 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFSA: Episodic Few-Shot Adaptation for Text-to-Image Retrieval
Nov 28, 2024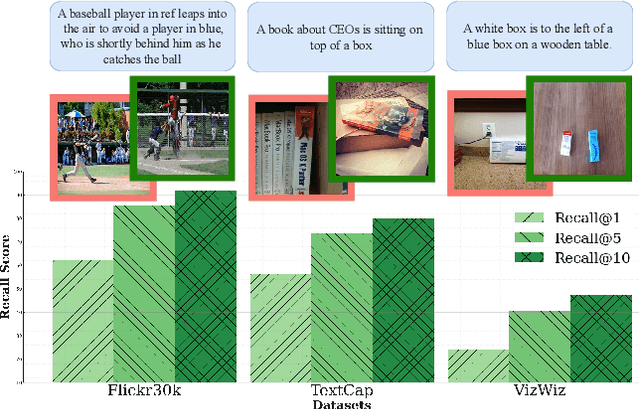



Text-to-image retrieval is a critical task for managing diverse visual content, but common benchmarks for the task rely on small, single-domain datasets that fail to capture real-world complexity. Pre-trained vision-language models tend to perform well with easy negatives but struggle with hard negatives--visually similar yet incorrect images--especially in open-domain scenarios. To address this, we introduce Episodic Few-Shot Adaptation (EFSA), a novel test-time framework that adapts pre-trained models dynamically to a query's domain by fine-tuning on top-k retrieved candidates and synthetic captions generated for them. EFSA improves performance across diverse domains while preserving generalization, as shown in evaluations on queries from eight highly distinct visual domains and an open-domain retrieval pool of over one million images. Our work highlights the potential of episodic few-shot adaptation to enhance robustness in the critical and understudied task of open-domain text-to-image retrieval.
Towards Energy-Efficiency by Navigating the Trilemma of Energy, Latency, and Accuracy
Sep 06, 2024
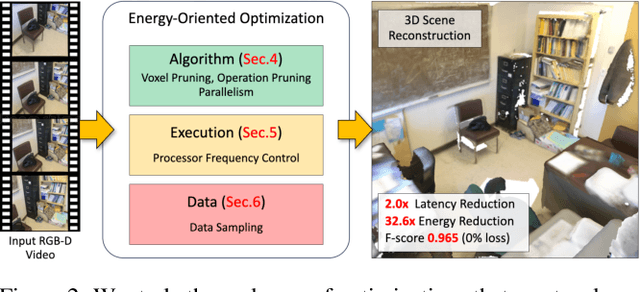
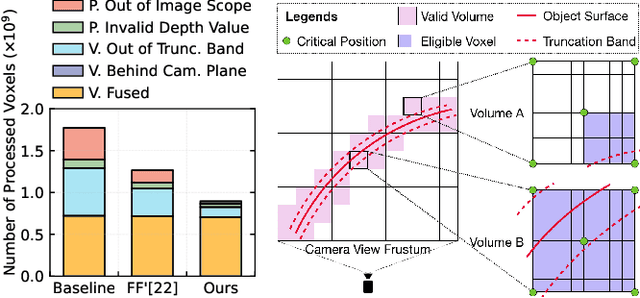
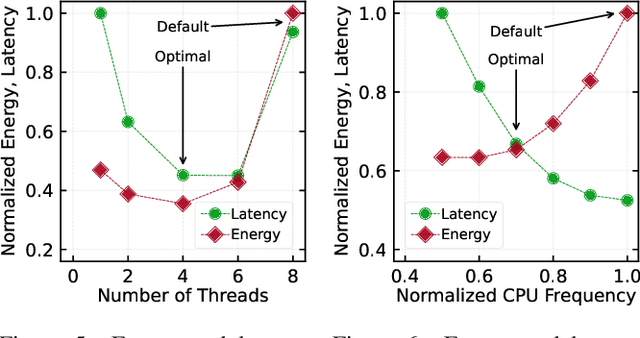
Extended Reality (XR) enables immersive experiences through untethered headsets but suffers from stringent battery and resource constraints. Energy-efficient design is crucial to ensure both longevity and high performance in XR devices. However, latency and accuracy are often prioritized over energy, leading to a gap in achieving energy efficiency. This paper examines scene reconstruction, a key building block for immersive XR experiences, and demonstrates how energy efficiency can be achieved by navigating the trilemma of energy, latency, and accuracy. We explore three classes of energy-oriented optimizations, covering the algorithm, execution, and data, that reveal a broad design space through configurable parameters. Our resulting 72 designs expose a wide range of latency and energy trade-offs, with a smaller range of accuracy loss. We identify a Pareto-optimal curve and show that the designs on the curve are achievable only through synergistic co-optimization of all three optimization classes and by considering the latency and accuracy needs of downstream scene reconstruction consumers. Our analysis covering various use cases and measurements on an embedded class system shows that, relative to the baseline, our designs offer energy benefits of up to 60X with potential latency range of 4X slowdown to 2X speedup. Detailed exploration of a use case across representative data sequences from ScanNet showed about 25X energy savings with 1.5X latency reduction and negligible reconstruction quality loss.
Test-Time Low Rank Adaptation via Confidence Maximization for Zero-Shot Generalization of Vision-Language Models
Jul 22, 2024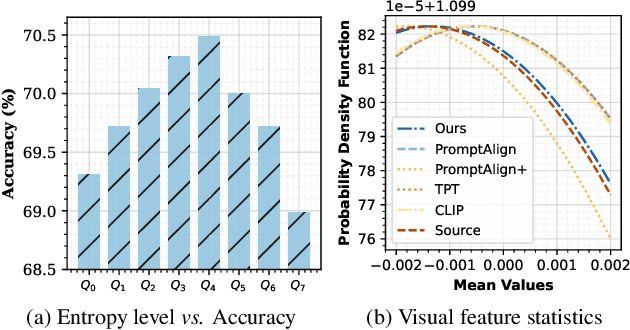

