 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source EEG Emotion Recognition via Dynamic Contrastive Domain Adaptation
Aug 04, 2024



Electroencephalography (EEG) provides reliable indications of human cognition and mental states. Accurate emotion recognition from EEG remains challenging due to signal variations among individuals and across measurement sessions. To address these challenges, we introduce a multi-source dynamic contrastive domain adaptation method (MS-DCDA), which models coarse-grained inter-domain and fine-grained intra-class adaptations through a multi-branch contrastive neural network and contrastive sub-domain discrepancy learning. Our model leverages domain knowledge from each individual source and a complementary source ensemble and uses dynamically weighted learning to achieve an optimal tradeoff between domain transferability and discriminability. The proposed MS-DCDA model was evaluated using the SEED and SEED-IV datasets, achieving respectively the highest mean accuracies of $90.84\%$ and $78.49\%$ in cross-subject experiments as well as $95.82\%$ and $82.25\%$ in cross-session experiments. Our model outperforms several alternative domain adaptation methods in recognition accuracy, inter-class margin, and intra-class compactness. Our study also suggests greater emotional sensitivity in the frontal and parietal brain lobes, providing insights for mental health interventions, personalized medicine, and development of preventive strategies.
Detecting Soil Moisture Levels Using Battery-Free Wi-Fi Tag
Feb 04, 2022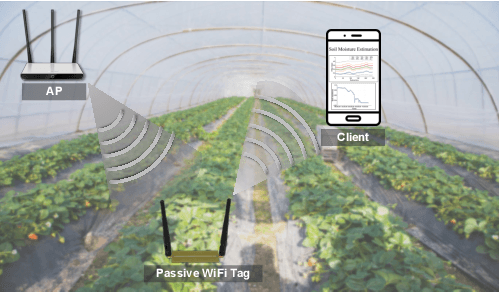
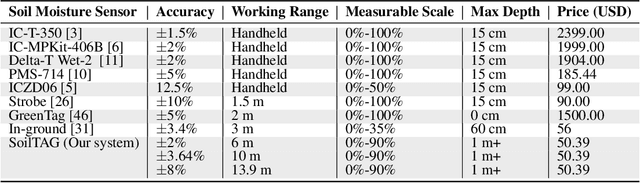
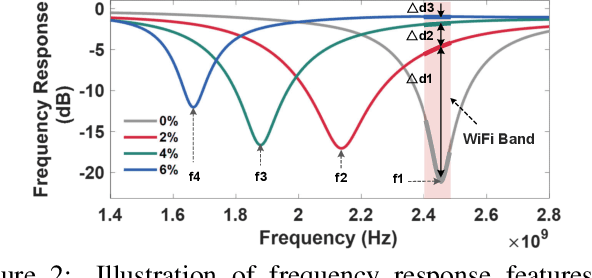
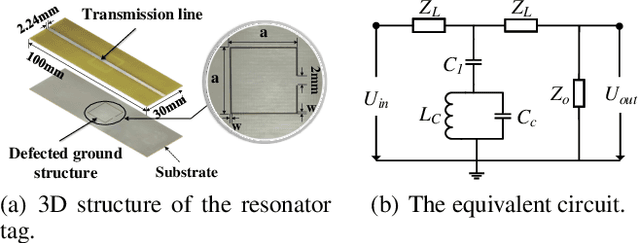
Soil sensing plays an important role in increasing agricultural output and protecting soil sites. Existing soil sensing methods failed to achieve both high accuracy and low cost. In this paper, we design and implement a high-accuracy and low cost chipless soil moisture sensing system called SoilTAG. We propose a general chipless sensor design methodology which can allow us to customize the signal feature for sensing soil moisture, instead of blindly capturing the disturbance law of the soil. Based on this principle, we design a battery-free passive tag which can respond to different soil-moisture. Further, we optimize hardware and algorithm design of SoilTAG to locate the passive tag and extract its reflection signal feature to identify soil-moisture using WiFi signals. Extensive experimental results reveal that it can identify 2% absolute soil water content with a sensing distance up to 3m in open field. When the sensing distance is up to 13 m, it can also achieve 5% absolute soil-moisture sensing resolution.
