 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Phone Scams with LLM-based Detection: Where Do We Stand?
Sep 18, 2024

Phone scams pose a significant threat to individuals and communities, causing substantial financial losses and emotional distress. Despite ongoing efforts to combat these scams, scammers continue to adapt and refine their tactics, making it imperative to explore innovative countermeasures. This research explores the potential of large language models (LLMs) to provide detection of fraudulent phone calls. By analyzing the conversational dynamics between scammers and victims, LLM-based detectors can identify potential scams as they occur, offering immediate protection to users. While such approaches demonstrate promising results, we also acknowledge the challenges of biased datasets, relatively low recall, and hallucinations that must be addressed for further advancement in this field
Understanding Impacts of Electromagnetic Signal Injection Attacks on Object Detection
Jul 23, 2024



Object detection can localize and identify objects in images, and it is extensively employed in critical multimedia applications such as security surveillance and autonomous driving. Despite the success of existing object detection models, they are often evaluated in ideal scenarios where captured images guarantee the accurate and complete representation of the detecting scenes. However, images captured by image sensors may be affected by different factors in real applications, including cyber-physical attacks. In particular, attackers can exploit hardware properties within the systems to inject electromagnetic interference so as to manipulate the images. Such attacks can cause noisy or incomplete information about the captured scene, leading to incorrect detection results, potentially granting attackers malicious control over critical functions of the systems. This paper presents a research work that comprehensively quantifies and analyzes the impacts of such attacks on state-of-the-art object detection models in practice. It also sheds light on the underlying reasons for the incorrect detection outcomes.
Multidimensional Transformation-Based Learning
Jul 17, 2001This paper presents a novel method that allows a machine learning algorithm following the transformation-based learning paradigm \cite{brill95:tagging} to be applied to multiple classification tasks by training jointly and simultaneously on all fields. The motivation for constructing such a system stems from the observation that many tasks in natural language processing are naturally composed of multiple subtasks which need to be resolved simultaneously; also tasks usually learned in isolation can possibly benefit from being learned in a joint framework, as the signals for the extra tasks usually constitute inductive bias. The proposed algorithm is evaluated in two experiments: in one, the system is used to jointly predict the part-of-speech and text chunks/baseNP chunks of an English corpus; and in the second it is used to learn the joint prediction of word segment boundaries and part-of-speech tagging for Chinese. The results show that the simultaneous learning of multiple tasks does achieve an improvement in each task upon training the same tasks sequentially. The part-of-speech tagging result of 96.63% is state-of-the-art for individual systems on the particular train/test split.
* 8 pages, 2 figures, presented at CONLL 2001
Transformation-Based Learning in the Fast Lane
Jul 17, 2001



Transformation-based learning has been successfully employed to solve many natural language processing problems. It achieves state-of-the-art performance on many natural language processing tasks and does not overtrain easily. However, it does have a serious drawback: the training time is often intorelably long, especially on the large corpora which are often used in NLP. In this paper, we present a novel and realistic method for speeding up the training time of a transformation-based learner without sacrificing performance. The paper compares and contrasts the training time needed and performance achieved by our modified learner with two other systems: a standard transformation-based learner, and the ICA system \cite{hepple00:tbl}. The results of these experiments show that our system is able to achieve a significant improvement in training time while still achieving the same performance as a standard transformation-based learner. This is a valuable contribution to systems and algorithms which utilize transformation-based learning at any part of the execution.
* 8 pages, 2 figures, presented at NAACL 2001
Rule Writing or Annotation: Cost-efficient Resource Usage for Base Noun Phrase Chunking
May 02, 2001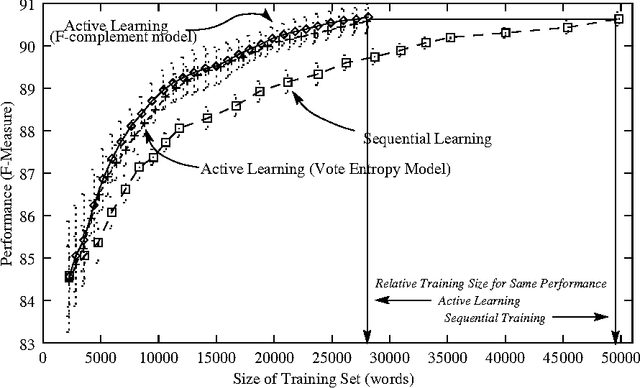
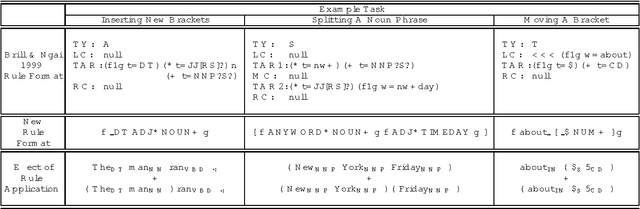
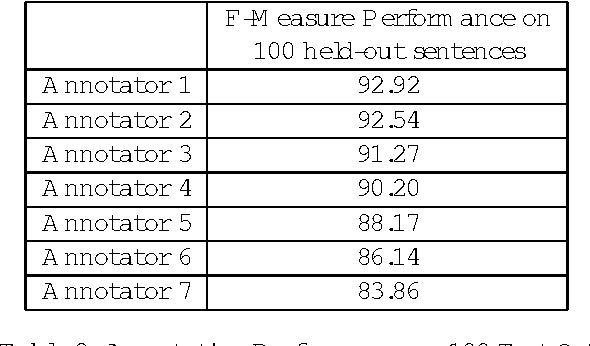
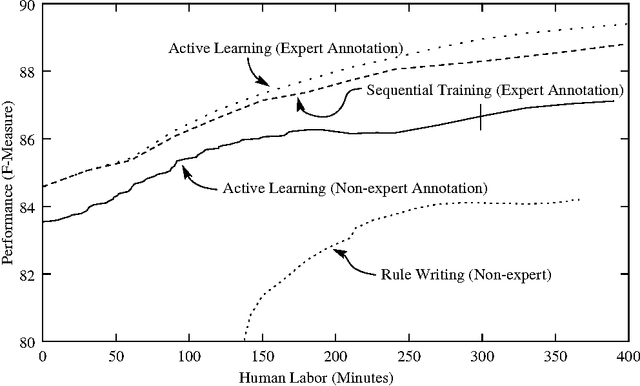
This paper presents a comprehensive empirical comparison between two approaches for developing a base noun phrase chunker: human rule writing and active learning using interactive real-time human annotation. Several novel variations on active learning are investigated, and underlying cost models for cross-modal machine learning comparison are presented and explored. Results show that it is more efficient and more successful by several measures to train a system using active learning annotation rather than hand-crafted rule writing at a comparable level of human labor investment.
* 9 pages, 4 figures, appeared in ACL2000
Man vs. Machine: A Case Study in Base Noun Phrase Learning
May 02, 2001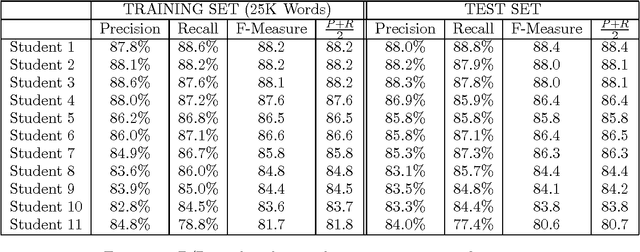

