 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Weak Supervision for Email Intent Detection
May 26, 2020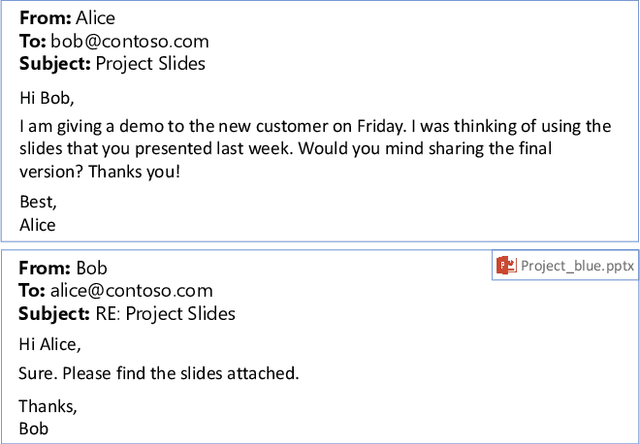

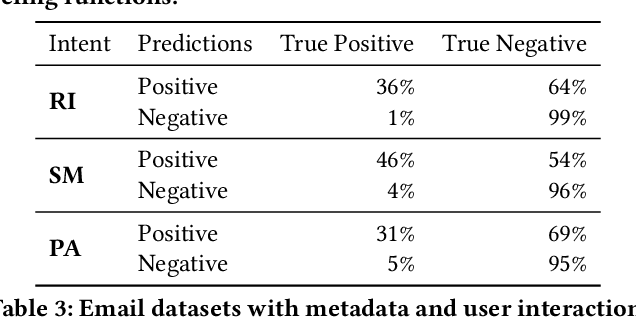
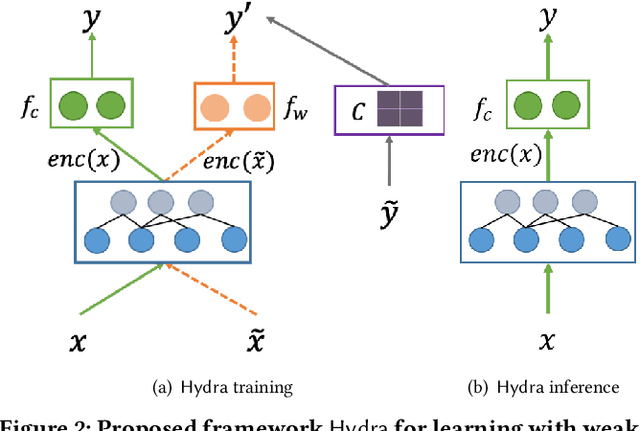
Email remains one of the most frequently used means of online communication. People spend a significant amount of time every day on emails to exchange information, manage tasks and schedule events. Previous work has studied different ways for improving email productivity by prioritizing emails, suggesting automatic replies or identifying intents to recommend appropriate actions. The problem has been mostly posed as a supervised learning problem where models of different complexities were proposed to classify an email message into a predefined taxonomy of intents or classes. The need for labeled data has always been one of the largest bottlenecks in training supervised models. This is especially the case for many real-world tasks, such as email intent classification, where large scale annotated examples are either hard to acquire or unavailable due to privacy or data access constraints. Email users often take actions in response to intents expressed in an email (e.g., setting up a meeting in response to an email with a scheduling request). Such actions can be inferred from user interaction logs. In this paper, we propose to leverage user actions as a source of weak supervision, in addition to a limited set of annotated examples, to detect intents in emails. We develop an end-to-end robust deep neural network model for email intent identification that leverages both clean annotated data and noisy weak supervision along with a self-paced learning mechanism. Extensive experiments on three different intent detection tasks show that our approach can effectively leverage the weakly supervised data to improve intent detection in emails.