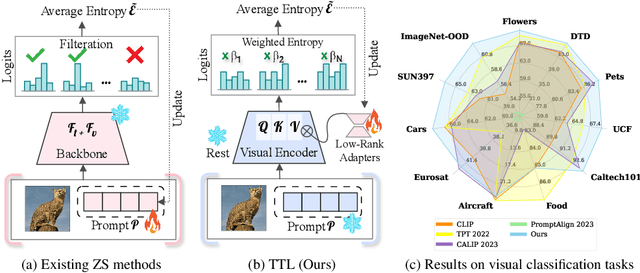
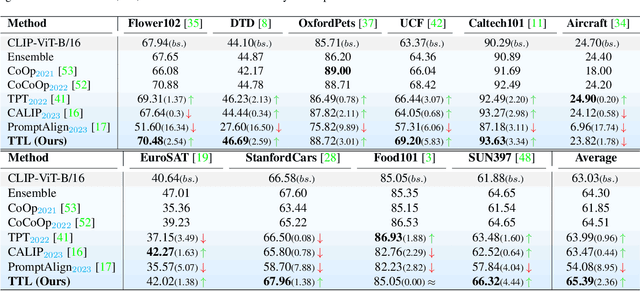
The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time involves tuning learnable prompts, ie, test-time prompt tuning. This paper introduces Test-Time Low-rank adaptation (TTL) as an alternative to prompt tuning for zero-shot generalization of large-scale VLMs. Taking inspiration from recent advancements in efficiently fine-tuning large language models, TTL offers a test-time parameter-efficient adaptation approach that updates the attention weights of the transformer encoder by maximizing prediction confidence. The self-supervised confidence maximization objective is specified using a weighted entropy loss that enforces consistency among predictions of augmented samples. TTL introduces only a small amount of trainable parameters for low-rank adapters in the model space while keeping the prompts and backbone frozen. Extensive experiments on a variety of natural distribution and cross-domain tasks show that TTL can outperform other techniques for test-time optimization of VLMs in strict zero-shot settings. Specifically, TTL outperforms test-time prompt tuning baselines with a significant improvement on average. Our code is available at at https://github.com/Razaimam45/TTL-Test-Time-Low-Rank-Adaptation.
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
Mar 15, 2024Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. This allows us to quantify the role of background context in understanding the robustness and generalization of deep neural networks. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.
Domain Adaptable Fine-Tune Distillation Framework For Advancing Farm Surveillance
Feb 10, 2024



