 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModal-Adaptive Gated Recoding Network for RGB-D Salient Object Detection
Paper and Code
Aug 13, 2021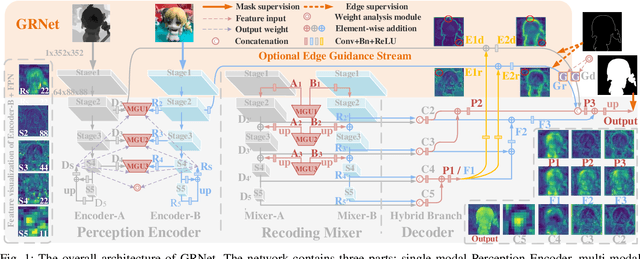
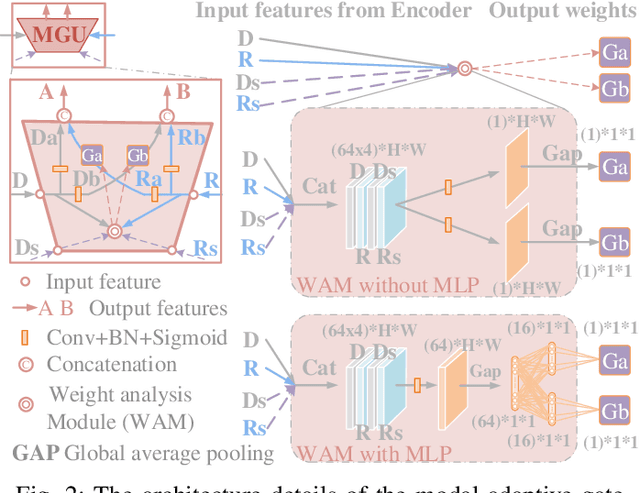

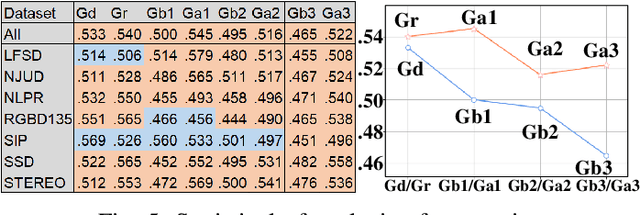
The multi-modal salient object detection model based on RGB-D information has better robustness in the real world. However, it remains nontrivial to better adaptively balance effective multi-modal information in the feature fusion phase. In this letter, we propose a novel gated recoding network (GRNet) to evaluate the information validity of the two modes, and balance their influence. Our framework is divided into three phases: perception phase, recoding mixing phase and feature integration phase. First, A perception encoder is adopted to extract multi-level single-modal features, which lays the foundation for multi-modal semantic comparative analysis. Then, a modal-adaptive gate unit (MGU) is proposed to suppress the invalid information and transfer the effective modal features to the recoding mixer and the hybrid branch decoder. The recoding mixer is responsible for recoding and mixing the balanced multi-modal information. Finally, the hybrid branch decoder completes the multi-level feature integration under the guidance of an optional edge guidance stream (OEGS). Experiments and analysis on eight popular benchmarks verify that our framework performs favorably against 9 state-of-art methods.