 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEqO: ML-Accelerated Semantic Equivalence Detection
Jan 02, 2024



Large scale analytics engines have become a core dependency for modern data-driven enterprises to derive business insights and drive actions. These engines support a large number of analytic jobs processing huge volumes of data on a daily basis, and workloads are often inundated with overlapping computations across multiple jobs. Reusing common computation is crucial for efficient cluster resource utilization and reducing job execution time. Detecting common computation is the first and key step for reducing this computational redundancy. However, detecting equivalence on large-scale analytics engines requires efficient and scalable solutions that are fully automated. In addition, to maximize computation reuse, equivalence needs to be detected at the semantic level instead of just the syntactic level (i.e., the ability to detect semantic equivalence of seemingly different-looking queries). Unfortunately, existing solutions fall short of satisfying these requirements. In this paper, we take a major step towards filling this gap by proposing GEqO, a portable and lightweight machine-learning-based framework for efficiently identifying semantically equivalent computations at scale. GEqO introduces two machine-learning-based filters that quickly prune out nonequivalent subexpressions and employs a semi-supervised learning feedback loop to iteratively improve its model with an intelligent sampling mechanism. Further, with its novel database-agnostic featurization method, GEqO can transfer the learning from one workload and database to another. Our extensive empirical evaluation shows that, on TPC-DS-like queries, GEqO yields significant performance gains-up to 200x faster than automated verifiers-and finds up to 2x more equivalences than optimizer and signature-based equivalence detection approaches.
VOCALExplore: Pay-as-You-Go Video Data Exploration and Model Building
Mar 07, 2023
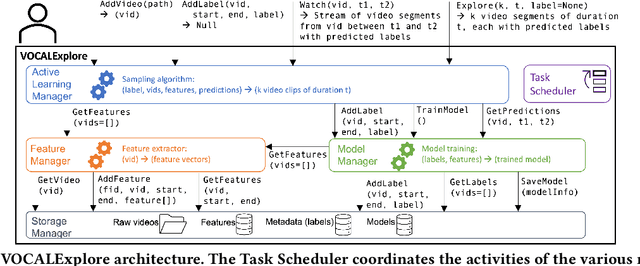


We introduce VOCALExplore, a system designed to support users in building domain-specific models over video datasets. VOCALExplore supports interactive labeling sessions and trains models using user-supplied labels. VOCALExplore maximizes model quality by automatically deciding how to select samples based on observed skew in the collected labels. It also selects the optimal video representations to use when training models by casting feature selection as a rising bandit problem. Finally, VOCALExplore implements optimizations to achieve low latency without sacrificing model performance. We demonstrate that VOCALExplore achieves close to the best possible model quality given candidate acquisition functions and feature extractors, and it does so with low visible latency (~1 second per iteration) and no expensive preprocessing.