 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMAE-V: Contrastive Masked Autoencoders for Video Action Recognition
Paper and Code
Jan 15, 2023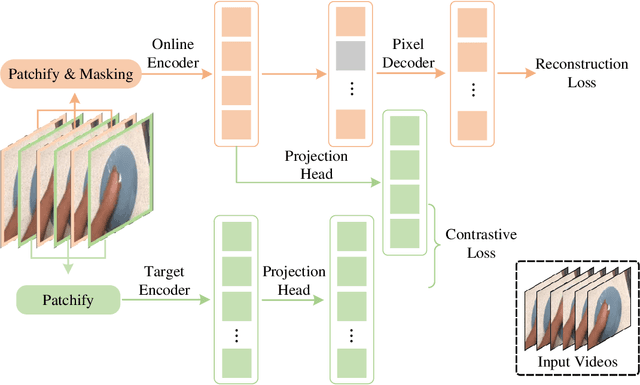
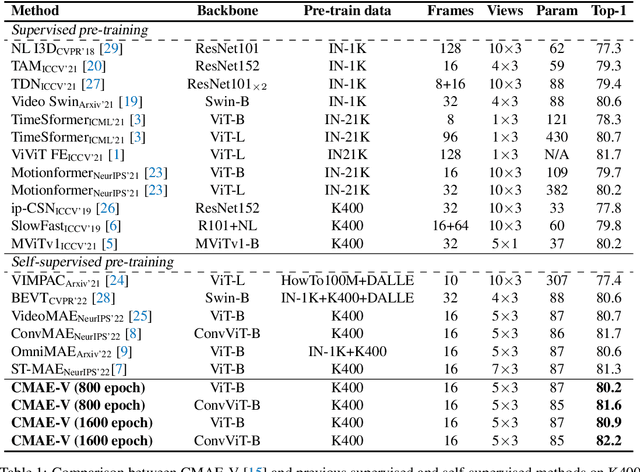
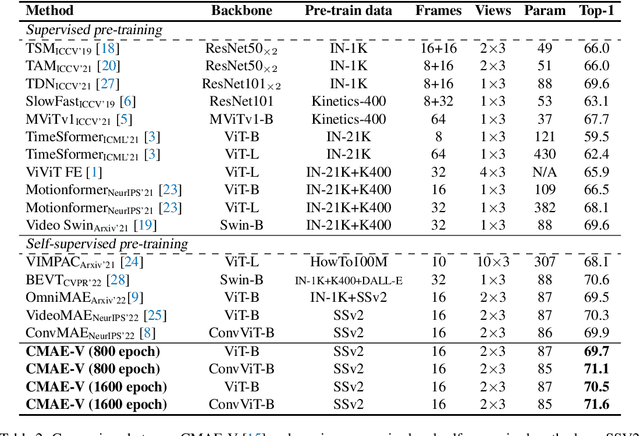
Contrastive Masked Autoencoder (CMAE), as a new self-supervised framework, has shown its potential of learning expressive feature representations in visual image recognition. This work shows that CMAE also trivially generalizes well on video action recognition without modifying the architecture and the loss criterion. By directly replacing the original pixel shift with the temporal shift, our CMAE for visual action recognition, CMAE-V for short, can generate stronger feature representations than its counterpart based on pure masked autoencoders. Notably, CMAE-V, with a hybrid architecture, can achieve 82.2% and 71.6% top-1 accuracy on the Kinetics-400 and Something-something V2 datasets, respectively. We hope this report could provide some informative inspiration for future works.