In this study, we propose an automated framework for camel farm monitoring, introducing two key contributions: the Unified Auto-Annotation framework and the Fine-Tune Distillation framework. The Unified Auto-Annotation approach combines two models, GroundingDINO (GD), and Segment-Anything-Model (SAM), to automatically annotate raw datasets extracted from surveillance videos. Building upon this foundation, the Fine-Tune Distillation framework conducts fine-tuning of student models using the auto-annotated dataset. This process involves transferring knowledge from a large teacher model to a student model, resembling a variant of Knowledge Distillation. The Fine-Tune Distillation framework aims to be adaptable to specific use cases, enabling the transfer of knowledge from the large models to the small models, making it suitable for domain-specific applications. By leveraging our raw dataset collected from Al-Marmoom Camel Farm in Dubai, UAE, and a pre-trained teacher model, GroundingDINO, the Fine-Tune Distillation framework produces a lightweight deployable model, YOLOv8. This framework demonstrates high performance and computational efficiency, facilitating efficient real-time object detection. Our code is available at \href{https://github.com/Razaimam45/Fine-Tune-Distillation}{https://github.com/Razaimam45/Fine-Tune-Distillation}
On enhancing the robustness of Vision Transformers: Defensive Diffusion
May 14, 2023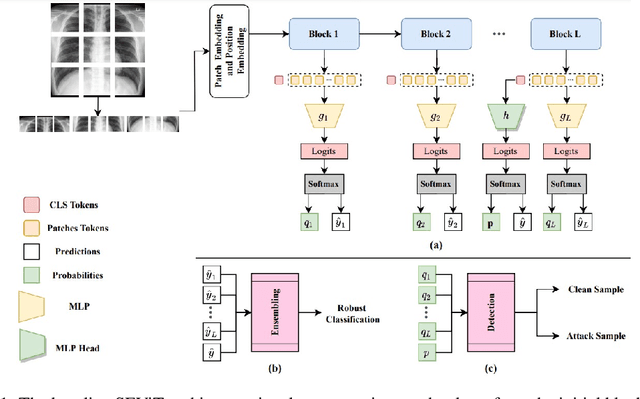



Privacy and confidentiality of medical data are of utmost importance in healthcare settings. ViTs, the SOTA vision model, rely on large amounts of patient data for training, which raises concerns about data security and the potential for unauthorized access. Adversaries may exploit vulnerabilities in ViTs to extract sensitive patient information and compromising patient privacy. This work address these vulnerabilities to ensure the trustworthiness and reliability of ViTs in medical applications. In this work, we introduced a defensive diffusion technique as an adversarial purifier to eliminate adversarial noise introduced by attackers in the original image. By utilizing the denoising capabilities of the diffusion model, we employ a reverse diffusion process to effectively eliminate the adversarial noise from the attack sample, resulting in a cleaner image that is then fed into the ViT blocks. Our findings demonstrate the effectiveness of the diffusion model in eliminating attack-agnostic adversarial noise from images. Additionally, we propose combining knowledge distillation with our framework to obtain a lightweight student model that is both computationally efficient and robust against gray box attacks. Comparison of our method with a SOTA baseline method, SEViT, shows that our work is able to outperform the baseline. Extensive experiments conducted on a publicly available Tuberculosis X-ray dataset validate the computational efficiency and improved robustness achieved by our proposed architecture.
On-Device CPU Scheduling for Sense-React Systems
Aug 14, 2022

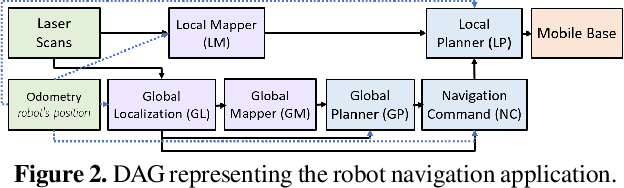
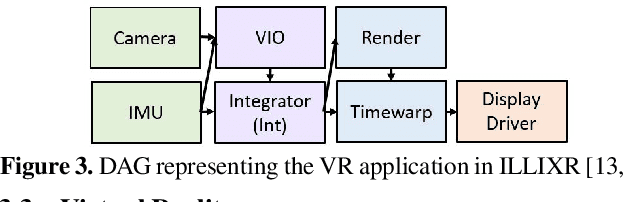
Sense-react systems (e.g. robotics and AR/VR) have to take highly responsive real-time actions, driven by complex decisions involving a pipeline of sensing, perception, planning, and reaction tasks. These tasks must be scheduled on resource-constrained devices such that the performance goals and the requirements of the application are met. This is a difficult scheduling problem that requires handling multiple scheduling dimensions, and variations in resource usage and availability. In practice, system designers manually tune parameters for their specific hardware and application, which results in poor generalization and increases the development burden. In this work, we highlight the emerging need for scheduling CPU resources at runtime in sense-react systems. We study three canonical applications (face tracking, robot navigation, and VR) to first understand the key scheduling requirements for such systems. Armed with this understanding, we develop a scheduling framework, Catan, that dynamically schedules compute resources across different components of an app so as to meet the specified application requirements. Through experiments with a prototype implemented on a widely-used robotics framework (ROS) and an open-source AR/VR platform, we show the impact of system scheduling on meeting the performance goals for the three applications, how Catan is able to achieve better application performance than hand-tuned configurations, and how it dynamically adapts to runtime variations.