 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approximate Nonmyopic Computation for Value of Information
May 16, 2015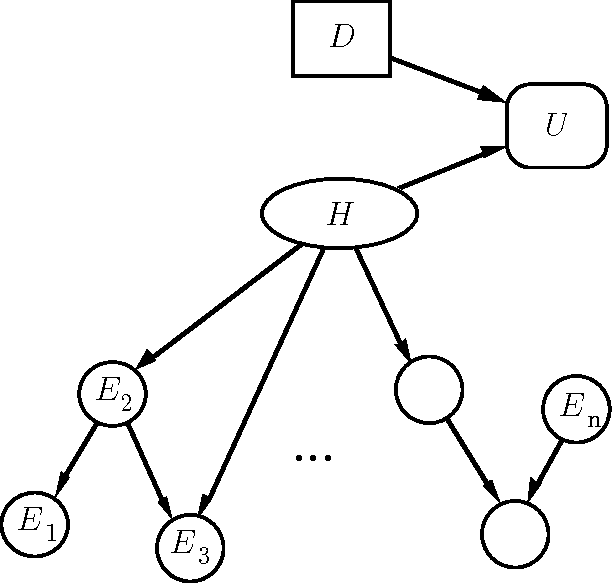
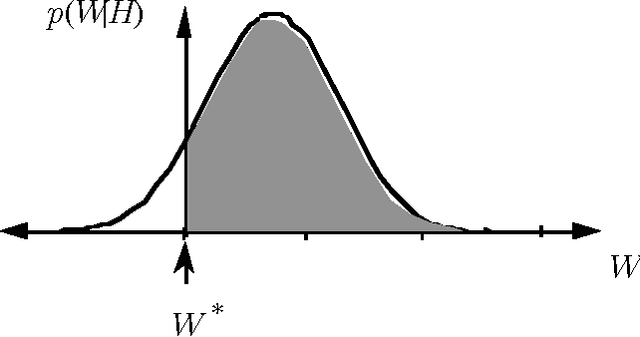
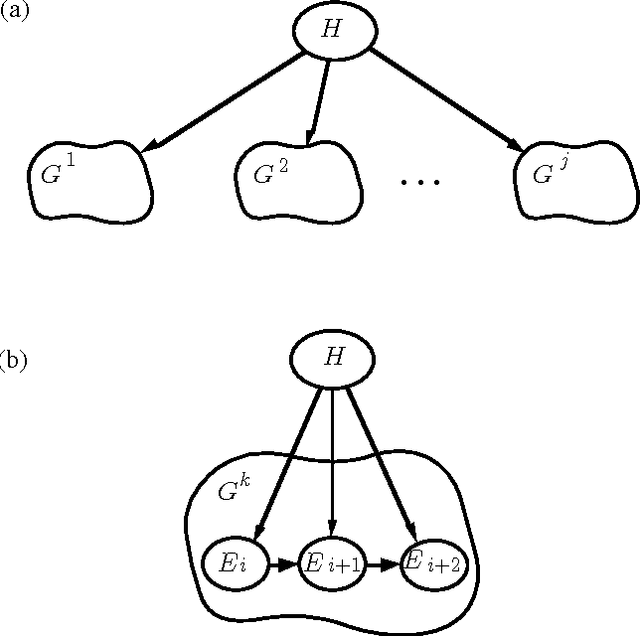
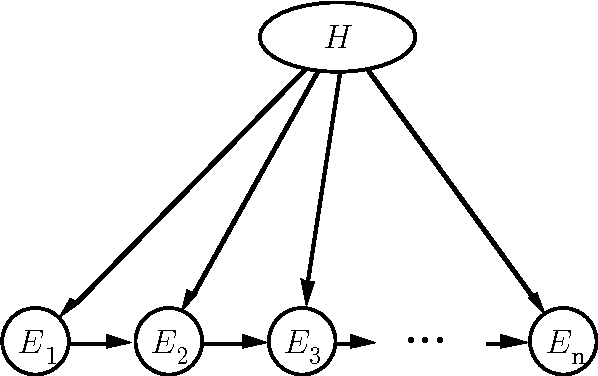
Value-of-information analyses provide a straightforward means for selecting the best next observation to make, and for determining whether it is better to gather additional information or to act immediately. Determining the next best test to perform, given a state of uncertainty about the world, requires a consideration of the value of making all possible sequences of observations. In practice, decision analysts and expert-system designers have avoided the intractability of exact computation of the value of information by relying on a myopic approximation. Myopic analyses are based on the assumption that only one additional test will be performed, even when there is an opportunity to make a large number of observations. We present a nonmyopic approximation for value of information that bypasses the traditional myopic analyses by exploiting the statistical properties of large samples.
