 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSldprtNet: A Large-Scale Multimodal Dataset for CAD Generation in Language-Driven 3D Design
Mar 13, 2026We introduce SldprtNet, a large-scale dataset comprising over 242,000 industrial parts, designed for semantic-driven CAD modeling, geometric deep learning, and the training and fine-tuning of multimodal models for 3D design. The dataset provides 3D models in both .step and .sldprt formats to support diverse training and testing. To enable parametric modeling and facilitate dataset scalability, we developed supporting tools, an encoder and a decoder, which support 13 types of CAD commands and enable lossless transformation between 3D models and a structured text representation. Additionally, each sample is paired with a composite image created by merging seven rendered views from different viewpoints of the 3D model, effectively reducing input token length and accelerating inference. By combining this image with the parameterized text output from the encoder, we employ the lightweight multimodal language model Qwen2.5-VL-7B to generate a natural language description of each part's appearance and functionality. To ensure accuracy, we manually verified and aligned the generated descriptions, rendered images, and 3D models. These descriptions, along with the parameterized modeling scripts, rendered images, and 3D model files, are fully aligned to construct SldprtNet. To assess its effectiveness, we fine-tuned baseline models on a dataset subset, comparing image-plus-text inputs with text-only inputs. Results confirm the necessity and value of multimodal datasets for CAD generation. It features carefully selected real-world industrial parts, supporting tools for scalable dataset expansion, diverse modalities, and ensured diversity in model complexity and geometric features, making it a comprehensive multimodal dataset built for semantic-driven CAD modeling and cross-modal learning.
Tactile Functasets: Neural Implicit Representations of Tactile Datasets
Sep 22, 2024
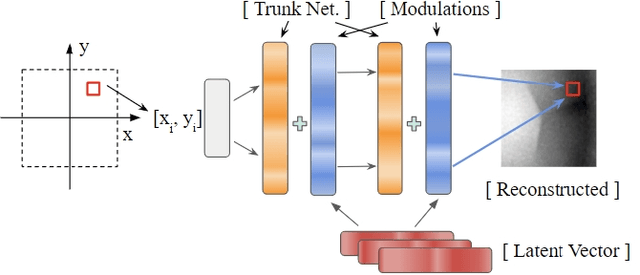


Modern incarnations of tactile sensors produce high-dimensional raw sensory feedback such as images, making it challenging to efficiently store, process, and generalize across sensors. To address these concerns, we introduce a novel implicit function representation for tactile sensor feedback. Rather than directly using raw tactile images, we propose neural implicit functions trained to reconstruct the tactile dataset, producing compact representations that capture the underlying structure of the sensory inputs. These representations offer several advantages over their raw counterparts: they are compact, enable probabilistically interpretable inference, and facilitate generalization across different sensors. We demonstrate the efficacy of this representation on the downstream task of in-hand object pose estimation, achieving improved performance over image-based methods while simplifying downstream models. We release code, demos and datasets at https://www.mmintlab.com/tactile-functasets.
Think, Act, and Ask: Open-World Interactive Personalized Robot Navigation
Oct 12, 2023Zero-Shot Object Navigation (ZSON) enables agents to navigate towards open-vocabulary objects in unknown environments. The existing works of ZSON mainly focus on following individual instructions to find generic object classes, neglecting the utilization of natural language interaction and the complexities of identifying user-specific objects. To address these limitations, we introduce Zero-shot Interactive Personalized Object Navigation (ZIPON), where robots need to navigate to personalized goal objects while engaging in conversations with users. To solve ZIPON, we propose a new framework termed Open-woRld Interactive persOnalized Navigation (ORION), which uses Large Language Models (LLMs) to make sequential decisions to manipulate different modules for perception, navigation and communication. Experimental results show that the performance of interactive agents that can leverage user feedback exhibits significant improvement. However, obtaining a good balance between task completion and the efficiency of navigation and interaction remains challenging for all methods. We further provide more findings on the impact of diverse user feedback forms on the agents' performance.