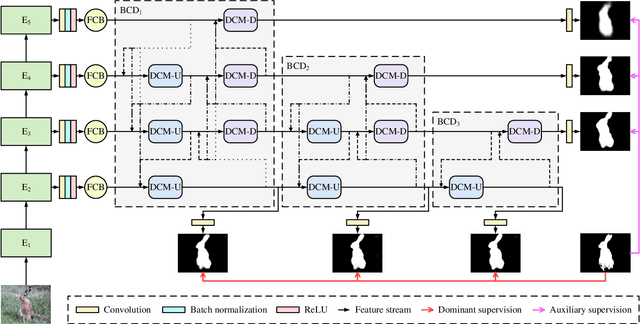
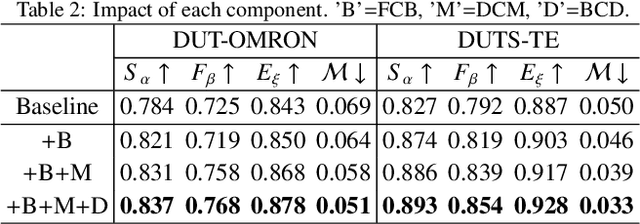
Currently, existing salient object detection methods based on convolutional neural networks commonly resort to constructing discriminative networks to aggregate high level and low level features. However, contextual information is always not fully and reasonably utilized, which usually causes either the absence of useful features or contamination of redundant features. To address these issues, we propose a novel ladder context correlation complementary network (LC3Net) in this paper, which is equipped with three crucial components. At the beginning, we propose a filterable convolution block (FCB) to assist the automatic collection of information on the diversity of initial features, and it is simple yet practical. Besides, we propose a dense cross module (DCM) to facilitate the intimate aggregation of different levels of features by validly integrating semantic information and detailed information of both adjacent and non-adjacent layers. Furthermore, we propose a bidirectional compression decoder (BCD) to help the progressive shrinkage of multi-scale features from coarse to fine by leveraging multiple pairs of alternating top-down and bottom-up feature interaction flows. Extensive experiments demonstrate the superiority of our method against 16 state-of-the-art methods.
M2RNet: Multi-modal and Multi-scale Refined Network for RGB-D Salient Object Detection
Sep 16, 2021
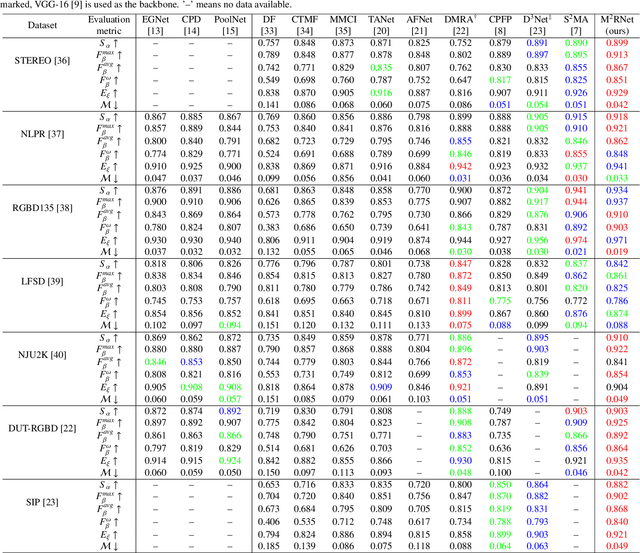
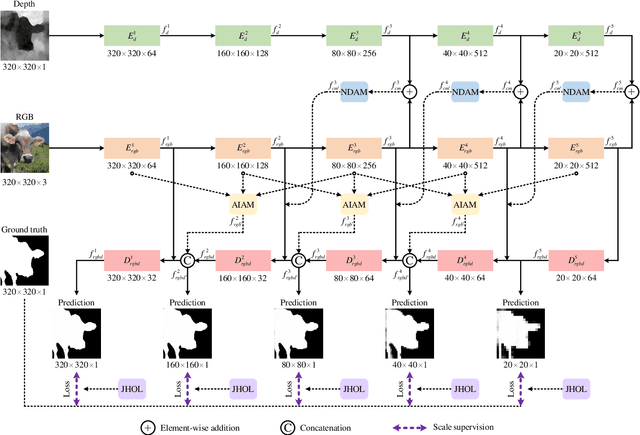