Problem Formulation as the Reduction of a Decision Model
May 16, 2015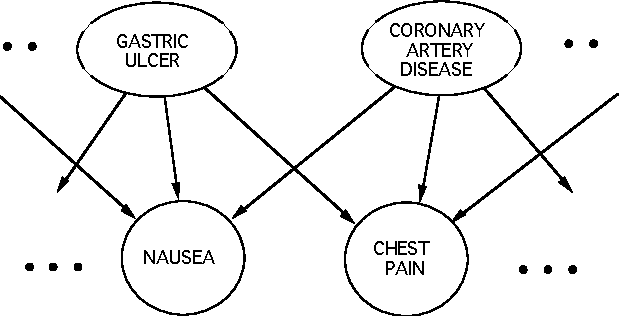


In this paper, we extend the QMRDT probabilistic model for the domain of internal medicine to include decisions about treatments. In addition, we describe how we can use the comprehensive decision model to construct a simpler decision model for a specific patient. In so doing, we transform the task of problem formulation to that of narrowing of a larger problem.
Inferring Informational Goals from Free-Text Queries: A Bayesian Approach
May 16, 2015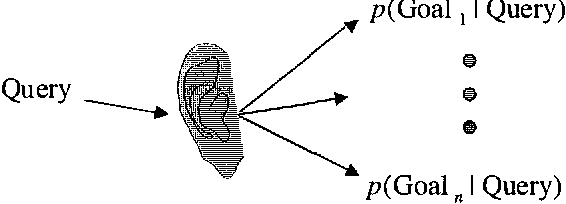
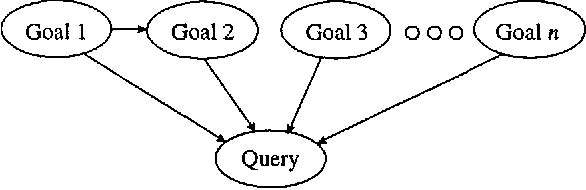
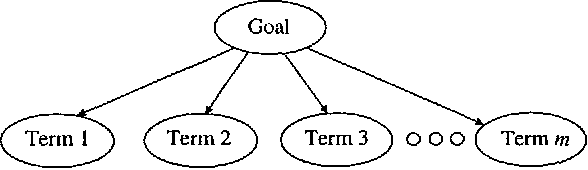
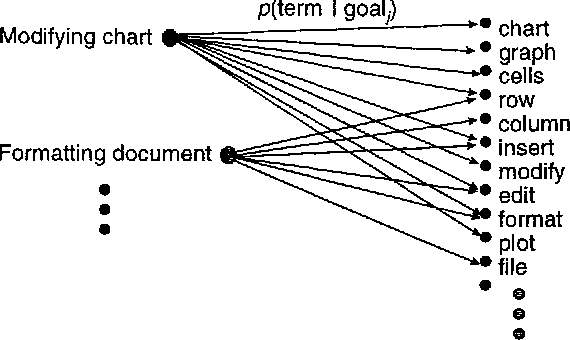
People using consumer software applications typically do not use technical jargon when querying an online database of help topics. Rather, they attempt to communicate their goals with common words and phrases that describe software functionality in terms of structure and objects they understand. We describe a Bayesian approach to modeling the relationship between words in a user's query for assistance and the informational goals of the user. After reviewing the general method, we describe several extensions that center on integrating additional distinctions and structure about language usage and user goals into the Bayesian models.
Modular Belief Updates and Confusion about Measures of Certainty in Artificial Intelligence Research
Jul 27, 2014Over the last decade, there has been growing interest in the use or measures or change in belief for reasoning with uncertainty in artificial intelligence research. An important characteristic of several methodologies that reason with changes in belief or belief updates, is a property that we term modularity. We call updates that satisfy this property modular updates. Whereas probabilistic measures of belief update - which satisfy the modularity property were first discovered in the nineteenth century, knowledge and discussion of these quantities remains obscure in artificial intelligence research. We define modular updates and discuss their inappropriate use in two influential expert systems.
