 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoaxing Confidences from an Old Friend: Probabilistic Classifications from Transformation Rule Lists
Apr 27, 2001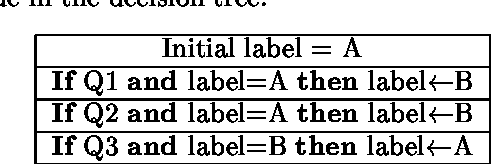
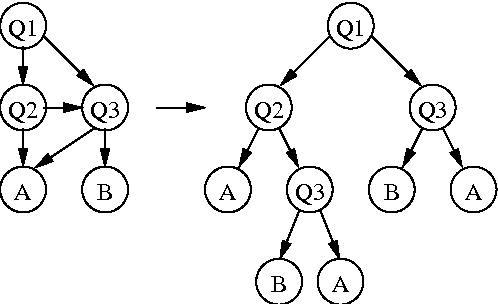
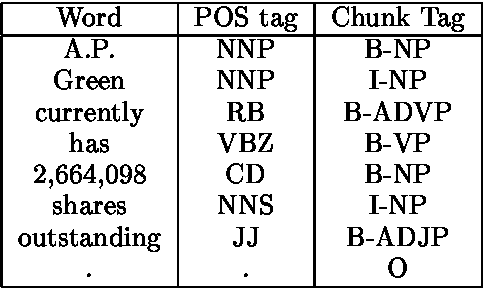
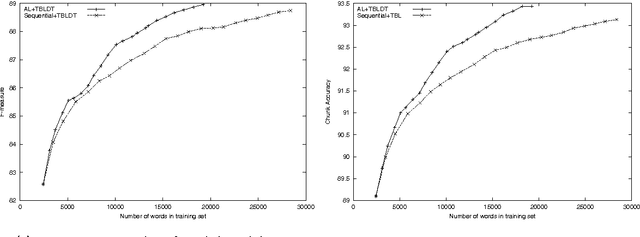
Transformation-based learning has been successfully employed to solve many natural language processing problems. It has many positive features, but one drawback is that it does not provide estimates of class membership probabilities. In this paper, we present a novel method for obtaining class membership probabilities from a transformation-based rule list classifier. Three experiments are presented which measure the modeling accuracy and cross-entropy of the probabilistic classifier on unseen data and the degree to which the output probabilities from the classifier can be used to estimate confidences in its classification decisions. The results of these experiments show that, for the task of text chunking, the estimates produced by this technique are more informative than those generated by a state-of-the-art decision tree.
* 9 pages, 4 figures, presented at EMNLP 2000
Exploiting Diversity for Natural Language Parsing
Jun 05, 2000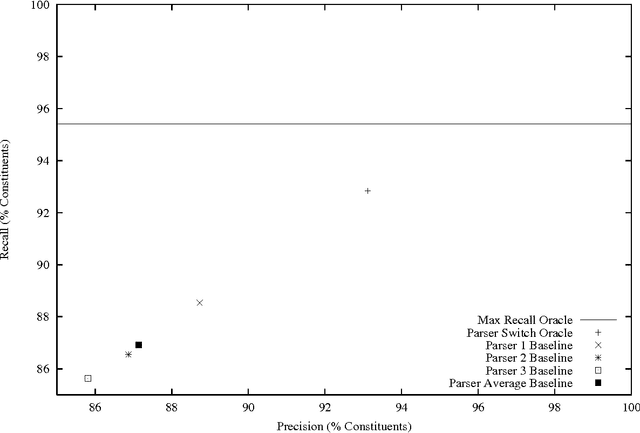
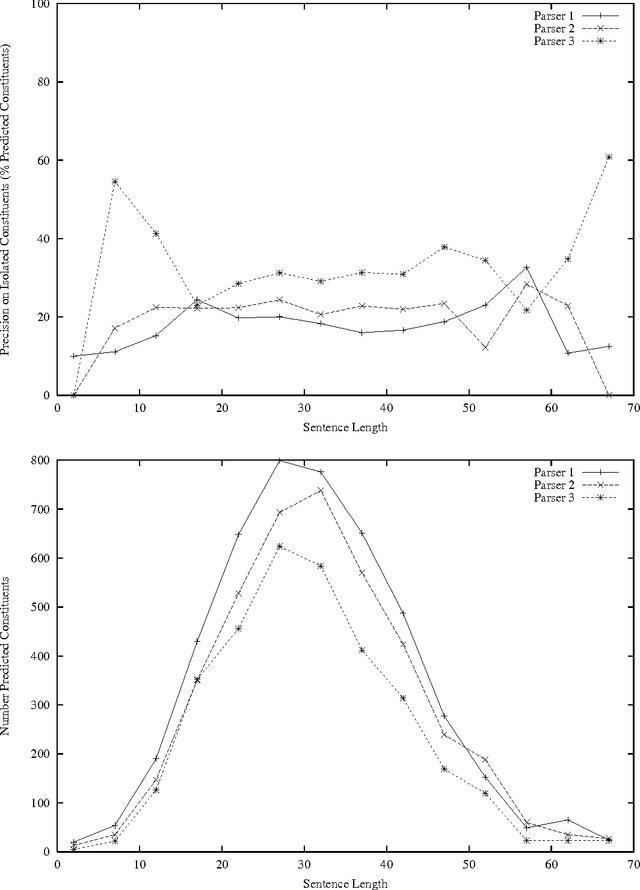
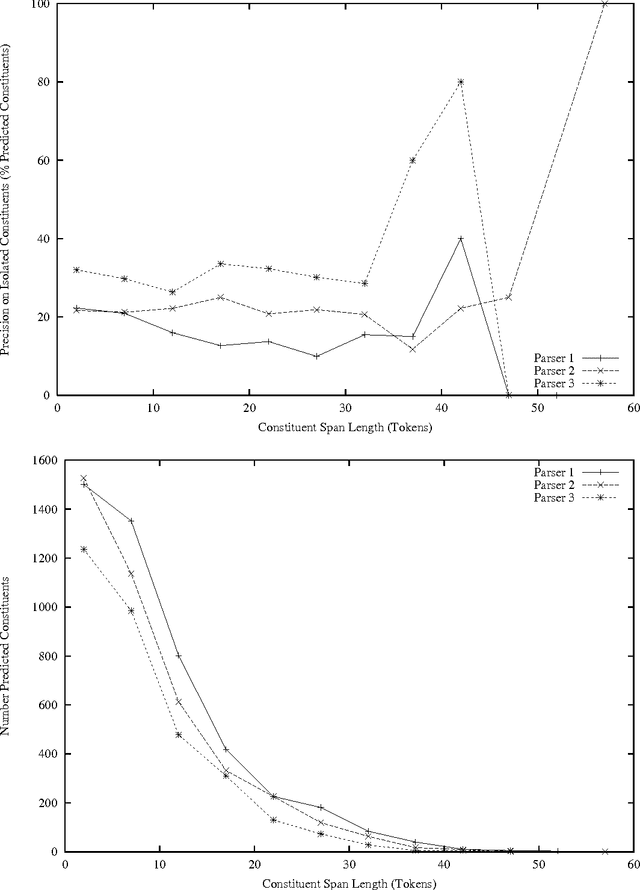