* 10 pages, 3 figures
Meta Label Correction for Learning with Weak Supervision
Nov 10, 2019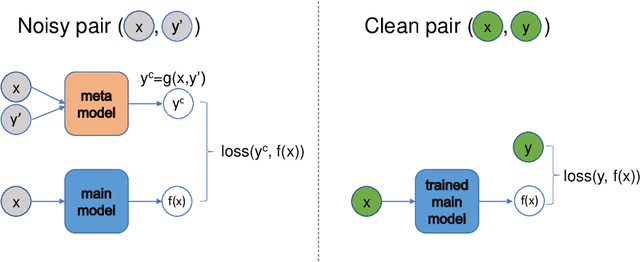

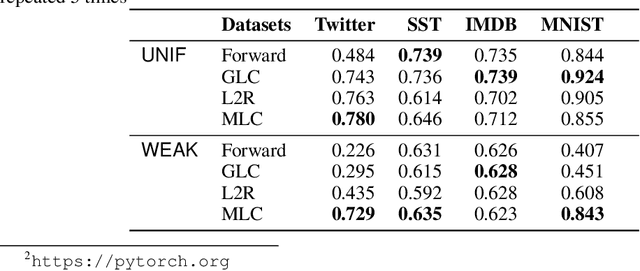
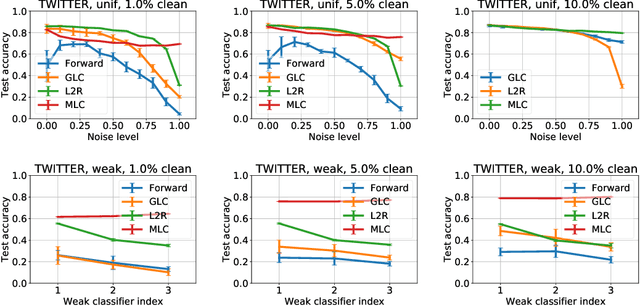
Leveraging weak or noisy supervision for building effective machine learning models has long been an important research problem. The growing need for large-scale datasets to train deep learning models has increased its importance. Weak or noisy supervision could originate from multiple sources including non-expert annotators or automatic labeling based on heuristics or user interaction signals. Previous work on modeling and correcting weak labels have been focused on various aspects, including loss correction, training instance re-weighting, etc. In this paper, we approach this problem from a novel perspective based on meta-learning. We view the label correction procedure as a meta-process and propose a new meta-learning based framework termed MLC for learning with weak supervision. Experiments with different label noise levels on multiple datasets show that MLC can achieve large improvement over previous methods incorporating weak labels for learning.
Web-Based Question Answering: A Decision-Making Perspective
Oct 19, 2012


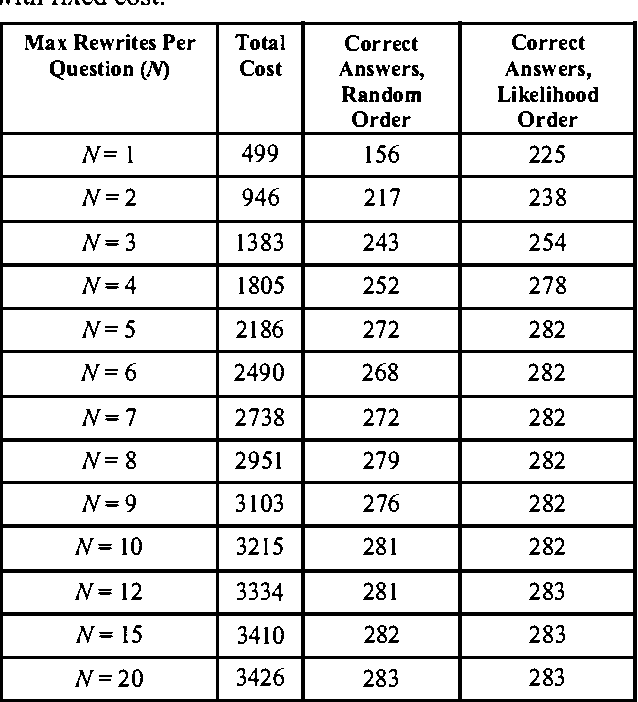
We describe an investigation of the use of probabilistic models and cost-benefit analyses to guide resource-intensive procedures used by a Web-based question answering system. We first provide an overview of research on question-answering systems. Then, we present details on AskMSR, a prototype web-based question answering system. We discuss Bayesian analyses of the quality of answers generated by the system and show how we can endow the system with the ability to make decisions about the number of queries issued to a search engine, given the cost of queries and the expected value of query results in refining an ultimate answer. Finally, we review the results of a set of experiments.
