 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb-Based Question Answering: A Decision-Making Perspective
Oct 19, 2012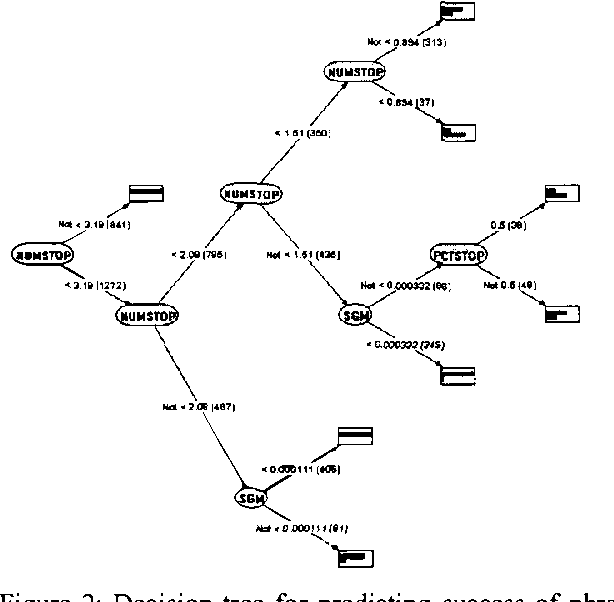


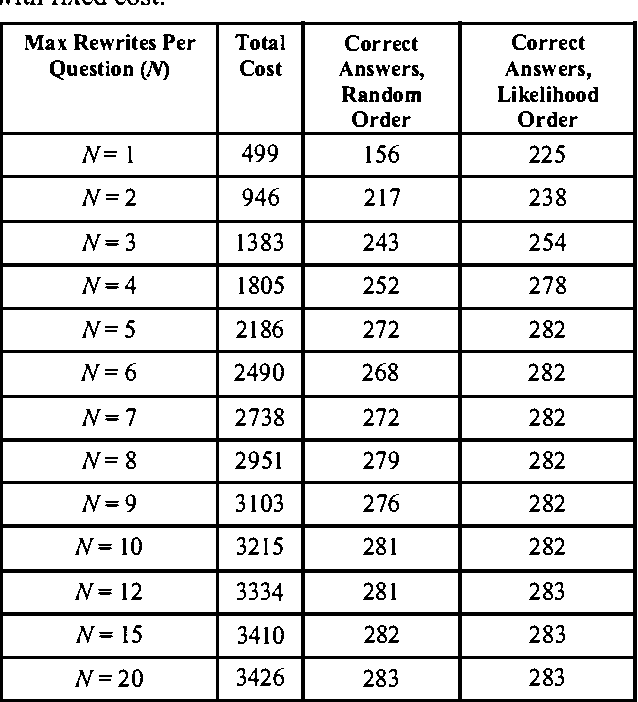
We describe an investigation of the use of probabilistic models and cost-benefit analyses to guide resource-intensive procedures used by a Web-based question answering system. We first provide an overview of research on question-answering systems. Then, we present details on AskMSR, a prototype web-based question answering system. We discuss Bayesian analyses of the quality of answers generated by the system and show how we can endow the system with the ability to make decisions about the number of queries issued to a search engine, given the cost of queries and the expected value of query results in refining an ultimate answer. Finally, we review the results of a set of experiments.
Man vs. Machine: A Case Study in Base Noun Phrase Learning
May 02, 2001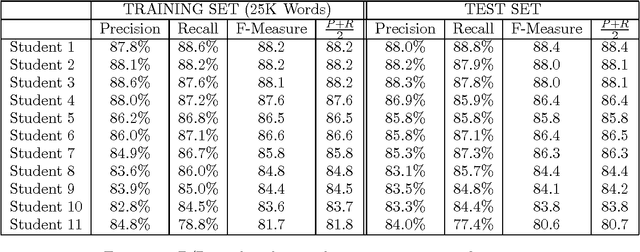

