 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupTransNet: Group Transformer Network for RGB-D Salient Object Detection
Paper and Code
Mar 21, 2022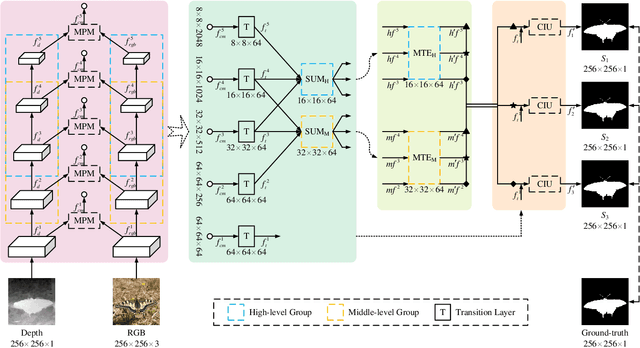
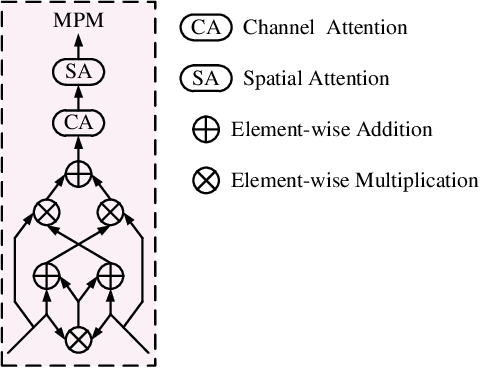
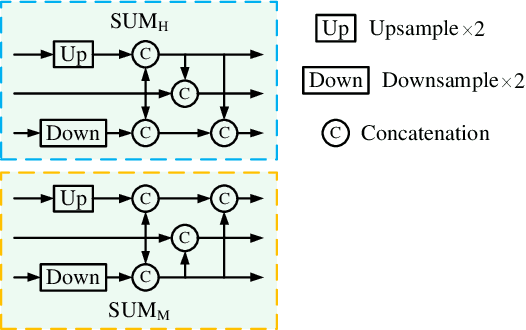
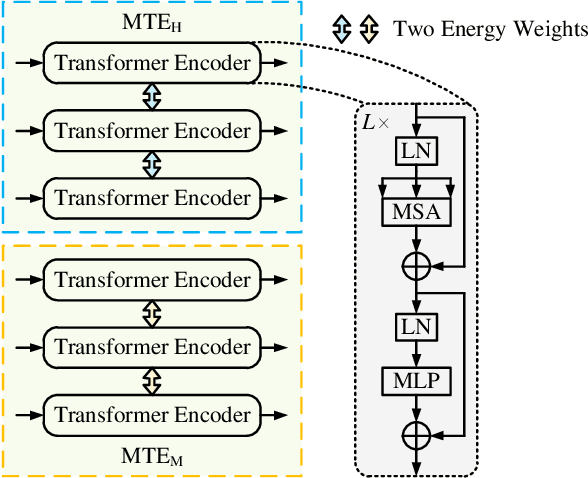
Salient object detection on RGB-D images is an active topic in computer vision. Although the existing methods have achieved appreciable performance, there are still some challenges. The locality of convolutional neural network requires that the model has a sufficiently deep global receptive field, which always leads to the loss of local details. To address the challenge, we propose a novel Group Transformer Network (GroupTransNet) for RGB-D salient object detection. This method is good at learning the long-range dependencies of cross layer features to promote more perfect feature expression. At the beginning, the features of the slightly higher classes of the middle three levels and the latter three levels are soft grouped to absorb the advantages of the high-level features. The input features are repeatedly purified and enhanced by the attention mechanism to purify the cross modal features of color modal and depth modal. The features of the intermediate process are first fused by the features of different layers, and then processed by several transformers in multiple groups, which not only makes the size of the features of each scale unified and interrelated, but also achieves the effect of sharing the weight of the features within the group. The output features in different groups complete the clustering staggered by two owing to the level difference, and combine with the low-level features. Extensive experiments demonstrate that GroupTransNet outperforms the comparison models and achieves the new state-of-the-art performance.