 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Preference Evaluation with Multiple Weak Evaluators
Paper and Code
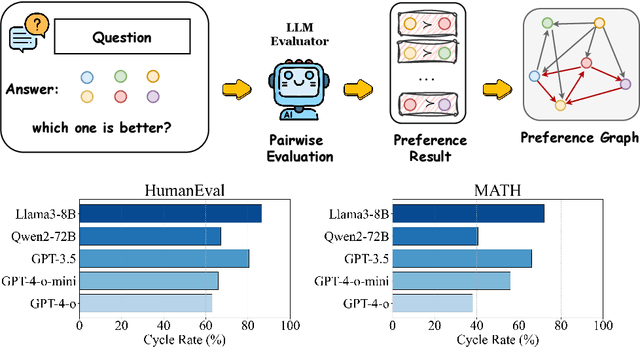
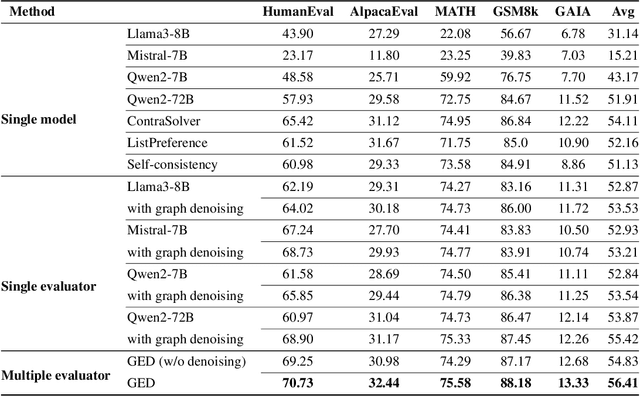
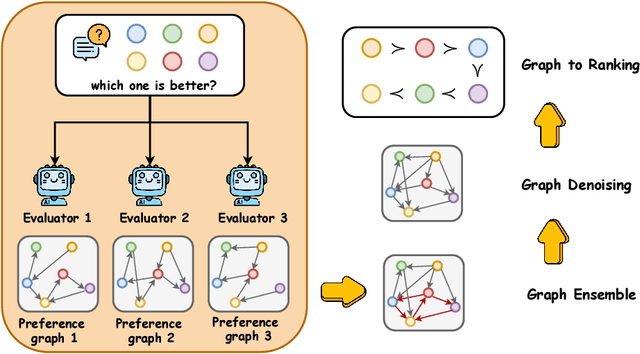
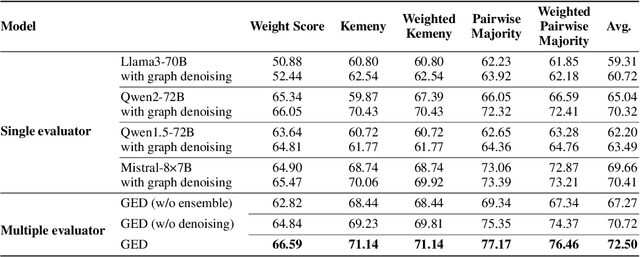
Despite the remarkable success of Large Language Models (LLMs), evaluating their outputs' quality regarding preference remains a critical challenge. Existing works usually leverage a powerful LLM (e.g., GPT4) as the judge for comparing LLMs' output pairwisely, yet such model-based evaluator is vulnerable to conflicting preference, i.e., output A is better than B, B than C, but C than A, causing contradictory evaluation results. To improve model-based preference evaluation, we introduce GED (Preference Graph Ensemble and Denoise), a novel approach that leverages multiple model-based evaluators to construct preference graphs, and then ensemble and denoise these graphs for better, non-contradictory evaluation results. In particular, our method consists of two primary stages: aggregating evaluations into a unified graph and applying a denoising process to eliminate cyclic inconsistencies, ensuring a directed acyclic graph (DAG) structure. We provide theoretical guarantees for our framework, demonstrating its efficacy in recovering the ground truth preference structure. Extensive experiments across ten benchmark datasets show that GED outperforms baseline methods in model ranking, response selection, and model alignment tasks. Notably, GED combines weaker evaluators like Llama3-8B, Mistral-7B, and Qwen2-7B to surpass the performance of stronger evaluators like Qwen2-72B, highlighting its ability to enhance evaluation reliability and improve model performance.