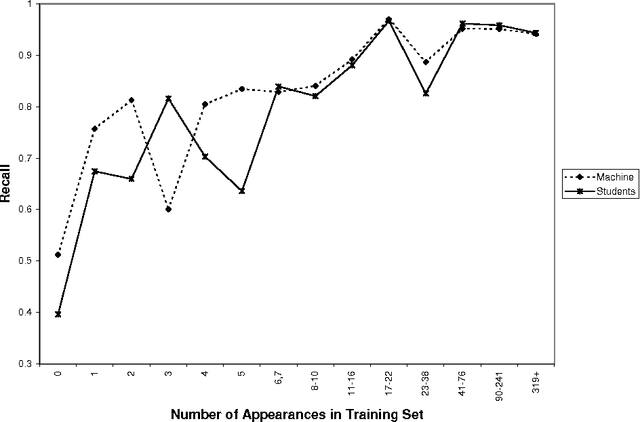

A great deal of work has been done demonstrating the ability of machine learning algorithms to automatically extract linguistic knowledge from annotated corpora. Very little work has gone into quantifying the difference in ability at this task between a person and a machine. This paper is a first step in that direction.
* 8 pages, 2 figures, presented at ACL 1999
Bagging and Boosting a Treebank Parser
Jun 05, 2000Bagging and boosting, two effective machine learning techniques, are applied to natural language parsing. Experiments using these techniques with a trainable statistical parser are described. The best resulting system provides roughly as large of a gain in F-measure as doubling the corpus size. Error analysis of the result of the boosting technique reveals some inconsistent annotations in the Penn Treebank, suggesting a semi-automatic method for finding inconsistent treebank annotations.
* 8 pages
Exploiting Diversity in Natural Language Processing: Combining Parsers
Jun 01, 2000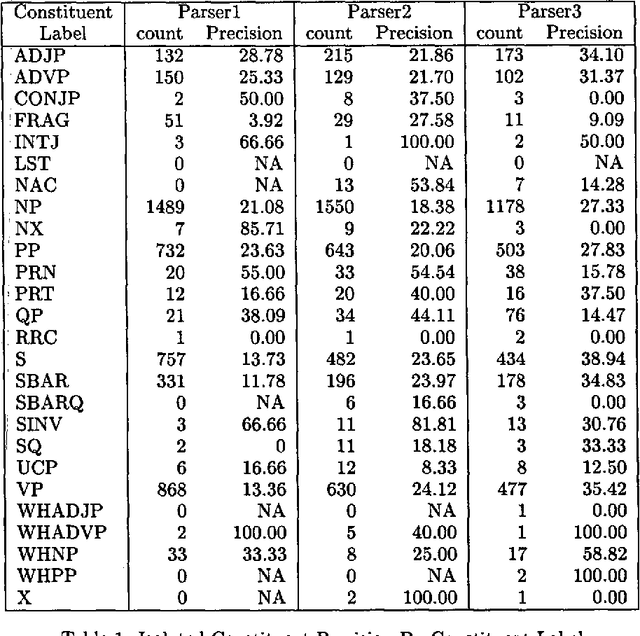
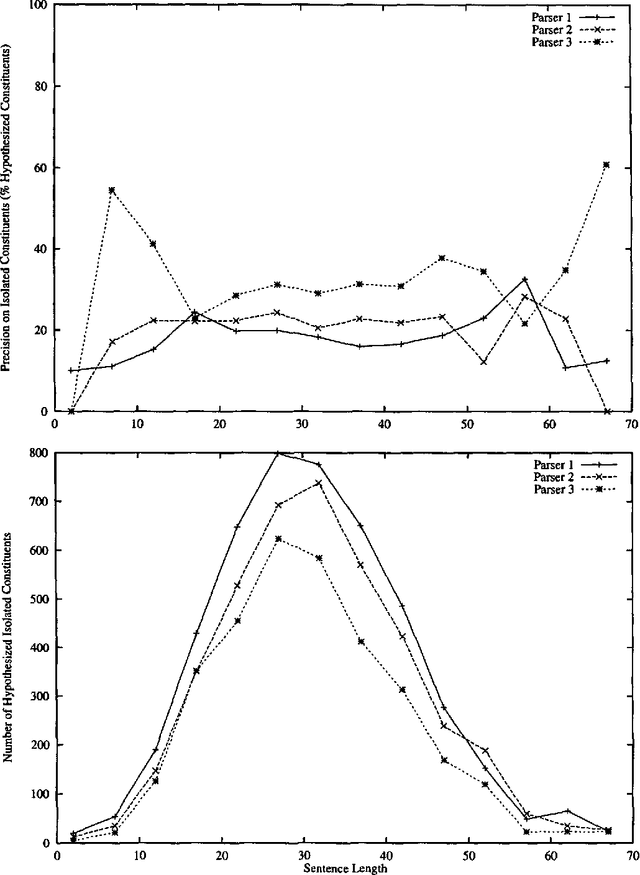
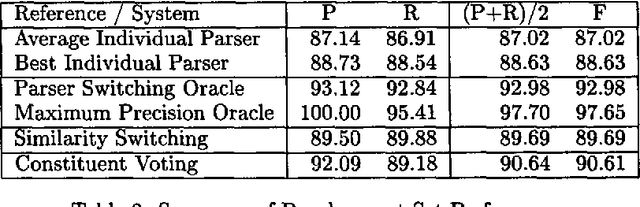
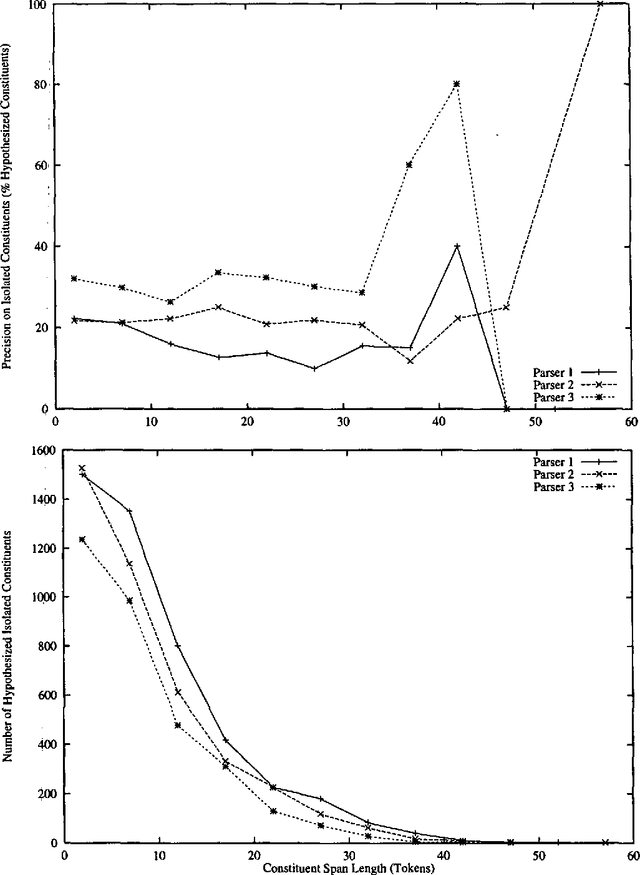
Three state-of-the-art statistical parsers are combined to produce more accurate parses, as well as new bounds on achievable Treebank parsing accuracy. Two general approaches are presented and two combination techniques are described for each approach. Both parametric and non-parametric models are explored. The resulting parsers surpass the best previously published performance results for the Penn Treebank.
* 8 pages
A Rule-Based Approach To Prepositional Phrase Attachment Disambiguation
Oct 25, 1994



