 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Causal Discovery with Interventional Constraints
Oct 30, 2025Incorporating causal knowledge and mechanisms is essential for refining causal models and improving downstream tasks such as designing new treatments. In this paper, we introduce a novel concept in causal discovery, termed interventional constraints, which differs fundamentally from interventional data. While interventional data require direct perturbations of variables, interventional constraints encode high-level causal knowledge in the form of inequality constraints on causal effects. For instance, in the Sachs dataset (Sachs et al.\ 2005), Akt has been shown to be activated by PIP3, meaning PIP3 exerts a positive causal effect on Akt. Existing causal discovery methods allow enforcing structural constraints (for example, requiring a causal path from PIP3 to Akt), but they may still produce incorrect causal conclusions such as learning that "PIP3 inhibits Akt". Interventional constraints bridge this gap by explicitly constraining the total causal effect between variable pairs, ensuring learned models respect known causal influences. To formalize interventional constraints, we propose a metric to quantify total causal effects for linear causal models and formulate the problem as a constrained optimization task, solved using a two-stage constrained optimization method. We evaluate our approach on real-world datasets and demonstrate that integrating interventional constraints not only improves model accuracy and ensures consistency with established findings, making models more explainable, but also facilitates the discovery of new causal relationships that would otherwise be costly to identify.
Progressive Confident Masking Attention Network for Audio-Visual Segmentation
Jun 04, 2024
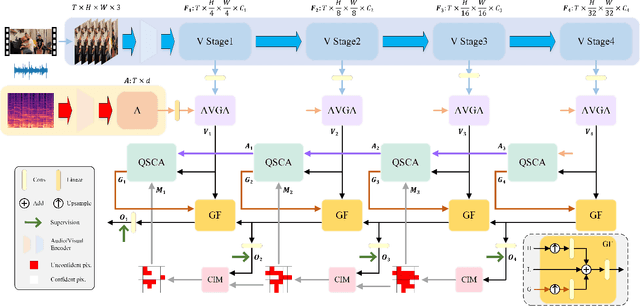
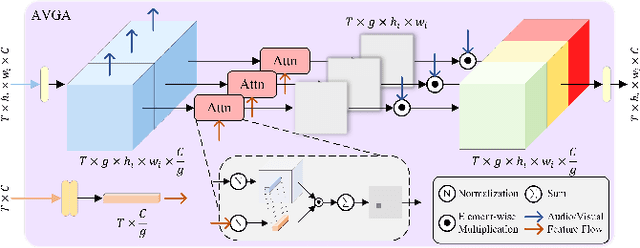
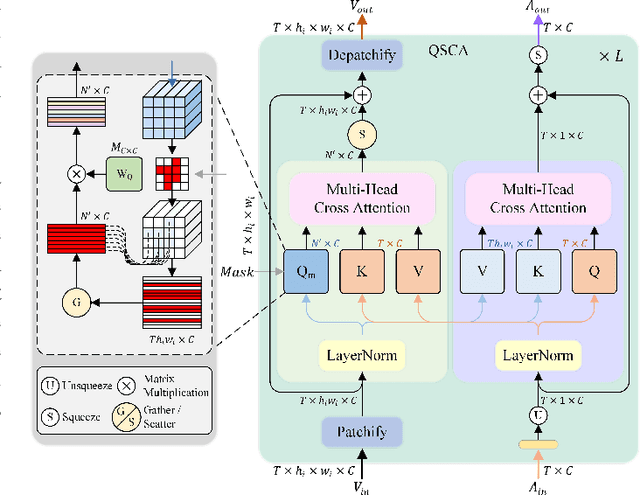
Audio and visual signals typically occur simultaneously, and humans possess an innate ability to correlate and synchronize information from these two modalities. Recently, a challenging problem known as Audio-Visual Segmentation (AVS) has emerged, intending to produce segmentation maps for sounding objects within a scene. However, the methods proposed so far have not sufficiently integrated audio and visual information, and the computational costs have been extremely high. Additionally, the outputs of different stages have not been fully utilized. To facilitate this research, we introduce a novel Progressive Confident Masking Attention Network (PMCANet). It leverages attention mechanisms to uncover the intrinsic correlations between audio signals and visual frames. Furthermore, we design an efficient and effective cross-attention module to enhance semantic perception by selecting query tokens. This selection is determined through confidence-driven units based on the network's multi-stage predictive outputs. Experiments demonstrate that our network outperforms other AVS methods while requiring less computational resources.