The Myth of Modularity in Rule-Based Systems
Mar 27, 2013

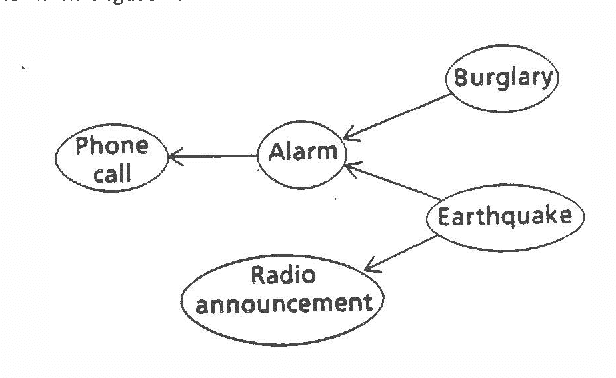
In this paper, we examine the concept of modularity, an often cited advantage of the ruled-based representation methodology. We argue that the notion of modularity consists of two distinct concepts which we call syntactic modularity and semantic modularity. We argue that when reasoning under certainty, it is reasonable to regard the rule-based approach as both syntactically and semantically modular. However, we argue that in the case of plausible reasoning, rules are syntactically modular but are rarely semantically modular. To illustrate this point, we examine a particular approach for managing uncertainty in rule-based systems called the MYCIN certainty factor model. We formally define the concept of semantic modularity with respect to the certainty factor model and discuss logical consequences of the definition. We show that the assumption of semantic modularity imposes strong restrictions on rules in a knowledge base. We argue that such restrictions are rarely valid in practical applications. Finally, we suggest how the concept of semantic modularity can be relaxed in a manner that makes it appropriate for plausible reasoning.
Reasoning About Beliefs and Actions Under Computational Resource Constraints
Mar 27, 2013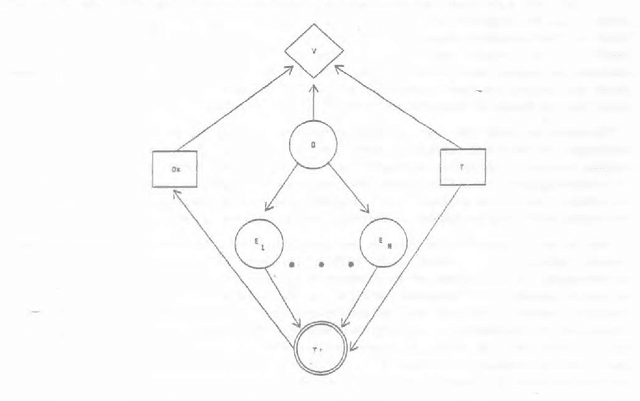

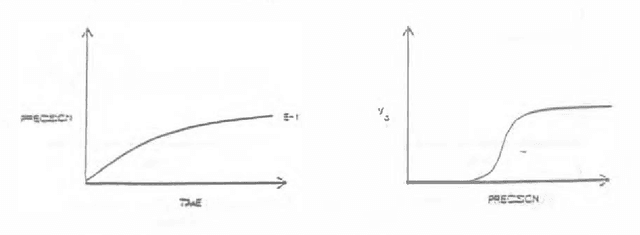
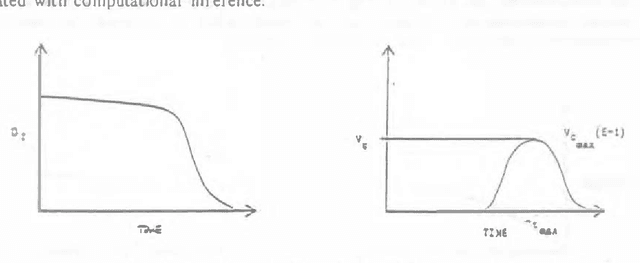
Although many investigators affirm a desire to build reasoning systems that behave consistently with the axiomatic basis defined by probability theory and utility theory, limited resources for engineering and computation can make a complete normative analysis impossible. We attempt to move discussion beyond the debate over the scope of problems that can be handled effectively to cases where it is clear that there are insufficient computational resources to perform an analysis deemed as complete. Under these conditions, we stress the importance of considering the expected costs and benefits of applying alternative approximation procedures and heuristics for computation and knowledge acquisition. We discuss how knowledge about the structure of user utility can be used to control value tradeoffs for tailoring inference to alternative contexts. We address the notion of real-time rationality, focusing on the application of knowledge about the expected timewise-refinement abilities of reasoning strategies to balance the benefits of additional computation with the costs of acting with a partial result. We discuss the benefits of applying decision theory to control the solution of difficult problems given limitations and uncertainty in reasoning resources.