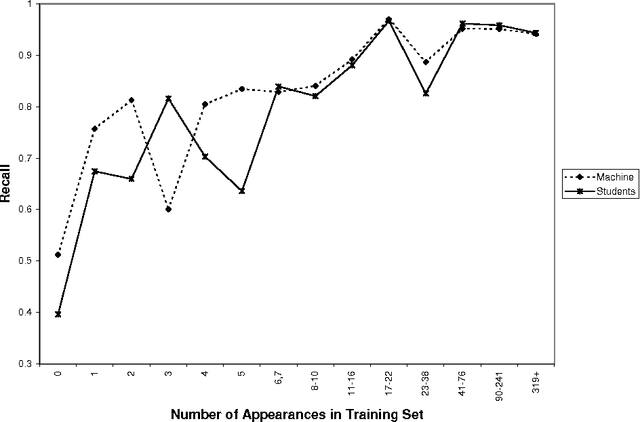

A great deal of work has been done demonstrating the ability of machine learning algorithms to automatically extract linguistic knowledge from annotated corpora. Very little work has gone into quantifying the difference in ability at this task between a person and a machine. This paper is a first step in that direction.
* 8 pages, 2 figures, presented at ACL 1999
Coaxing Confidences from an Old Friend: Probabilistic Classifications from Transformation Rule Lists
Apr 27, 2001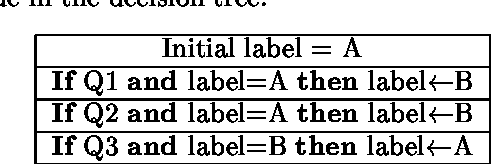
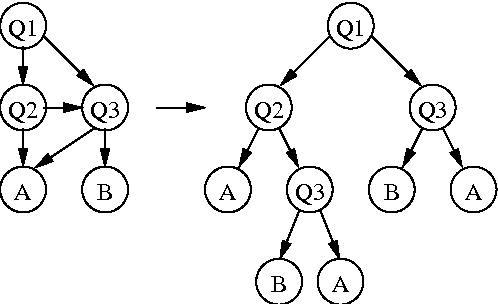
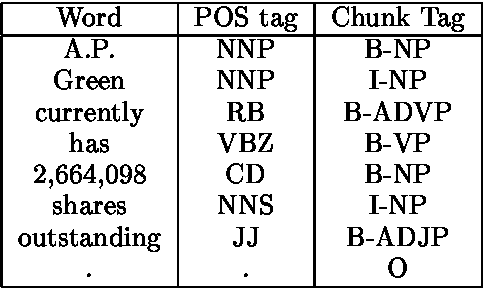
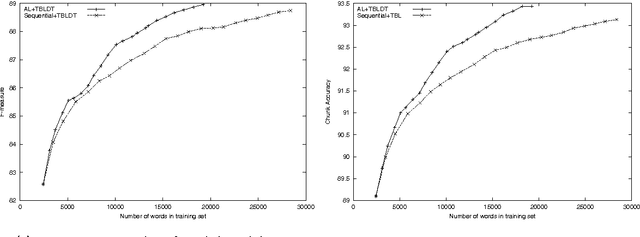
Transformation-based learning has been successfully employed to solve many natural language processing problems. It has many positive features, but one drawback is that it does not provide estimates of class membership probabilities. In this paper, we present a novel method for obtaining class membership probabilities from a transformation-based rule list classifier. Three experiments are presented which measure the modeling accuracy and cross-entropy of the probabilistic classifier on unseen data and the degree to which the output probabilities from the classifier can be used to estimate confidences in its classification decisions. The results of these experiments show that, for the task of text chunking, the estimates produced by this technique are more informative than those generated by a state-of-the-art decision tree.
* 9 pages, 4 figures, presented at EMNLP 2000