Scene Graphs: A Survey of Generations and Applications
Mar 17, 2021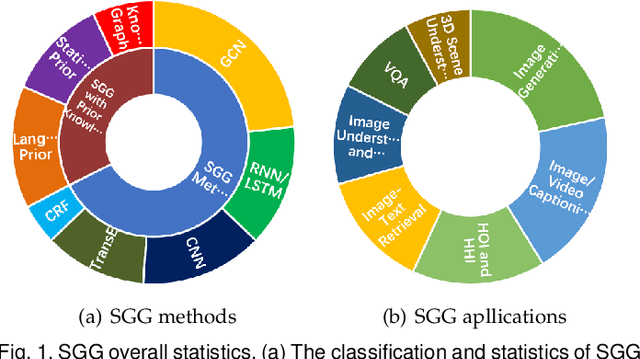

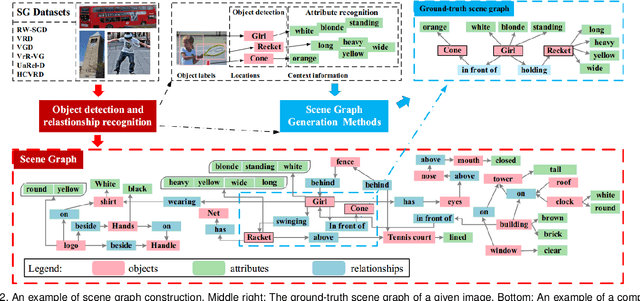
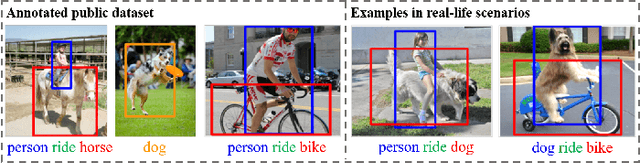
Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and relationships between objects in the scene. As computer vision technology continues to develop, people are no longer satisfied with simply detecting and recognizing objects in images; instead, people look forward to a higher level of understanding and reasoning about visual scenes. For example, given an image, we want to not only detect and recognize objects in the image, but also know the relationship between objects (visual relationship detection), and generate a text description (image captioning) based on the image content. Alternatively, we might want the machine to tell us what the little girl in the image is doing (Visual Question Answering (VQA)), or even remove the dog from the image and find similar images (image editing and retrieval), etc. These tasks require a higher level of understanding and reasoning for image vision tasks. The scene graph is just such a powerful tool for scene understanding. Therefore, scene graphs have attracted the attention of a large number of researchers, and related research is often cross-modal, complex, and rapidly developing. However, no relatively systematic survey of scene graphs exists at present. To this end, this survey conducts a comprehensive investigation of the current scene graph research. More specifically, we first summarized the general definition of the scene graph, then conducted a comprehensive and systematic discussion on the generation method of the scene graph (SGG) and the SGG with the aid of prior knowledge. We then investigated the main applications of scene graphs and summarized the most commonly used datasets. Finally, we provide some insights into the future development of scene graphs. We believe this will be a very helpful foundation for future research on scene graphs.