Bounded Conditioning: Flexible Inference for Decisions under Scarce Resources
Mar 27, 2013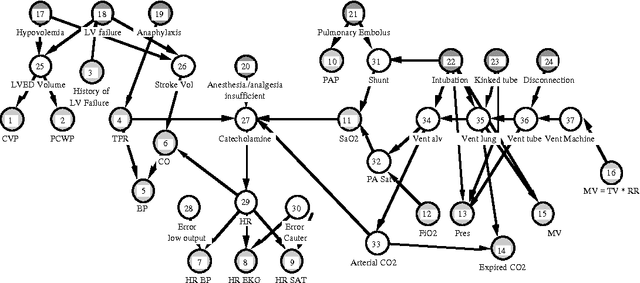
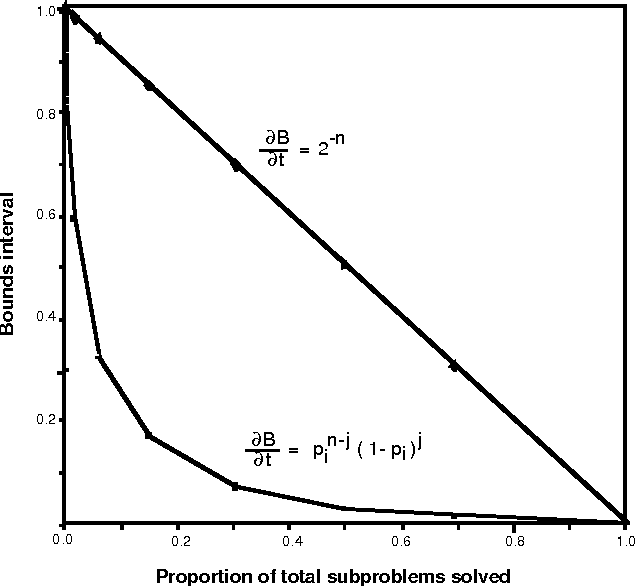
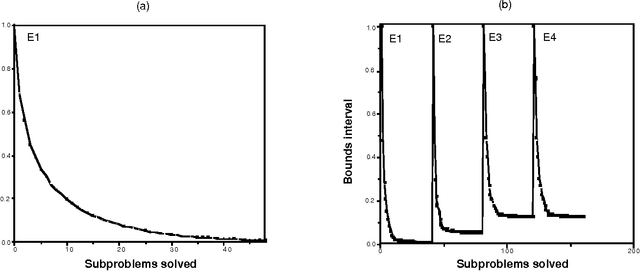
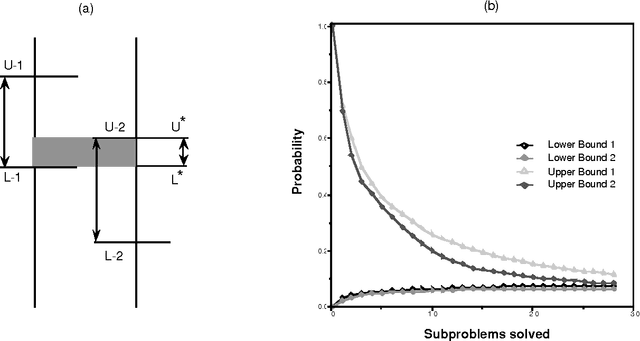
We introduce a graceful approach to probabilistic inference called bounded conditioning. Bounded conditioning monotonically refines the bounds on posterior probabilities in a belief network with computation, and converges on final probabilities of interest with the allocation of a complete resource fraction. The approach allows a reasoner to exchange arbitrary quantities of computational resource for incremental gains in inference quality. As such, bounded conditioning holds promise as a useful inference technique for reasoning under the general conditions of uncertain and varying reasoning resources. The algorithm solves a probabilistic bounding problem in complex belief networks by breaking the problem into a set of mutually exclusive, tractable subproblems and ordering their solution by the expected effect that each subproblem will have on the final answer. We introduce the algorithm, discuss its characterization, and present its performance on several belief networks, including a complex model for reasoning about problems in intensive-care medicine.