Interactive Context-Aware Network for RGB-T Salient Object Detection
Nov 11, 2022
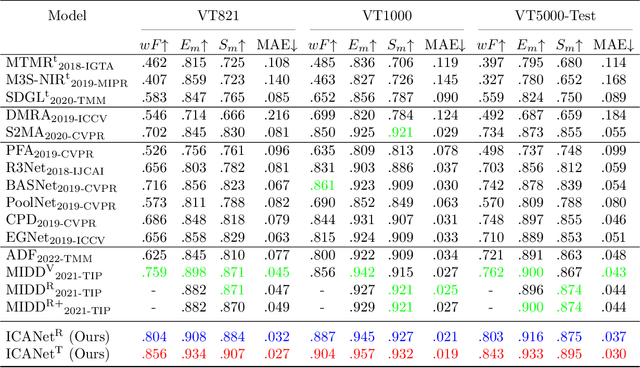

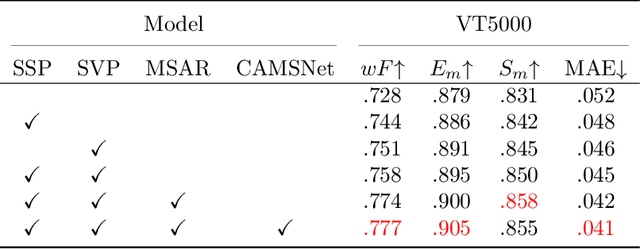
Salient object detection (SOD) focuses on distinguishing the most conspicuous objects in the scene. However, most related works are based on RGB images, which lose massive useful information. Accordingly, with the maturity of thermal technology, RGB-T (RGB-Thermal) multi-modality tasks attain more and more attention. Thermal infrared images carry important information which can be used to improve the accuracy of SOD prediction. To accomplish it, the methods to integrate multi-modal information and suppress noises are critical. In this paper, we propose a novel network called Interactive Context-Aware Network (ICANet). It contains three modules that can effectively perform the cross-modal and cross-scale fusions. We design a Hybrid Feature Fusion (HFF) module to integrate the features of two modalities, which utilizes two types of feature extraction. The Multi-Scale Attention Reinforcement (MSAR) and Upper Fusion (UF) blocks are responsible for the cross-scale fusion that converges different levels of features and generate the prediction maps. We also raise a novel Context-Aware Multi-Supervised Network (CAMSNet) to calculate the content loss between the prediction and the ground truth (GT). Experiments prove that our network performs favorably against the state-of-the-art RGB-T SOD methods.