Salient object detection is a fundamental topic in computer vision. Previous methods based on RGB-D often suffer from the incompatibility of multi-modal feature fusion and the insufficiency of multi-scale feature aggregation. To tackle these two dilemmas, we propose a novel multi-modal and multi-scale refined network (M2RNet). Three essential components are presented in this network. The nested dual attention module (NDAM) explicitly exploits the combined features of RGB and depth flows. The adjacent interactive aggregation module (AIAM) gradually integrates the neighbor features of high, middle and low levels. The joint hybrid optimization loss (JHOL) makes the predictions have a prominent outline. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches.
Modal-Adaptive Gated Recoding Network for RGB-D Salient Object Detection
Aug 13, 2021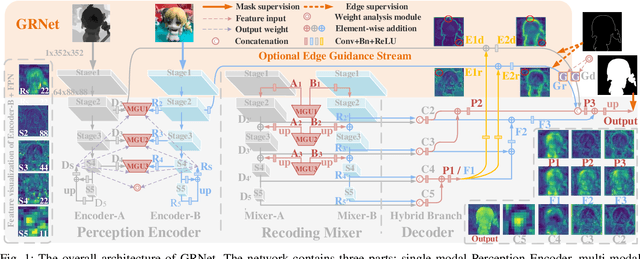
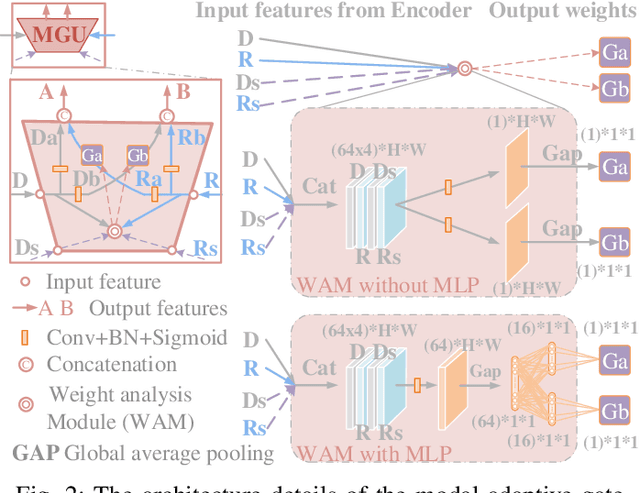

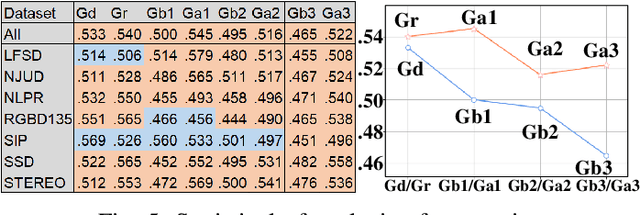
The multi-modal salient object detection model based on RGB-D information has better robustness in the real world. However, it remains nontrivial to better adaptively balance effective multi-modal information in the feature fusion phase. In this letter, we propose a novel gated recoding network (GRNet) to evaluate the information validity of the two modes, and balance their influence. Our framework is divided into three phases: perception phase, recoding mixing phase and feature integration phase. First, A perception encoder is adopted to extract multi-level single-modal features, which lays the foundation for multi-modal semantic comparative analysis. Then, a modal-adaptive gate unit (MGU) is proposed to suppress the invalid information and transfer the effective modal features to the recoding mixer and the hybrid branch decoder. The recoding mixer is responsible for recoding and mixing the balanced multi-modal information. Finally, the hybrid branch decoder completes the multi-level feature integration under the guidance of an optional edge guidance stream (OEGS). Experiments and analysis on eight popular benchmarks verify that our framework performs favorably against 9 state-of-art methods.
Perception-and-Regulation Network for Salient Object Detection
Jul 27, 2021

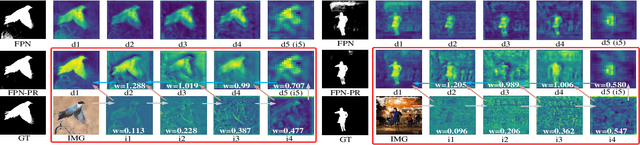

Effective fusion of different types of features is the key to salient object detection. The majority of existing network structure design is based on the subjective experience of scholars and the process of feature fusion does not consider the relationship between the fused features and highest-level features. In this paper, we focus on the feature relationship and propose a novel global attention unit, which we term the "perception- and-regulation" (PR) block, that adaptively regulates the feature fusion process by explicitly modeling interdependencies between features. The perception part uses the structure of fully-connected layers in classification networks to learn the size and shape of objects. The regulation part selectively strengthens and weakens the features to be fused. An imitating eye observation module (IEO) is further employed for improving the global perception ability of the network. The imitation of foveal vision and peripheral vision enables IEO to scrutinize highly detailed objects and to organize the broad spatial scene to better segment objects. Sufficient experiments conducted on SOD datasets demonstrate that the proposed method performs favorably against 22 state-of-the-art methods.