The Compilation of Decision Models
Mar 27, 2013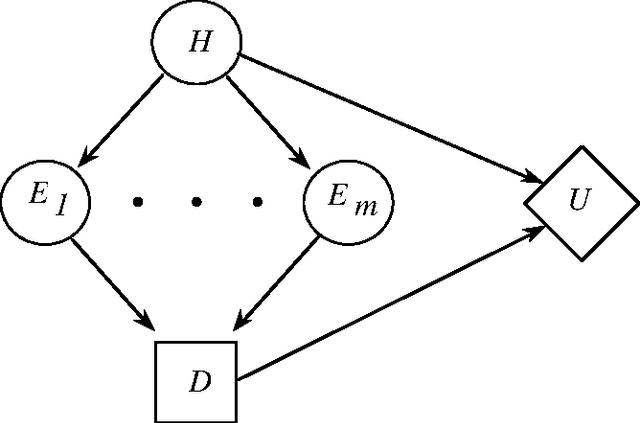



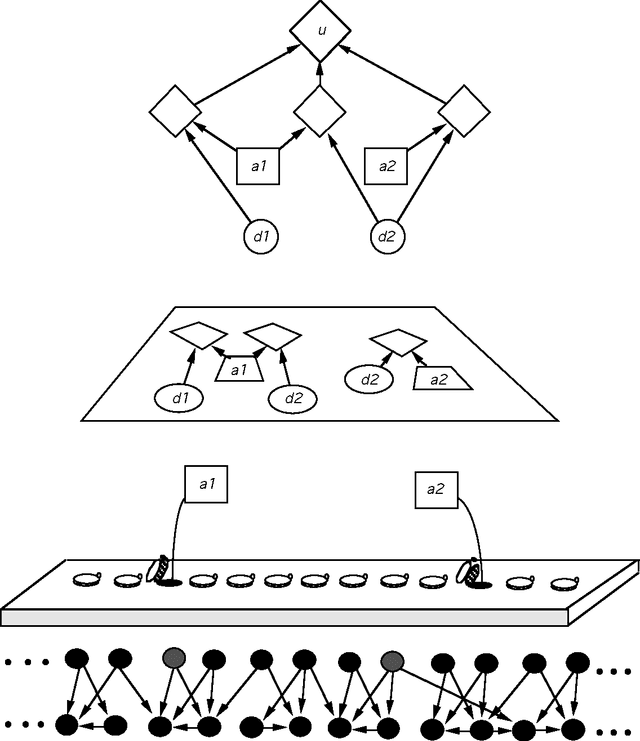
We introduce and analyze the problem of the compilation of decision models from a decision-theoretic perspective. The techniques described allow us to evaluate various configurations of compiled knowledge given the nature of evidential relationships in a domain, the utilities associated with alternative actions, the costs of run-time delays, and the costs of memory. We describe procedures for selecting a subset of the total observations available to be incorporated into a compiled situation-action mapping, in the context of a binary decision with conditional independence of evidence. The methods allow us to incrementally select the best pieces of evidence to add to the set of compiled knowledge in an engineering setting. After presenting several approaches to compilation, we exercise one of the methods to provide insight into the relationship between the distribution over weights of evidence and the preferred degree of compilation.
Ideal Reformulation of Belief Networks
Mar 27, 2013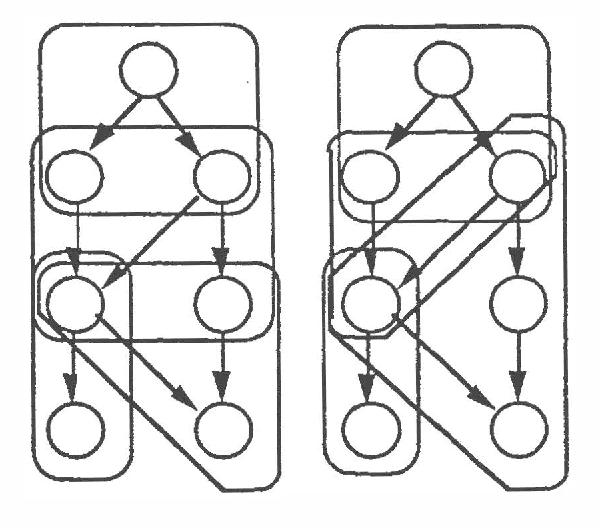

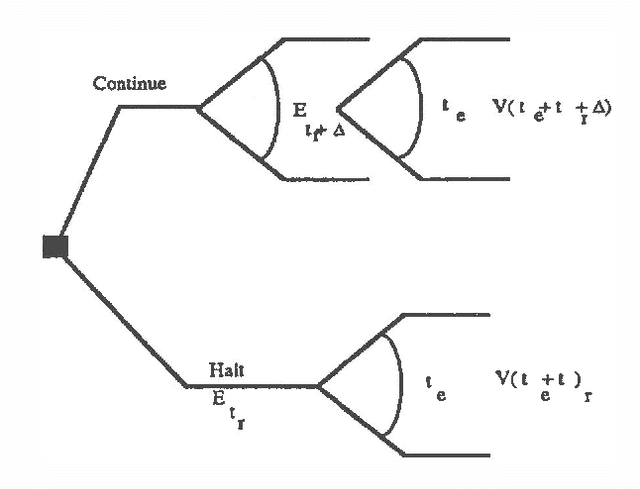
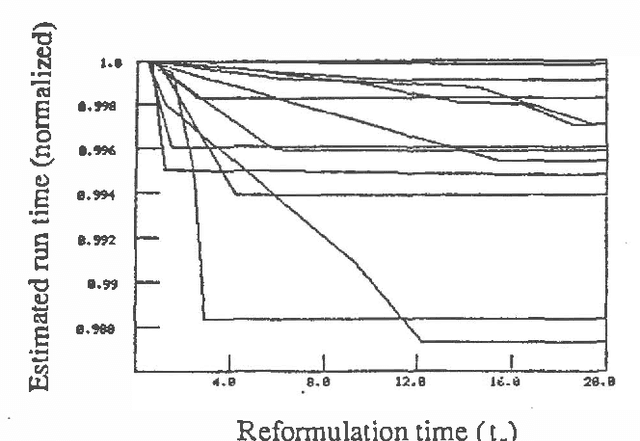
The intelligent reformulation or restructuring of a belief network can greatly increase the efficiency of inference. However, time expended for reformulation is not available for performing inference. Thus, under time pressure, there is a tradeoff between the time dedicated to reformulating the network and the time applied to the implementation of a solution. We investigate this