Causality Learning With Wasserstein Generative Adversarial Networks
Jun 03, 2022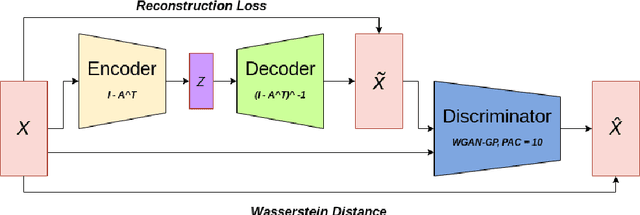
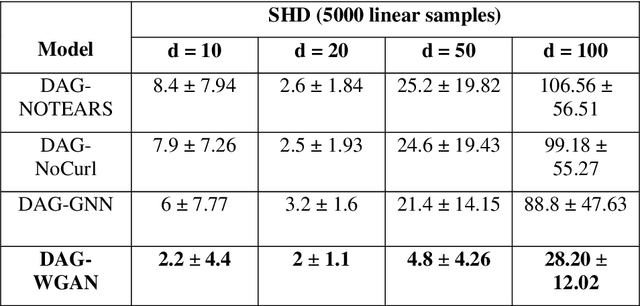
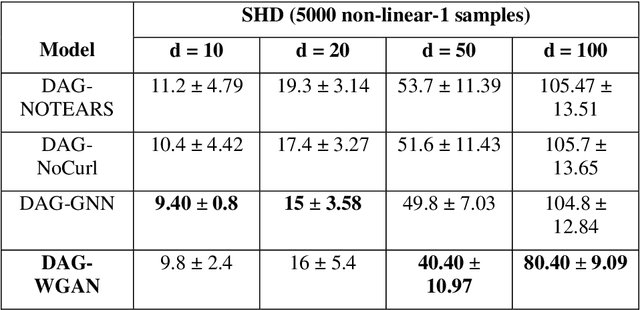

Conventional methods for causal structure learning from data face significant challenges due to combinatorial search space. Recently, the problem has been formulated into a continuous optimization framework with an acyclicity constraint to learn Directed Acyclic Graphs (DAGs). Such a framework allows the utilization of deep generative models for causal structure learning to better capture the relations between data sample distributions and DAGs. However, so far no study has experimented with the use of Wasserstein distance in the context of causal structure learning. Our model named DAG-WGAN combines the Wasserstein-based adversarial loss with an acyclicity constraint in an auto-encoder architecture. It simultaneously learns causal structures while improving its data generation capability. We compare the performance of DAG-WGAN with other models that do not involve the Wasserstein metric in order to identify its contribution to causal structure learning. Our model performs better with high cardinality data according to our experiments.
Hyper-Learning for Gradient-Based Batch Size Adaptation
May 17, 2022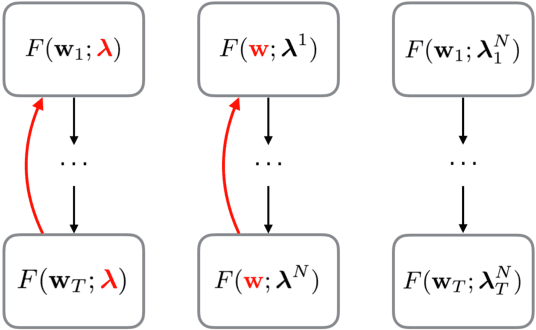
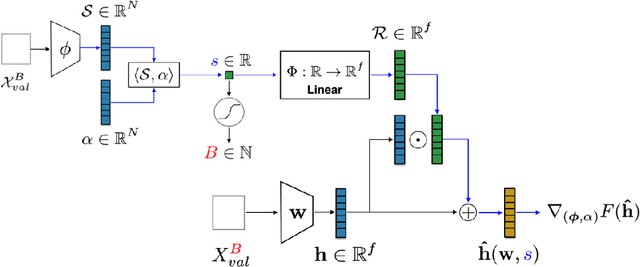
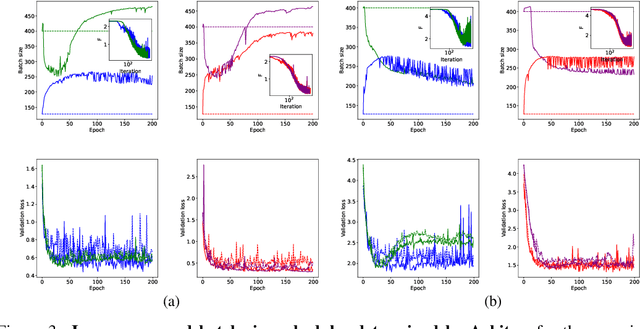
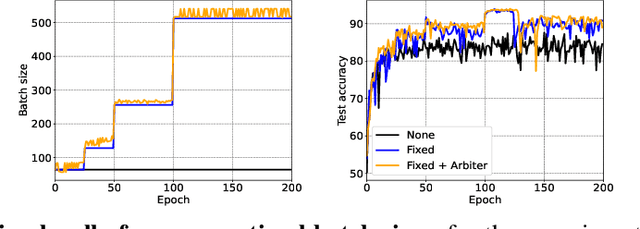
Scheduling the batch size to increase is an effective strategy to control gradient noise when training deep neural networks. Current approaches implement scheduling heuristics that neglect structure within the optimization procedure, limiting their flexibility to the training dynamics and capacity to discern the impact of their adaptations on generalization. We introduce Arbiter as a new hyperparameter optimization algorithm to perform batch size adaptations for learnable scheduling heuristics using gradients from a meta-objective function, which overcomes previous heuristic constraints by enforcing