 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIERL: Internal-External Representation Learning Network for Underwater Image Enhancement
Jun 14, 2023



Underwater image enhancement (UIE) is a meaningful but challenging task, and many learning-based UIE methods have been proposed in recent years. Although much progress has been made, these methods still exist two issues: (1) There exists a significant region-wise quality difference in a single underwater image due to the underwater imaging process, especially in regions with different scene depths. However, existing methods neglect this internal characteristic of underwater images, resulting in inferior performance; (2) Due to the uniqueness of the acquisition approach, underwater image acquisition tools usually capture multiple images in the same or similar scenes. Thus, the underwater images to be enhanced in practical usage are highly correlated. However, when processing a single image, existing methods do not consider the rich external information provided by the related images. There is still room for improvement in their performance. Motivated by these two aspects, we propose a novel internal-external representation learning (UIERL) network to better perform UIE tasks with internal and external information, simultaneously. In the internal representation learning stage, a new depth-based region feature guidance network is designed, including a region segmentation based on scene depth to sense regions with different quality levels, followed by a region-wise space encoder module. With performing region-wise feature learning for regions with different quality separately, the network provides an effective guidance for global features and thus guides intra-image differentiated enhancement. In the external representation learning stage, we first propose an external information extraction network to mine the rich external information in the related images. Then, internal and external features interact with each other via the proposed external-assist-internal module and internal-assist-e
Domain Adaptation for Underwater Image Enhancement
Aug 22, 2021



Recently, learning-based algorithms have shown impressive performance in underwater image enhancement. Most of them resort to training on synthetic data and achieve outstanding performance. However, these methods ignore the significant domain gap between the synthetic and real data (i.e., interdomain gap), and thus the models trained on synthetic data often fail to generalize well to real underwater scenarios. Furthermore, the complex and changeable underwater environment also causes a great distribution gap among the real data itself (i.e., intra-domain gap). However, almost no research focuses on this problem and thus their techniques often produce visually unpleasing artifacts and color distortions on various real images. Motivated by these observations, we propose a novel Two-phase Underwater Domain Adaptation network (TUDA) to simultaneously minimize the inter-domain and intra-domain gap. Concretely, a new dual-alignment network is designed in the first phase, including a translation part for enhancing realism of input images, followed by an enhancement part. With performing image-level and feature-level adaptation in two parts by jointly adversarial learning, the network can better build invariance across domains and thus bridge the inter-domain gap. In the second phase, we perform an easy-hard classification of real data according to the assessed quality of enhanced images, where a rank-based underwater quality assessment method is embedded. By leveraging implicit quality information learned from rankings, this method can more accurately assess the perceptual quality of enhanced images. Using pseudo labels from the easy part, an easy-hard adaptation technique is then conducted to effectively decrease the intra-domain gap between easy and hard samples.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.
An Image Clustering Auto-Encoder Based on Predefined Evenly-Distributed Class Centroids and MMD Distance
Jun 10, 2019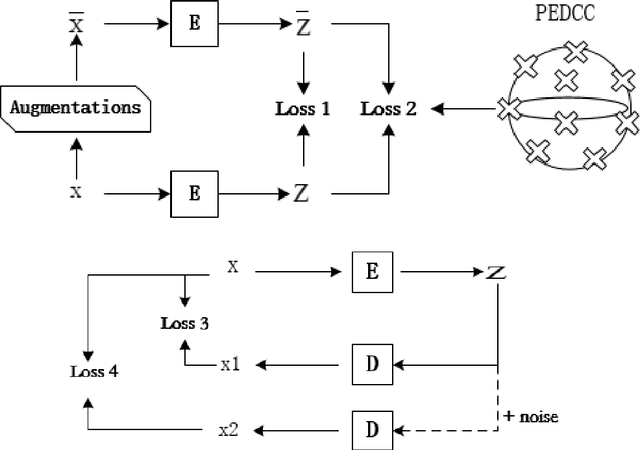
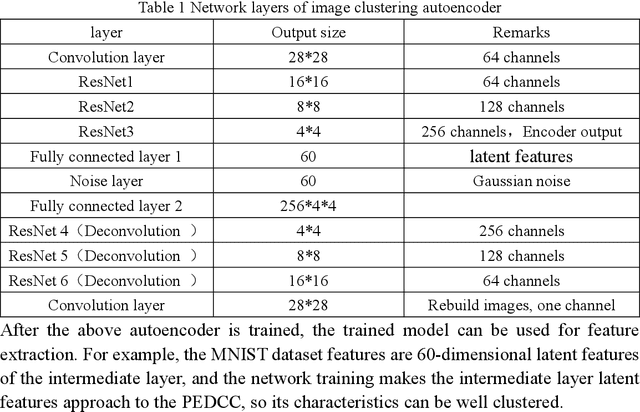

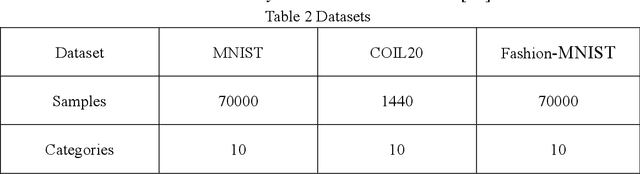
In this paper, we propose an end-to-end image clustering auto-encoder algorithm: ICAE. The algorithm uses PEDCC (Predefined Evenly-Distributed Class Centroids) as the clustering centers of the images, which ensures the inter-class distance of latent features is maximal, and adds data distribution constraint, data augmentation constraint, auto-encoder reconstruction loss constraint and latent features plus noise constraint to improve clustering performance. Specifically, we perform one-to-one data augmentation such as rotation, shear, and shift before data is input to the encoder to learn the more effective features. The data and the enhanced data are simultaneously input into the auto-encoder to obtain latent features and augmented latent features whose similarity are constrained by an augmentation loss. Then, making use of the MMD distance, we combine the latent features and augmented latent features to make their distribution close to the PEDCC distribution (uniform distribution between classes, Dirac distribution within the class) to further learn the features used for clustering. At the same time, the MSE of the original input image and reconstructed image is used as reconstruction constraint, and the noise is added to the latent features to build generalization constraint to improve the generalization ability. Finally, extensive experiments on three common datasets MNIST, Fashion-MNIST, COIL20 are conducted. The experimental results show that the algorithm has achieved the best clustering results so far, and also has good generalization ability. In addition, we can use the pre-defined PEDCC class centers, and the decoding module of the auto-encoder to clearly generate the samples of each class. The code can be downloaded at xxx!