NAS-TC: Neural Architecture Search on Temporal Convolutions for Complex Action Recognition
Mar 17, 2021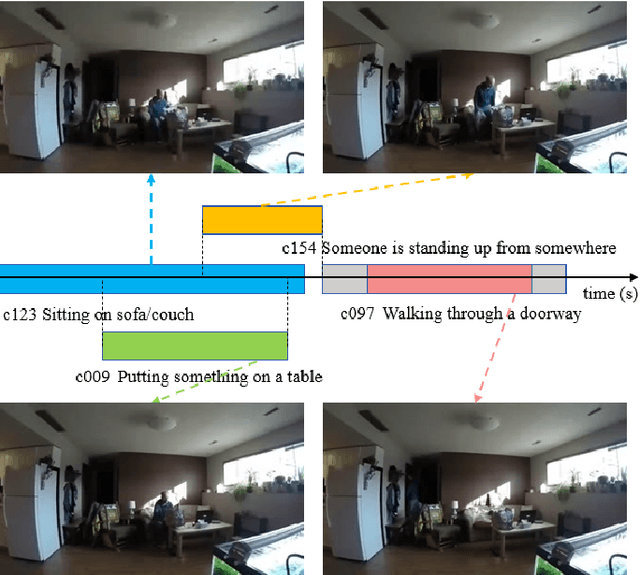
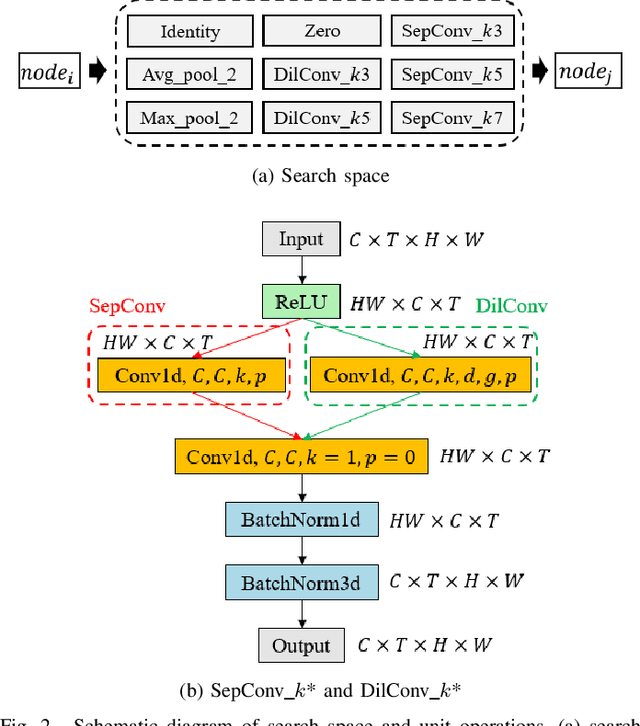
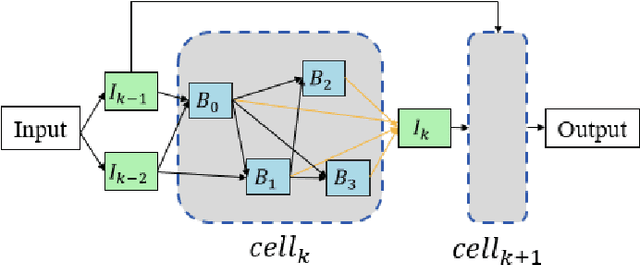
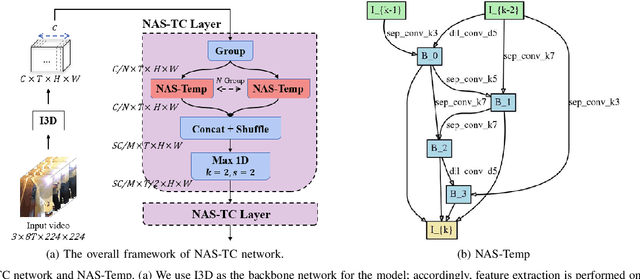
In the field of complex action recognition in videos, the quality of the designed model plays a crucial role in the final performance. However, artificially designed network structures often rely heavily on the researchers' knowledge and experience. Accordingly, because of the automated design of its network structure, Neural architecture search (NAS) has achieved great success in the image processing field and attracted substantial research attention in recent years. Although some NAS methods have reduced the number of GPU search days required to single digits in the image field, directly using 3D convolution to extend NAS to the video field is still likely to produce a surge in computing volume. To address this challenge, we propose a new processing framework called Neural Architecture Search- Temporal Convolutional (NAS-TC). Our proposed framework is divided into two phases. In the first phase, the classical CNN network is used as the backbone network to complete the computationally intensive feature extraction task. In the second stage, a simple stitching search to the cell is used to complete the relatively lightweight long-range temporal-dependent information extraction. This ensures our method will have more reasonable parameter assignments and can handle minute-level videos. Finally, we conduct sufficient experiments on multiple benchmark datasets and obtain competitive recognition accuracy.