a novel learning process called hyper-learning. With hyper-learning, Arbiter formulates a neural network agent to generate optimal batch size samples for an inner deep network by learning an adaptive heuristic through observing concomitant responses over T inner descent steps. Arbiter avoids unrolled optimization, and does not require hypernetworks to facilitate gradients, making it reasonably cheap, simple to implement, and versatile to different tasks. We demonstrate Arbiter's effectiveness in several illustrative experiments: to act as a stand-alone batch size scheduler; to complement fixed batch size schedules with greater flexibility; and to promote variance reduction during stochastic meta-optimization of the learning rate.
DAG-WGAN: Causal Structure Learning With Wasserstein Generative Adversarial Networks
Apr 01, 2022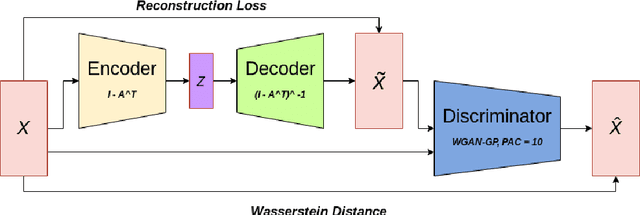
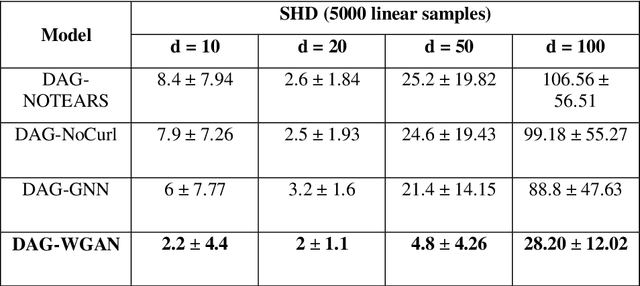
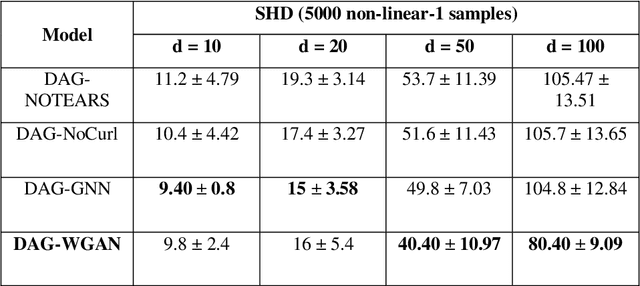
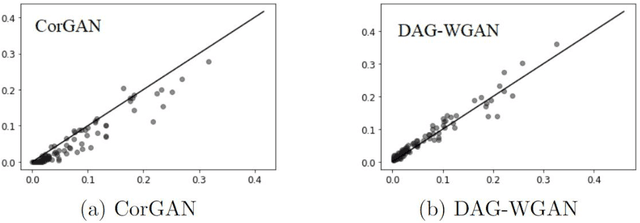
The combinatorial search space presents a significant challenge to learning causality from data. Recently, the problem has been formulated into a continuous optimization framework with an acyclicity constraint, allowing for the exploration of deep generative models to better capture data sample distributions and support the discovery of Directed Acyclic Graphs (DAGs) that faithfully represent the underlying data distribution. However, so far no study has investigated the use of Wasserstein distance for causal structure learning via generative models. This paper proposes a new model named DAG-WGAN, which combines the Wasserstein-based adversarial loss, an auto-encoder architecture together with an acyclicity constraint. DAG-WGAN simultaneously learns causal structures and improves its data generation capability by leveraging the strength from the Wasserstein distance metric. Compared with other models, it scales well and handles both continuous and discrete data. Our experiments have evaluated DAG-WGAN against the state-of-the-art and demonstrated its good performance.
