 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAS-TC: Neural Architecture Search on Temporal Convolutions for Complex Action Recognition
Paper and Code
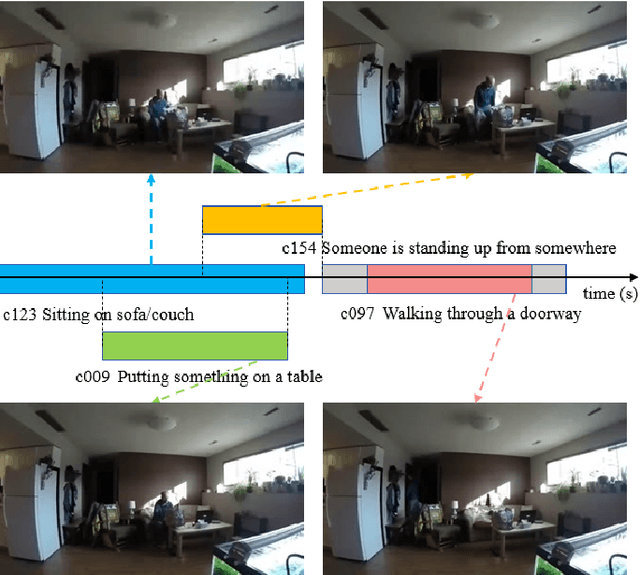
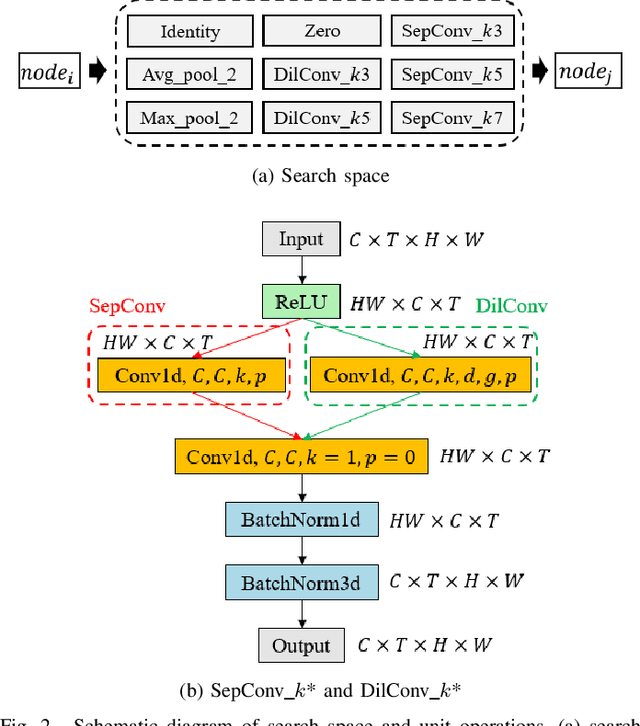
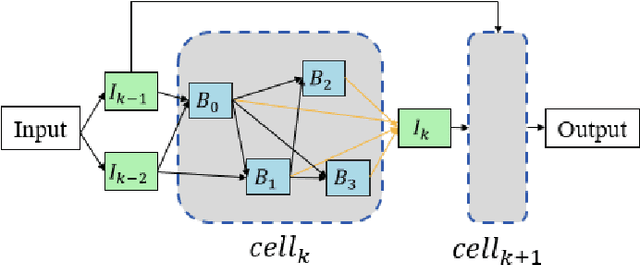
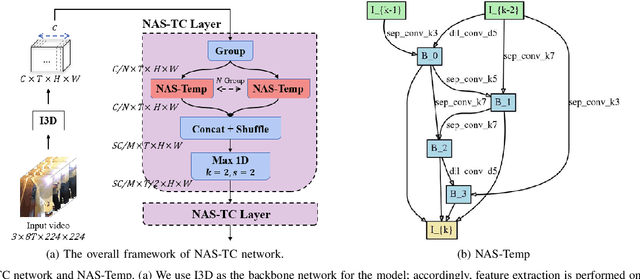
In the field of complex action recognition in videos, the quality of the designed model plays a crucial role in the final performance. However, artificially designed network structures often rely heavily on the researchers' knowledge and experience. Accordingly, because of the automated design of its network structure, Neural architecture search (NAS) has achieved great success in the image processing field and attracted substantial research attention in recent years. Although some NAS methods have reduced the number of GPU search days required to single digits in the image field, directly using 3D convolution to extend NAS to the video field is still likely to produce a surge in computing volume. To address this challenge, we propose a new processing framework called Neural Architecture Search- Temporal Convolutional (NAS-TC). Our proposed framework is divided into two phases. In the first phase, the classical CNN network is used as the backbone network to complete the computationally intensive feature extraction task. In the second stage, a simple stitching search to the cell is used to complete the relatively lightweight long-range temporal-dependent information extraction. This ensures our method will have more reasonable parameter assignments and can handle minute-level videos. Finally, we conduct sufficient experiments on multiple benchmark datasets and obtain competitive recognition accuracy.