A Survey of Deep Active Learning
Aug 30, 2020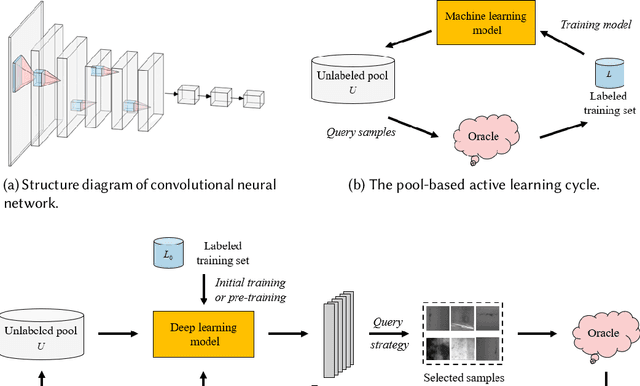
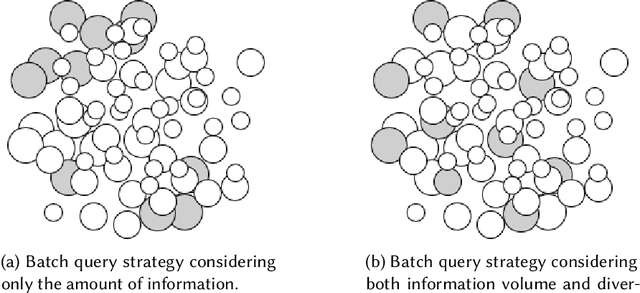
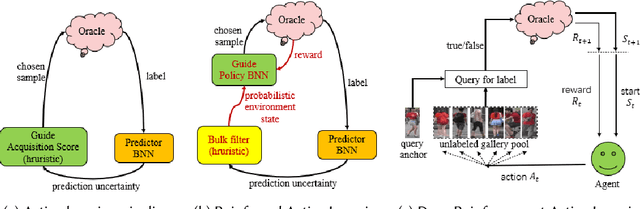
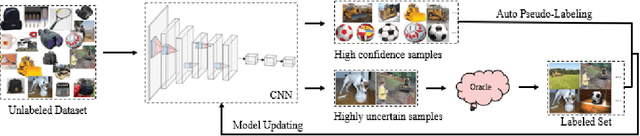
Active learning (AL) attempts to maximize the performance gain of the model by marking the fewest samples. Deep learning (DL) is greedy for data and requires a large amount of data supply to optimize massive parameters, so that the model learns how to extract high-quality features. In recent years, due to the rapid development of internet technology, we are in an era of information torrents and we have massive amounts of data. In this way, DL has aroused strong interest of researchers and has been rapidly developed. Compared with DL, researchers have relatively low interest in AL. This is mainly because before the rise of DL, traditional machine learning requires relatively few labeled samples. Therefore, early AL is difficult to reflect the value it deserves. Although DL has made breakthroughs in various fields, most of this success is due to the publicity of the large number of existing annotation datasets. However, the acquisition of a large number of high-quality annotated datasets consumes a lot of manpower, which is not allowed in some fields that require high expertise, especially in the fields of speech recognition, information extraction, medical images, etc. Therefore, AL has gradually received due attention. A natural idea is whether AL can be used to reduce the cost of sample annotations, while retaining the powerful learning capabilities of DL. Therefore, deep active learning (DAL) has emerged. Although the related research has been quite abundant, it lacks a comprehensive survey of DAL. This article is to fill this gap, we provide a formal classification method for the existing work, and a comprehensive and systematic overview. In addition, we also analyzed and summarized the development of DAL from the perspective of application. Finally, we discussed the confusion and problems in DAL, and gave some possible development directions for DAL.