Mark My Words! Linguistic Style Accommodation in Social Media
May 03, 2011
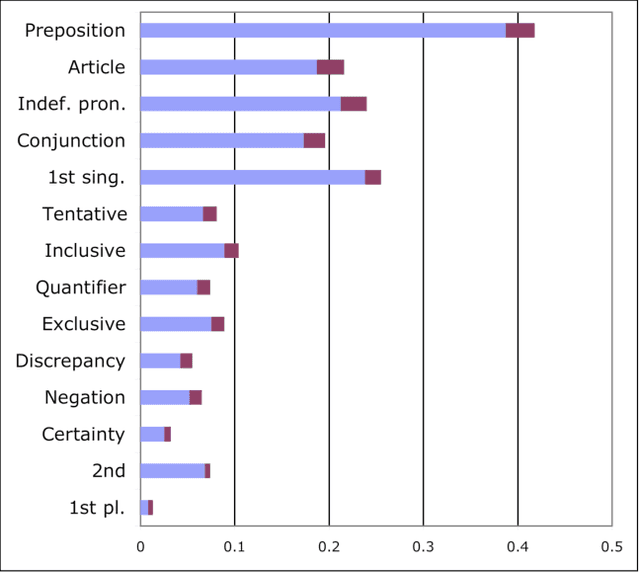
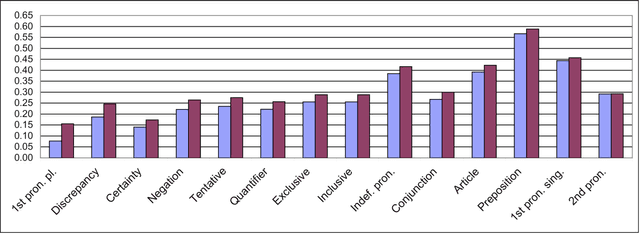
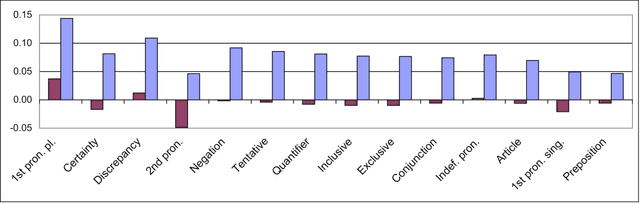
The psycholinguistic theory of communication accommodation accounts for the general observation that participants in conversations tend to converge to one another's communicative behavior: they coordinate in a variety of dimensions including choice of words, syntax, utterance length, pitch and gestures. In its almost forty years of existence, this theory has been empirically supported exclusively through small-scale or controlled laboratory studies. Here we address this phenomenon in the context of Twitter conversations. Undoubtedly, this setting is unlike any other in which accommodation was observed and, thus, challenging to the theory. Its novelty comes not only from its size, but also from the non real-time nature of conversations, from the 140 character length restriction, from the wide variety of social relation types, and from a design that was initially not geared towards conversation at all. Given such constraints, it is not clear a priori whether accommodation is robust enough to occur given the constraints of this new environment. To investigate this, we develop a probabilistic framework that can model accommodation and measure its effects. We apply it to a large Twitter conversational dataset specifically developed for this task. This is the first time the hypothesis of linguistic style accommodation has been examined (and verified) in a large scale, real world setting. Furthermore, when investigating concepts such as stylistic influence and symmetry of accommodation, we discover a complexity of the phenomenon which was never observed before. We also explore the potential relation between stylistic influence and network features commonly associated with social status.
* Talk slides available at http://www.cs.cornell.edu/~cristian/www2011