The popularity of applying machine learning methods to computational linguistics problems has produced a large supply of trainable natural language processing systems. Most problems of interest have an array of off-the-shelf products or downloadable code implementing solutions using various techniques. Where these solutions are developed independently, it is observed that their errors tend to be independently distributed. This thesis is concerned with approaches for capitalizing on this situation in a sample problem domain, Penn Treebank-style parsing. The machine learning community provides techniques for combining outputs of classifiers, but parser output is more structured and interdependent than classifications. To address this discrepancy, two novel strategies for combining parsers are used: learning to control a switch between parsers and constructing a hybrid parse from multiple parsers' outputs. Off-the-shelf parsers are not developed with an intention to perform well in a collaborative ensemble. Two techniques are presented for producing an ensemble of parsers that collaborate. All of the ensemble members are created using the same underlying parser induction algorithm, and the method for producing complementary parsers is only loosely constrained by that chosen algorithm.
Bagging and Boosting a Treebank Parser
Jun 05, 2000Bagging and boosting, two effective machine learning techniques, are applied to natural language parsing. Experiments using these techniques with a trainable statistical parser are described. The best resulting system provides roughly as large of a gain in F-measure as doubling the corpus size. Error analysis of the result of the boosting technique reveals some inconsistent annotations in the Penn Treebank, suggesting a semi-automatic method for finding inconsistent treebank annotations.