A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions
Jun 01, 2020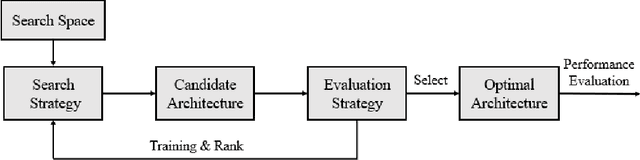
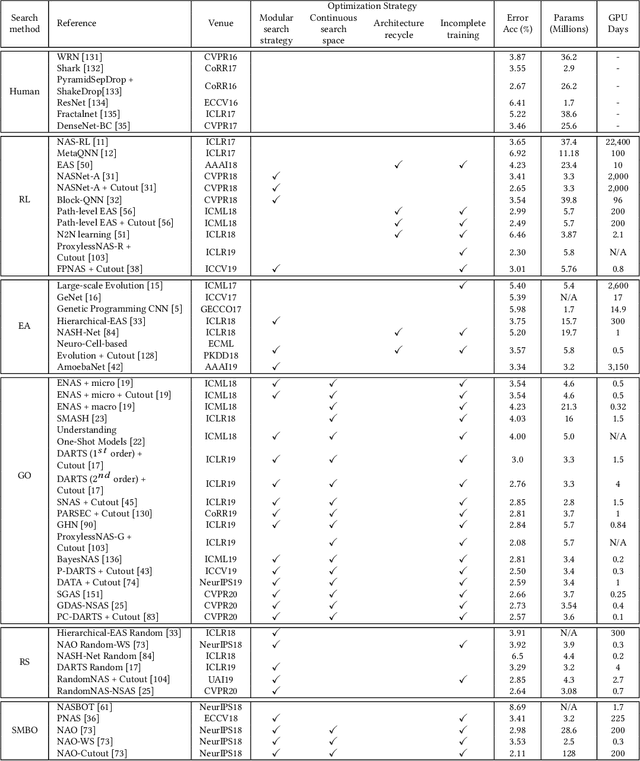
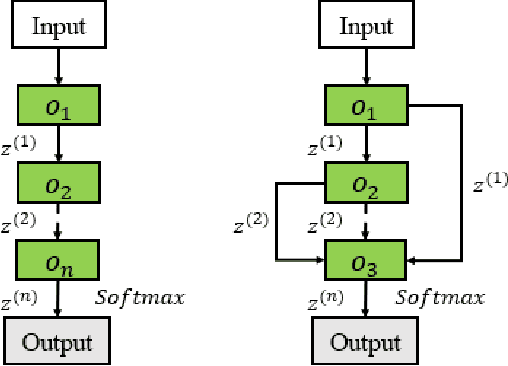
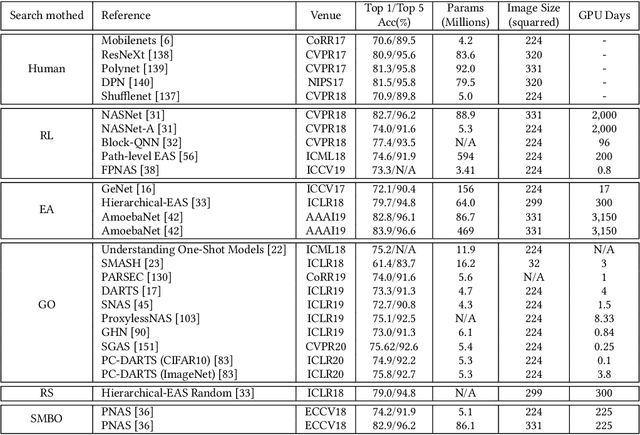
Deep learning has made major breakthroughs and progress in many fields. This is due to the powerful automatic representation capabilities of deep learning. It has been proved that the design of the network architecture is crucial to the feature representation of data and the final performance. In order to obtain a good feature representation of data, the researchers designed various complex network architectures. However, the design of the network architecture relies heavily on the researchers' prior knowledge and experience. Therefore, a natural idea is to reduce human intervention as much as possible and let the algorithm automatically design the architecture of the network. Thus going further to the strong intelligence. In recent years, a large number of related algorithms for \textit{Neural Architecture Search} (NAS) have emerged. They have made various improvements to the NAS algorithm, and the related research work is complicated and rich. In order to reduce the difficulty for beginners to conduct NAS-related research, a comprehensive and systematic survey on the NAS is essential. Previously related surveys began to classify existing work mainly from the basic components of NAS: search space, search strategy and evaluation strategy. This classification method is more intuitive, but it is difficult for readers to grasp the challenges and the landmark work in the middle. Therefore, in this survey, we provide a new perspective: starting with an overview of the characteristics of the earliest NAS algorithms, summarizing the problems in these early NAS algorithms, and then giving solutions for subsequent related research work. In addition, we conducted a detailed and comprehensive analysis, comparison and summary of these works. Finally, we give possible future research directions.