In this paper, we describe a new corpus-based approach to prepositional phrase attachment disambiguation, and present results comparing performance of this algorithm with other corpus-based approaches to this problem.
* 7 pages, compressed uuencoded postscript
Some Advances in Transformation-Based Part of Speech Tagging
Jun 02, 1994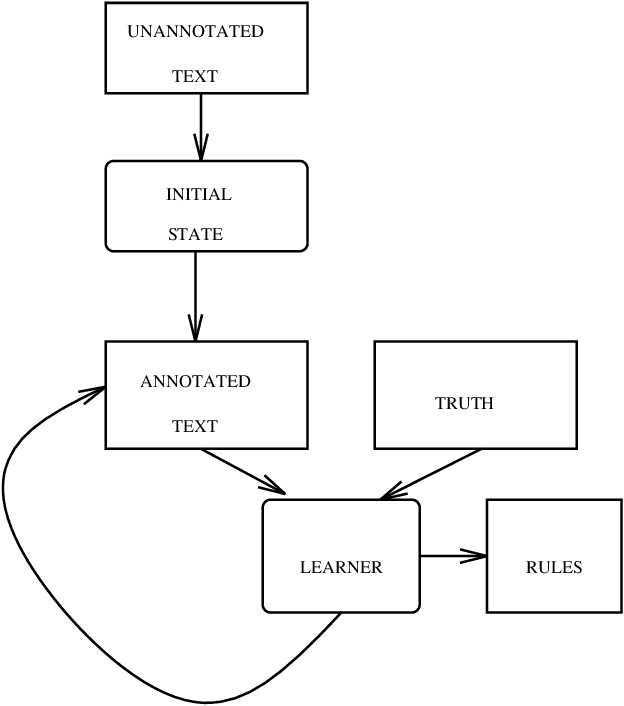


Most recent research in trainable part of speech taggers has explored stochastic tagging. While these taggers obtain high accuracy, linguistic information is captured indirectly, typically in tens of thousands of lexical and contextual probabilities. In [Brill92], a trainable rule-based tagger was described that obtained performance comparable to that of stochastic taggers, but captured relevant linguistic information in a small number of simple non-stochastic rules. In this paper, we describe a number of extensions to this rule-based tagger. First, we describe a method for expressing lexical relations in tagging that are not captured by stochastic taggers. Next, we show a rule-based approach to tagging unknown words. Finally, we show how the tagger can be extended into a k-best tagger, where multiple tags can be assigned to words in some cases of uncertainty.
* 6 Pages. Code available