Modal-Adaptive Gated Recoding Network for RGB-D Salient Object Detection
Aug 13, 2021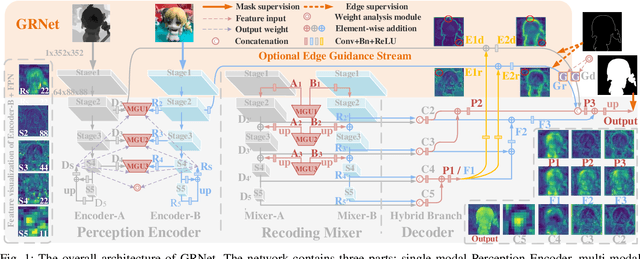
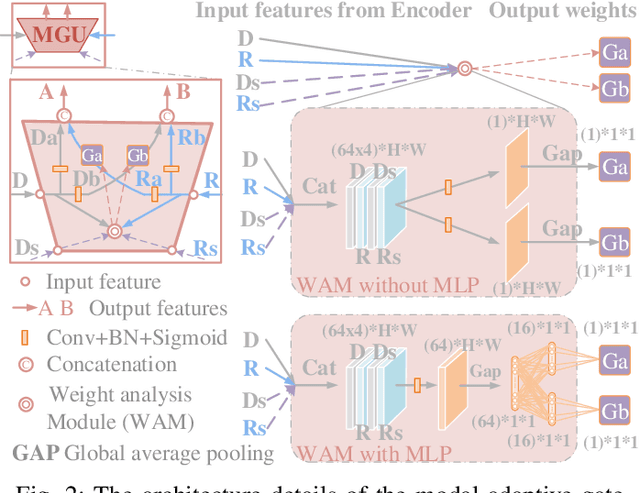

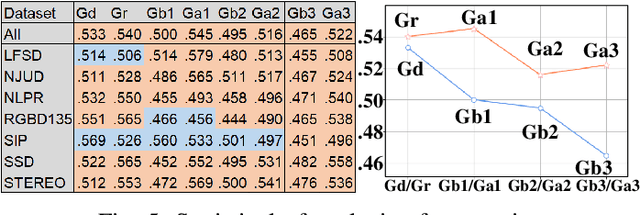
The multi-modal salient object detection model based on RGB-D information has better robustness in the real world. However, it remains nontrivial to better adaptively balance effective multi-modal information in the feature fusion phase. In this letter, we propose a novel gated recoding network (GRNet) to evaluate the information validity of the two modes, and balance their influence. Our framework is divided into three phases: perception phase, recoding mixing phase and feature integration phase. First, A perception encoder is adopted to extract multi-level single-modal features, which lays the foundation for multi-modal semantic comparative analysis. Then, a modal-adaptive gate unit (MGU) is proposed to suppress the invalid information and transfer the effective modal features to the recoding mixer and the hybrid branch decoder. The recoding mixer is responsible for recoding and mixing the balanced multi-modal information. Finally, the hybrid branch decoder completes the multi-level feature integration under the guidance of an optional edge guidance stream (OEGS). Experiments and analysis on eight popular benchmarks verify that our framework performs favorably against 9 state-of-art methods.