* 8 pages
Exploiting Diversity in Natural Language Processing: Combining Parsers
Jun 01, 2000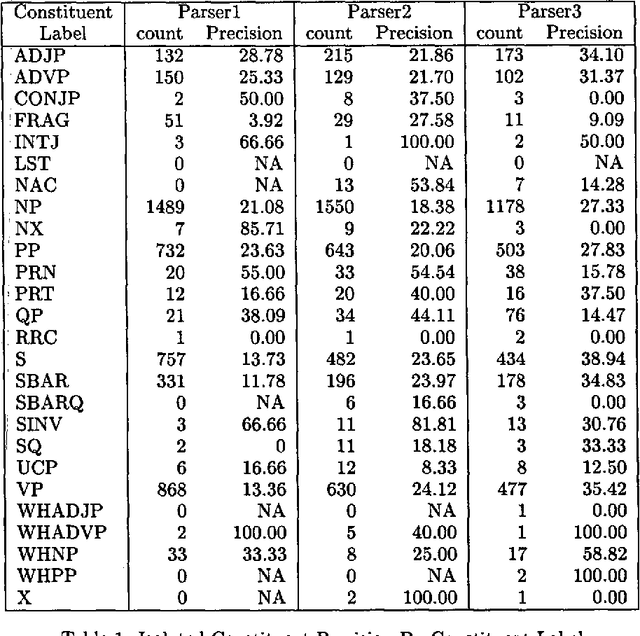
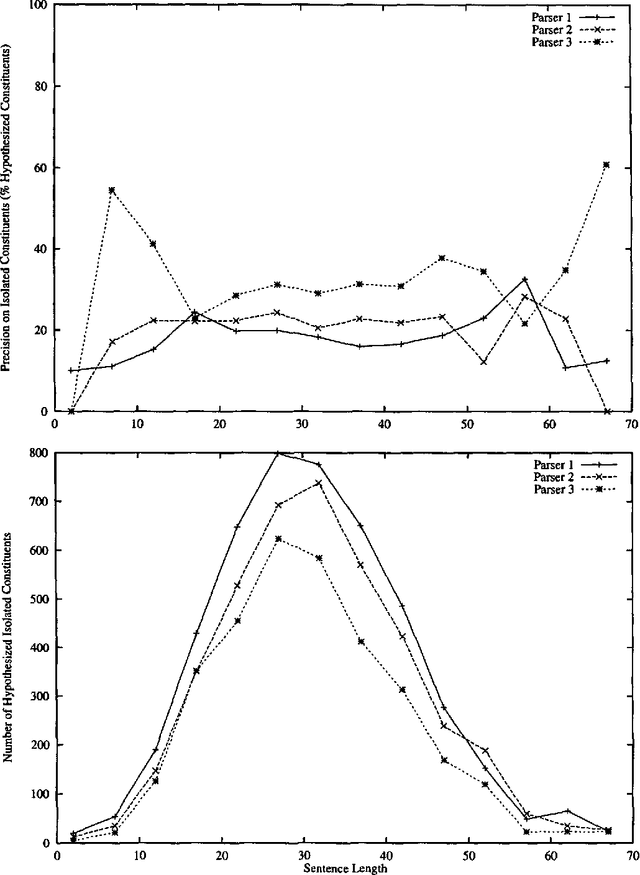
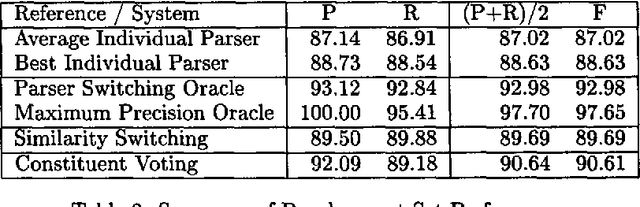
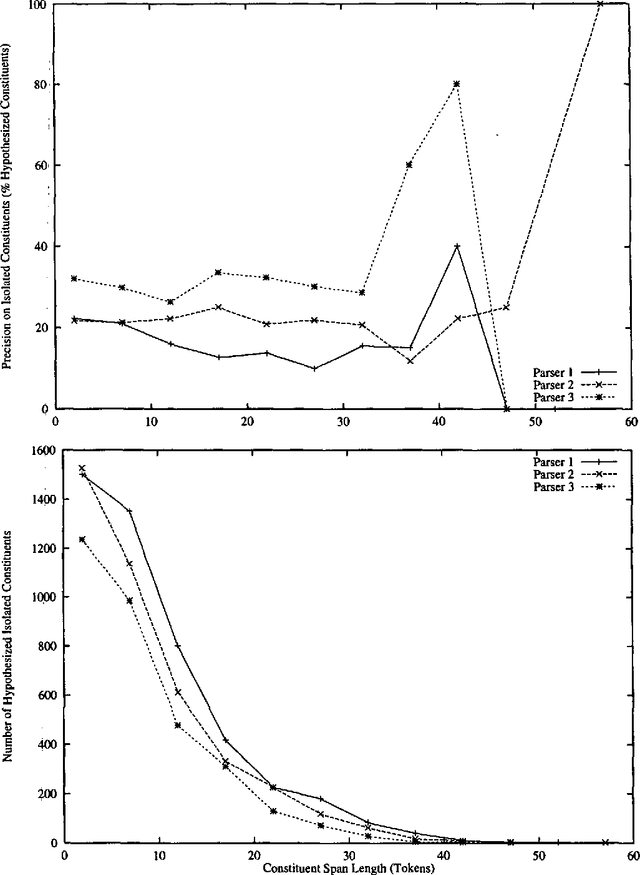
Three state-of-the-art statistical parsers are combined to produce more accurate parses, as well as new bounds on achievable Treebank parsing accuracy. Two general approaches are presented and two combination techniques are described for each approach. Both parametric and non-parametric models are explored. The resulting parsers surpass the best previously published performance results for the Penn Treebank.
* 8 pages