Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Diversity in Natural Language Processing: Combining Parsers
Paper and Code
Jun 01, 2000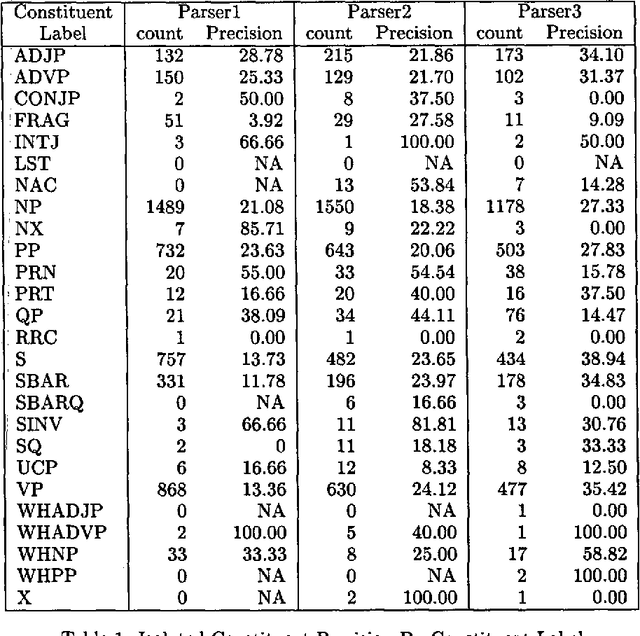
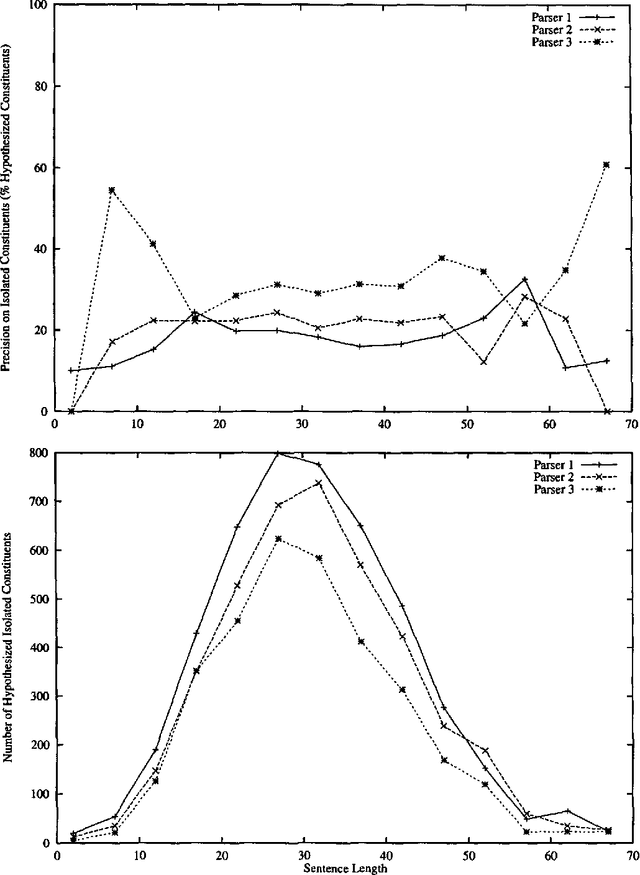
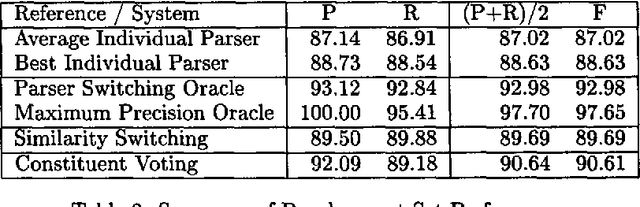
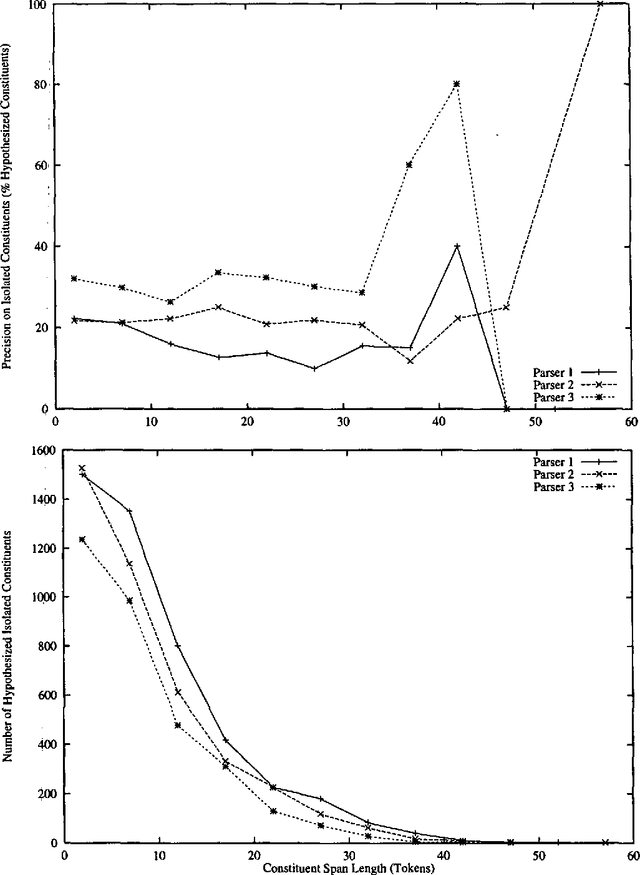
Three state-of-the-art statistical parsers are combined to produce more accurate parses, as well as new bounds on achievable Treebank parsing accuracy. Two general approaches are presented and two combination techniques are described for each approach. Both parametric and non-parametric models are explored. The resulting parsers surpass the best previously published performance results for the Penn Treebank.
* Proceedings of the Fourth Conference on Empirical Methods in
Natural Language Processing (EMNLP-99), pages 187-194. College Park,
Maryland, USA. June, 1999 * 8 pages
View paper on