partition of resources into time applied to reformulation and time used for inference. We shall describe first general principles for computing the ideal partition of resources under uncertainty. These principles have applicability to a wide variety of problems that can be divided into interdependent phases of problem solving. After, we shall present results of our empirical study of the problem of determining the ideal amount of time to devote to searching for clusters in belief networks. In this work, we acquired and made use of probability distributions that characterize (1) the performance of alternative heuristic search methods for reformulating a network instance into a set of cliques, and (2) the time for executing inference procedures on various belief networks. Given a preference model describing the value of a solution as a function of the delay required for its computation, the system selects an ideal time to devote to reformulation.
Time-Dependent Utility and Action Under Uncertainty
Mar 20, 2013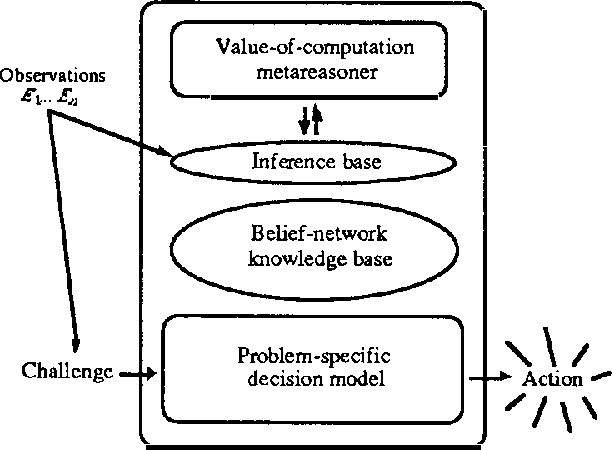
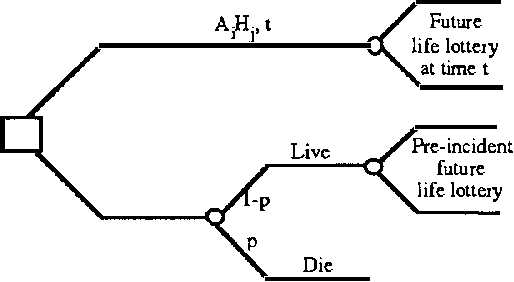


We discuss representing and reasoning with knowledge about the time-dependent utility of an agent's actions. Time-dependent utility plays a crucial role in the interaction between computation and action under bounded resources. We present a semantics for time-dependent utility and describe the use of time-dependent information in decision contexts. We illustrate our discussion with examples of time-pressured reasoning in Protos, a system constructed to explore the ideal control of inference by reasoners with limit abilities.